scikit-learn 决策树 分类问题
1.Demo
from sklearn import tree
import pydotplus
import numpy as np
#李航p59表数据
#年龄,有工作,有自己房子,信贷情况,类别
#青年0 中年1 老年2
#否0 是1
#一般0 好1 非常好2
datasets = np.array([['', '', '', '', ''],
['', '', '', '', ''],
['', '', '', '', ''],
['', '', '', '', ''],
['', '', '', '', ''],
['', '', '', '', ''],
['', '', '', '', ''],
['', '', '', '', ''],
['', '', '', '', ''],
['', '', '', '', ''],
['', '', '', '', ''],
['', '', '', '', ''],
['', '', '', '', ''],
['', '', '', '', ''],
['', '', '', '', '']])
X = datasets[:,:4]
Y = datasets[:,4:5]
clf = tree.DecisionTreeClassifier()
clf.fit(X,Y)
dot_data = tree.export_graphviz(clf,out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("Tree.pdf")
生成的可视化的决策树
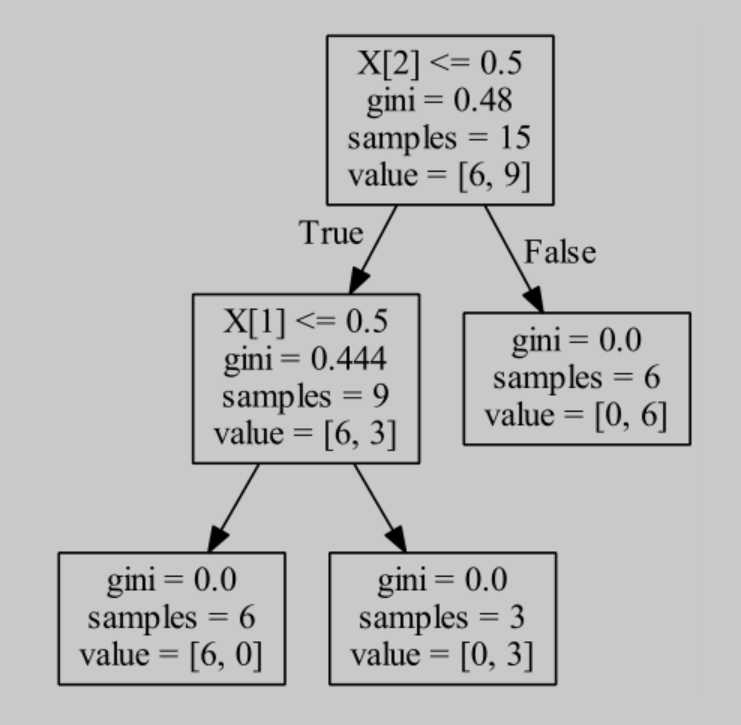
2.DecisionTreeClassifier
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, splitter=’best’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, class_weight=None, presort=False)
重要参数
criterion : string, optional (default=”gini”)
用来指定特征选择的方法,有"entropy"和"gini"两个选择
entropy指定用信息增益,使用ID3、C4.5算法
gini指定用基尼不纯度,使用CART决策树算法
splitter : string, optional (default=”best”)
用来指定怎么寻找最优划分点,有"best"和"random"两个选择
best指定在所有特征中找最优划分点
random指定在随机部分划分中找最优划分点
默认的"best"适合样本量不大的时候,而如果样本数据量非常大,此时决策树构建推荐"random"
max_depth : int or None, optional (default=None)
用来指定决策树的最大深度
通常将max_depth=3作为初始值,将数据可视化查看下拟合情况,在调整树的深度
通常用来解决过拟合问题
min_samples_split : int, float, optional (default=2)
用来指定子树划分条件
默认是2,当只有一个样本的时候,不在划分子树
当样本数很大时,才会考虑增加这个值
限制决策树增长,避免过拟合
min_samples_leaf : int, float, optional (default=1)
用来指定叶子节点包含的最少样本
当样本数很大时,才会考虑增加这个值
限制决策树增长,避免过拟合
scikit-learn 决策树 分类问题的更多相关文章
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- sklearn CART决策树分类
sklearn CART决策树分类 决策树是一种常用的机器学习方法,可以用于分类和回归.同时,决策树的训练结果非常容易理解,而且对于数据预处理的要求也不是很高. 理论部分 比较经典的决策树是ID3.C ...
- 决策树分类算法及python代码实现案例
决策树分类算法 1.概述 决策树(decision tree)——是一种被广泛使用的分类算法. 相比贝叶斯算法,决策树的优势在于构造过程不需要任何领域知识或参数设置 在实际应用中,对于探测式的知识发现 ...
- 用Python开始机器学习(2:决策树分类算法)
http://blog.csdn.net/lsldd/article/details/41223147 从这一章开始进入正式的算法学习. 首先我们学习经典而有效的分类算法:决策树分类算法. 1.决策树 ...
- python 之 决策树分类算法
发现帮助新手入门机器学习的一篇好文,首先感谢博主!:用Python开始机器学习(2:决策树分类算法) J. Ross Quinlan在1975提出将信息熵的概念引入决策树的构建,这就是鼎鼎大名的ID3 ...
- 机器学习之路:python 集成分类器 随机森林分类RandomForestClassifier 梯度提升决策树分类GradientBoostingClassifier 预测泰坦尼克号幸存者
python3 学习使用随机森林分类器 梯度提升决策树分类 的api,并将他们和单一决策树预测结果做出对比 附上我的git,欢迎大家来参考我其他分类器的代码: https://github.com/l ...
- R语言学习笔记—决策树分类
一.简介 决策树分类算法(decision tree)通过树状结构对具有某特征属性的样本进行分类.其典型算法包括ID3算法.C4.5算法.C5.0算法.CART算法等.每一个决策树包括根节点(root ...
随机推荐
- Redis数据持久化、数据备份、数据的故障恢复
1.redis持久化的意义----redis故障恢复 在实际的生产环境中,很可能会遇到redis突然挂掉的情况,比如redis的进程死掉了.电缆被施工队挖了(支付宝例子)等等,总之一定会遇到各种奇葩的 ...
- 跳跳棋[LCA+二分查找]-洛谷1852
传送门 这真是一道神仙题 虽然我猜到了这是一道LCA的题 但是... 第一遍看题,我是怎么也没想到能和树形图扯上关系 并且用上LCA 但其实其实和上一道lightoj上的那道题很类似 只不过那时一道很 ...
- 0.[Andriod]之从零安装配置Android Studio并编写第一个Android App
0. 所需的安装文件 笔者做了几年WP,近来对Android有点兴趣,尝试一下Android开发,废话不多说,直接进入主题,先安装开发环境,笔者的系统环境为windows8.1&x64. 安装 ...
- spring异常Unsatisfied dependency expressed through constructor parameter 0
异常信息: org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with nam ...
- Spring Security 无法登陆,报错:There is no PasswordEncoder mapped for the id “null”
编写好继承了WebSecurityConfigurerAdapter类的WebSecurityConfig类后,我们需要在configure(AuthenticationManagerBuilder ...
- Shell命令-系统信息及显示之uname、hostname
文件及内容处理 - uname.hostname 1. uname:显示系统信息 uname命令的功能说明 uname 命令用于显示系统信息.uname 可显示电脑以及操作系统的相关信息 uname命 ...
- P1836 【数页码_NOI导刊2011提高(04)】
P1836 数页码_NOI导刊2011提高(04) 题目描述 一本书的页码是从1—n编号的连续整数:1,2,3,…,n.请你求出全部页码中所有单个数字的和,例如第123页,它的和就是1+2+3=6. ...
- Jekins相关笔记
Jekins忘记密码操作 https://blog.csdn.net/intelrain/article/details/78749635 Jekins重启 https://www.cnblogs.c ...
- AtomicInteger学习
面试时被问到了,补下 import java.util.concurrent.atomic.AtomicInteger; /** * Created by tzq on 2018/7/15. */ p ...
- Tensorflow 大规模数据集训练方法
本文转自:Tensorflow]超大规模数据集解决方案:通过线程来预取 原文地址:https://blog.csdn.net/mao_xiao_feng/article/details/7399178 ...