Python爬虫之用Selenium做爬虫
我们在用python做爬虫的时候,除了直接用requests的架构,还有Scrapy、Selenium等方式可以使用,那么今天我们就来聊一聊使用Selenium如何实现爬虫。
Selenium是什么?
Selenium是一个浏览器自动化测试框架,是一款用于Web应用程序测试的工具。框架底层使用JavaScript模拟真实用户对浏览器进行操作。测试脚本执行时,浏览器自动按照脚本代码做出点击,输入,打开,验证等操作,就像真实用户所做的一样,从终端用户的角度测试应用程序。使浏览器兼容性测试自动化成为可能,尽管在不同的浏览器上依然有细微的差别。使用简单,可使用Java,Python等多种语言编写用例脚本。(百度百科)
如何使用Selenium?
首先下载Selenium这个库,pip install selenium。接着查看Selenium支持的浏览器,这里就使用都会有的chrome谷歌浏览器,如果想要查看能用什么浏览器可以使用下面这些代码,就可以看到支持的浏览器和版本:
from selenium import webdriver help(webdriver)
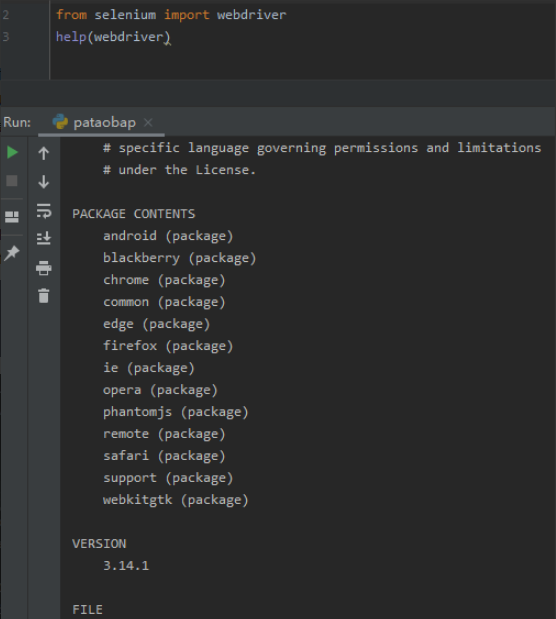
然后再对应着浏览器的版本找相应的浏览器驱动。
驱动的位置一定要放在没有中文字符的文件夹中,好这个地址,有用。
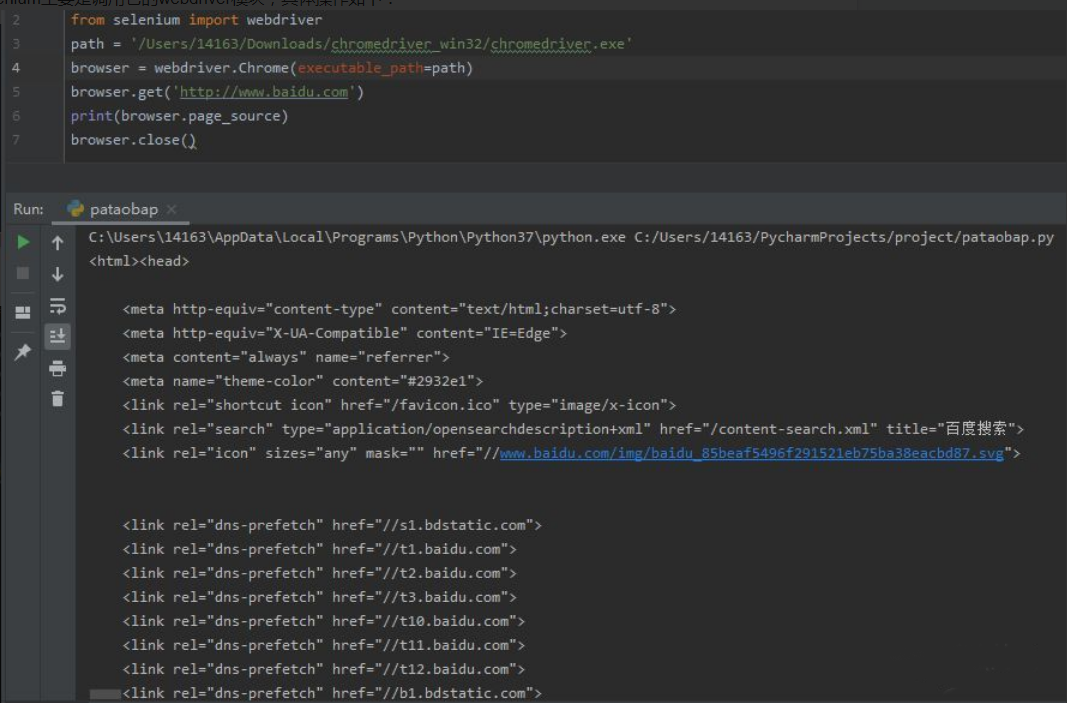
使用Selenium主要是调用它的webdriver模块,具体操作如下:
from selenium import webdriver
path = '/Users/14163/Downloads/chromedriver_win32/chromedriver.exe'#这里是保存的驱动的位置
browser = webdriver.Chrome(executable_path=path) #初始化驱动对象 browser.get('http://www.baidu.com') #获取url
print(browser.page_source) #输出获取到的文件数据
browser.close() #关闭浏览器
结果:
再对比一下requests获取的网页的数据:
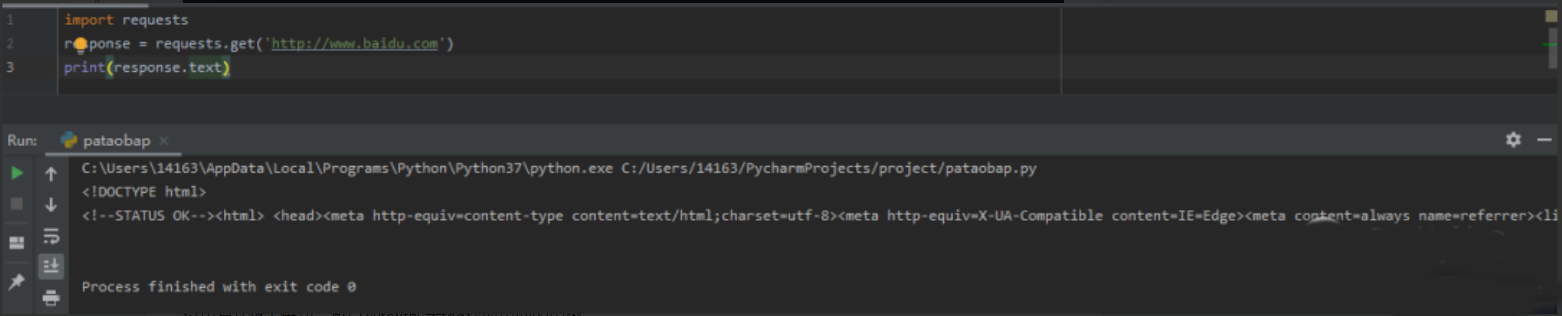
很明显selenium能获取得到的内容更多selenium有相应的函数去查找数据,单个元素的三种不同的方式去获取响应的元素,第一种是通过id的方式,第二个中是CSS选择器,第三种是xpath选择器,结果都是相同的。
这里是按id去查找,可以加text或者tag获取里面的内容。
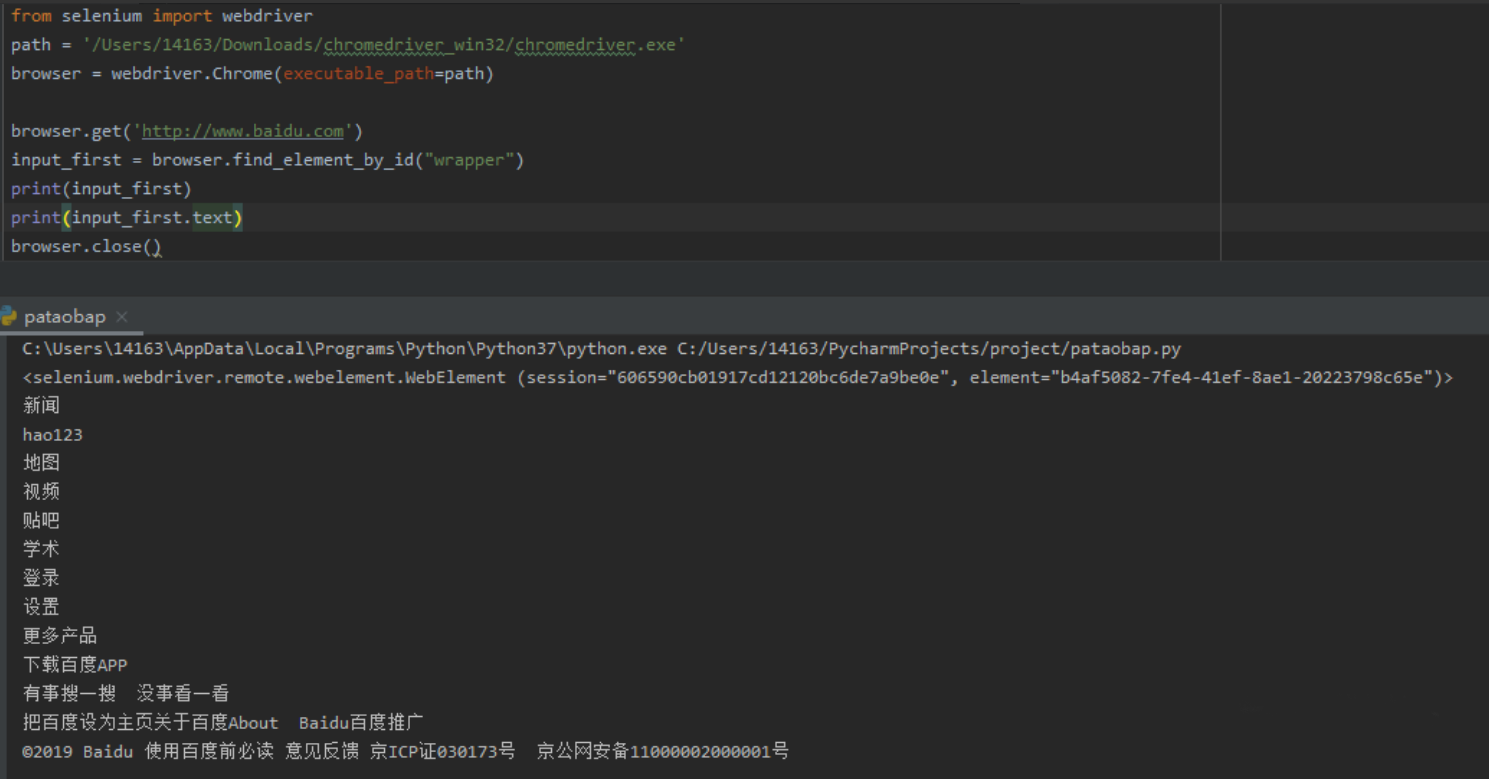
或者可以调用另一个库去获取id,By
先 导入库:
from selenium.webdriver.common.by import By
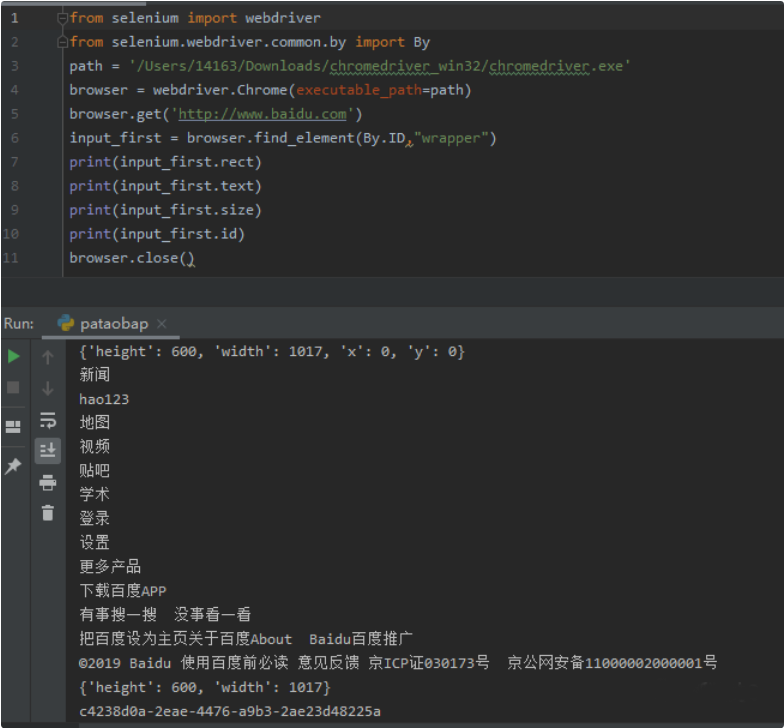
这样就可以获取网页的数据。
这些只是获取一个元素的,可以获取多个元素加用find_elements即可。
交互操作:
对网页进行操作,比如在百度的搜索框输入孤独的s,然后点击搜索就可以这样:
按以下代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
path = '/Users/14163/Downloads/chromedriver_win32/chromedriver.exe'
browser = webdriver.Chrome(executable_path=path)
browser.get('http://www.baidu.com')
input_first = browser.find_element(By.ID,"kw")
print(input_first)
input_first.send_keys("孤独")
time.sleep(0.1)
button = browser.find_element_by_class_name('s_btn_wr') #这里获取百度搜索的那个按钮
button.click()# 点击
结果:
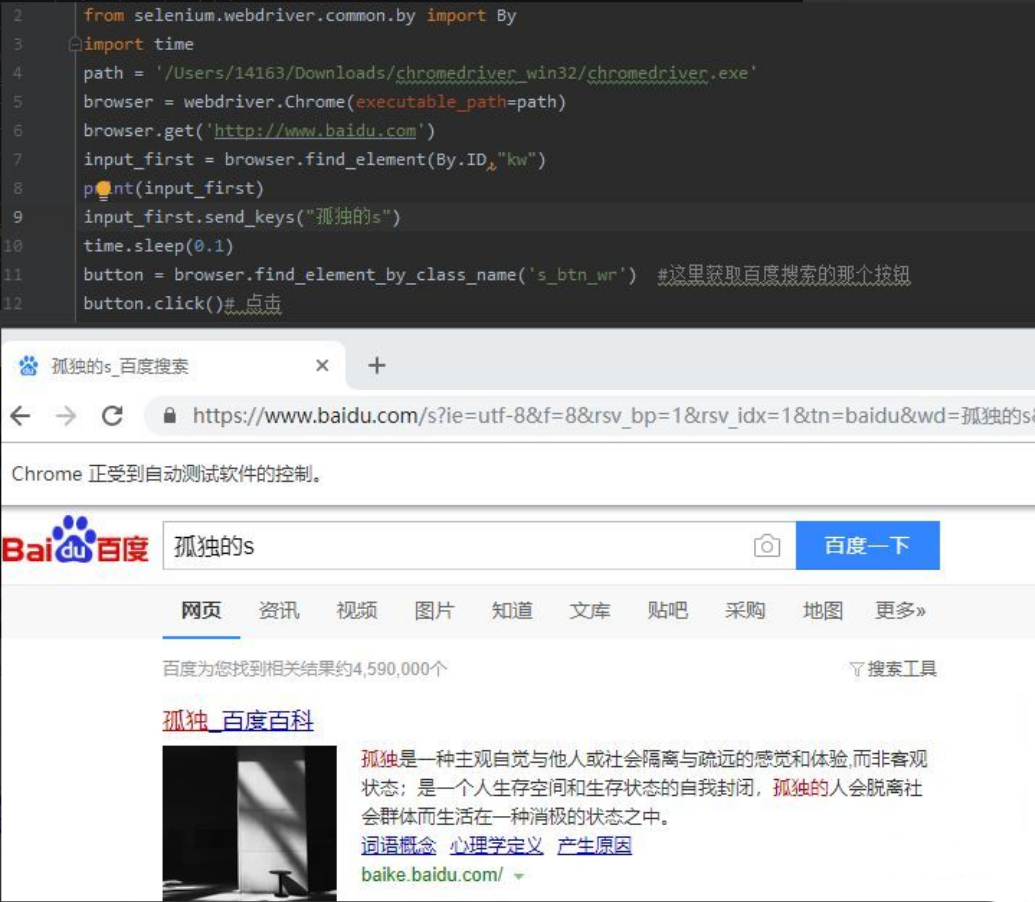
在chrome中想要找到对应的按钮的元素或者id,可以点击红圈这个,然后再去移动去原网页,就可以知道结果:

不得不说,selenium真便利。
Python爬虫之用Selenium做爬虫的更多相关文章
- selenium+phantomJS爬虫,适用于登陆限制强,点触验证码等一些场景
selenium是非常出名的自己主动化測试工具,多数场景是測试project师用来做自己主动化測试,可是相同selenium能够作为基本上模拟浏览器的工具,去爬取一些基于http request不能或 ...
- python爬虫动态html selenium.webdriver
python爬虫:利用selenium.webdriver获取渲染之后的页面代码! 1 首先要下载浏览器驱动: 常用的是chromedriver 和phantomjs chromedirver下载地址 ...
- PYTHON 爬虫笔记七:Selenium库基础用法
知识点一:Selenium库详解及其基本使用 什么是Selenium selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及运行(Selenium ...
- Python爬虫之设置selenium webdriver等待
Python爬虫之设置selenium webdriver等待 ajax技术出现使异步加载方式呈现数据的网站越来越多,当浏览器在加载页面时,页面上的元素可能并不是同时被加载完成,这给定位元素的定位增加 ...
- 小白学 Python 爬虫(40):爬虫框架 Scrapy 入门基础(七)对接 Selenium 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- Python3.0版本 从听说python可以做爬虫到自己第一成功做出爬虫的经历
前言 我自己是个python小白,工作也不是软件行业,但是日常没事时喜欢捣鼓一些小玩意,自身有点C语言基础. 听说python很火,可以做出爬虫去爬一些数据图片视频之类的东东,我的兴趣一下子就来了.然 ...
- Python使用selenium进行爬虫(一)
JAVA爬虫框架很多,类似JSOUP,WEBLOGIC之类的爬虫框架都十分好用,个人认为爬虫的大致思路就是: 1.挑选需求爬的URL地址,将其放入需求网络爬虫的队列,也可以把爬到的符合一定需求的地址放 ...
- (转)Python新手写出漂亮的爬虫代码2——从json获取信息
https://blog.csdn.net/weixin_36604953/article/details/78592943 Python新手写出漂亮的爬虫代码2——从json获取信息好久没有写关于爬 ...
- (转)Python新手写出漂亮的爬虫代码1——从html获取信息
https://blog.csdn.net/weixin_36604953/article/details/78156605 Python新手写出漂亮的爬虫代码1初到大数据学习圈子的同学可能对爬虫都有 ...
- 小白学 Python 爬虫(9):爬虫基础
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- Codeforces Round #843 (Div. 2) C【思维】
https://codeforces.com/contest/1775/problem/C 题意 题意是说,给你n和x,你要求出最小的满足要求的m,使得 \(n\)&\((n+1)\)& ...
- .netcore webapi的返回值和过滤器
1.返回值. 1.1直接返回数据 1.2 数据+状态码 返回这种类型IActionResult 可以使用return OK(T).return NotFound(T) 1.3前两种的混合使用Actio ...
- TexturePacker基本使用
生成后
- java抽象类继承抽象类和抽象方法 java抽象类继承抽象类和抽象方法
抽象类除了不能实例化对象之外,类的其它功能依然存在,成员变量.成员方法和构造方法的访问方式和普通类一样. 由于抽象类不能实例化对象,所以抽象类必须被继承,才能被使用.也是因为这个原因,通常在设计阶段决 ...
- 大二下学期开学java测试
我们在2月13日下午进行了java测试(是一个新闻类型的题),通过这一个测试我进行了以下总结: 我对于javaweb的框架构建和加密密码,还有一些不同人物功能的实现,使得我在这次得考试中成绩不太理想. ...
- 2022.3.9内部群每日三题-清辉PMP
1.项目经理集合在地理上分散的团队,为一家组织实施新的强制性监管要求.若要获得该相关方的承诺,项目经理应该怎么做? A.设置必要的沟通基础设施 B.召开项目启动大会 C.执行相关方分析 D.让团队集中 ...
- jmeter非GUI模式压测并生成测试报告
关于jmeter非GUI模式压测并生成测试报告 1.脚本调通后,在DOS命令栏进入脚本存在的位置 如果不想通过DOS进入脚本路径,则可以直接指定执行路径,命令如下: JMeter默认去当前目录寻找脚本 ...
- 攻防世界Web篇——PHP2
可以从index.phps中找到网站源码 从源码中得出,要满足admin!=$_GET[id],urldecode($_GET[id]) == admin,两个条件才能得到flag 所以就将admin ...
- c# HttpServer 的使用
在很多的时候,我们写的应用程序需要提供一个信息说明或者告示功能,希望借助于HttpServer来发布一个简单的网站功能,但是又不想架一个臃肿的Http服务器功能, 这时候,标准框架提供的HttpSer ...
- python路径
#1.获取默认路径import os print (os.path.abspath('.')) my_path = os.path.abspath('.') #2.读取数据 my_data = pd. ...