Python3.0版本 从听说python可以做爬虫到自己第一成功做出爬虫的经历
前言
我自己是个python小白,工作也不是软件行业,但是日常没事时喜欢捣鼓一些小玩意,自身有点C语言基础。
听说python很火,可以做出爬虫去爬一些数据图片视频之类的东东,我的兴趣一下子就来了。然后,开始了不归路,各种百度,各种实验。。。
最终的代码环境是安装了python 3.7,安装了PyCharm代码工具,别问我为啥选PyCharm,我也不知道,用着非常顺手不是吗。
当我开始写代码时,找了好多帖子去借鉴尝试,发现python2.0和3.0语法,所用模块等不一样,所以先说好,这个随笔的python版本是3.7的,不属于2.0版本。
这次爬虫的网站是百度贴吧,壁纸吧里的图片,可以打开下面的网址,然后随意选个帖子。
https://tieba.baidu.com/f?ie=utf-8&kw=%E5%A3%81%E7%BA%B8&fr=search
先说下写爬虫的步骤:1.发送网页请求 2.获取响应内容 3.解析网页内容 4.保存数据
第一步是发送请求和响应内容这两个最基本的操作:
要用到urllib.request这个模块,直接开头import就好,python自带的,上代码:
#! /usr/bin/env python
# -*- coding: utf-8 -*-
import re,os,urllib.request,datetime #url='https://tieba.baidu.com/p/6091256278'
def open_url(url):
req=urllib.request.Request(url)
req.add_header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64)AppleWebKit/537.36 (KHTML, like Gecko)\
Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0")
response=urllib.request.urlopen(req).read()
return response
#print(open_url(url))
请忽略import的其他模块,下面再讲。这个请求非常标准了,模拟用户的请求,所有的爬虫都适用。add.header函数模拟了用户,防止服务器拒绝请求。
复制这段,去掉第5,第12行的#号,可以运行处结果。结果如下:
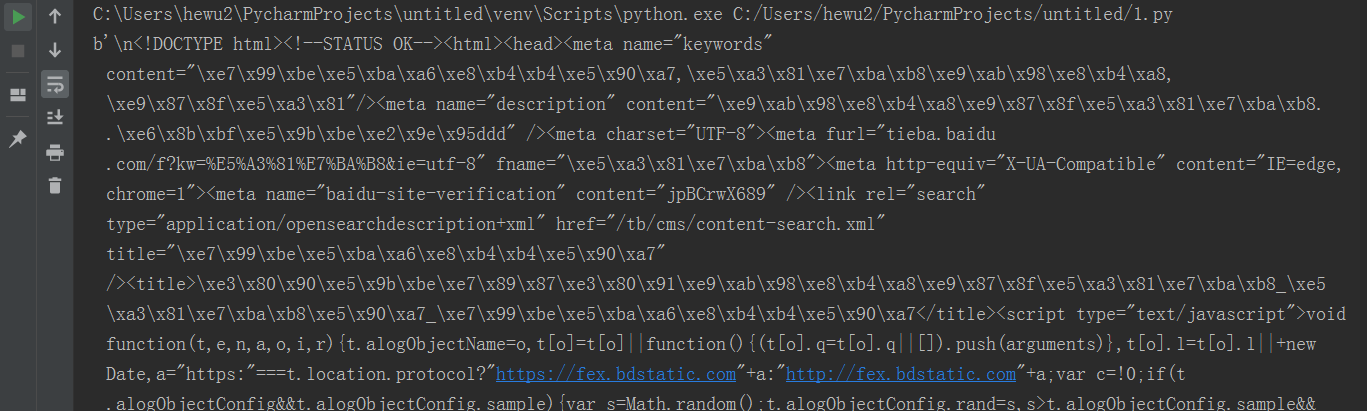
恩,没错就是这一堆乱码“源代码”。这是跟你在浏览器右键然后查看源代码的结果是一样的,只是这个更原始,没有转码,转码后会有汉字,稍微认识几个,但是也看不懂。
第二步说解析内容,这个比较重要,又非常复杂难懂的操作,上代码:
这里用到了re,os模块,之前import过的,文件操作模块,有兴趣百度多了解下,我也只是用能用到的几个函数。
def find_img(url):
html=open_url(url).decode('utf-8')
p=r'<img class="BDE_Image" src="([^"]+\.jpg)"'
img_addrs=re.findall(p,html) for each in img_addrs:
print(each)
for each in img_addrs:
file=each.split("/")[-1]
with open(file,"wb") as f:
img=open_url(each)
f.write(img)
第2行是源代码utf-8解码,结果是会有汉字,没有符号乱码了。
第3行是正则表达式,这是复杂的关键点,这个正则也是网络里找到的,用来匹配图片的地址,不多说,也说不出来,百度一下会教你如何放弃学习它,除非你是大神。
接着finall函数,在html的源代码里找符合正则表达式图片的网络地址,然后就是遍历下载下来。
最后一步使用with..open..as模式下载图片,放到文件夹里。
这里用到了datetime模块,用来获得系统的时间,然后我稍作处理一下,来以时间命名文件夹的名字,
def get_img():
t1 = str(datetime.datetime.now())
t = t1.replace(":", "-").replace(" ", "-")[0:19]
p = "D:\TieBaPic-" + t
os.mkdir(p)
os.chdir(p)
find_img(url)
单独运行第2,3,4行,得到结果是:在D盘生成一个名字如下的文件夹,里面就是上一步下载的图片,名字会根据时间来定,不会重复。
D:\TieBaPic-2019-04-11-16-50-33
第5,6行用到了os模块的两个函数,用来组合建立文件夹。
最后加上启动语句,就可以尝试爬虫了。
if __name__ =="__main__":
url='https://tieba.baidu.com/p/6091256278'
get_img()
这个双下划线的name函数,是一个变量,用来执行本程序的main,区别于import的模块,只有主程序是main,其他的都是导入的名字,并且
main是调用其他模块的关系,理解就行,没那么多讲究。
把所有的代码串起来就是完整的代码,运行结果如下:

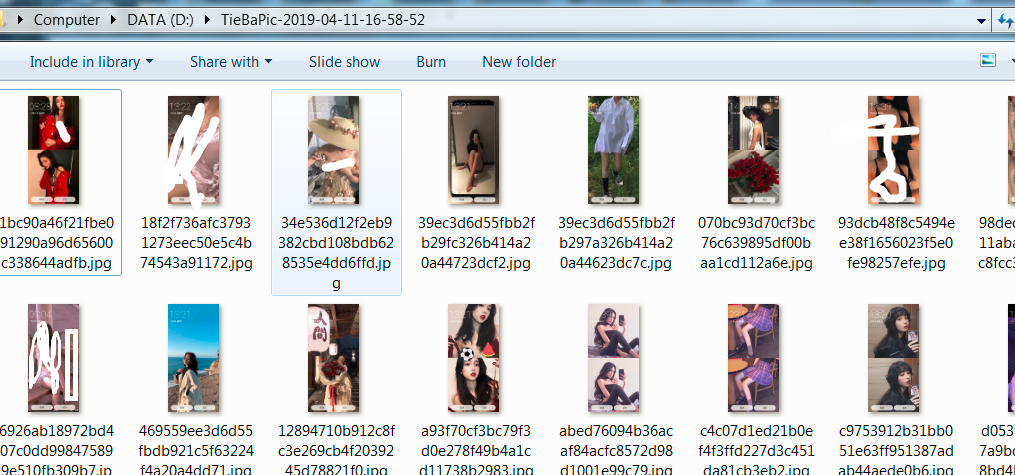
有些图片不太适合我们好学的氛围就P掉了。
以上就是我第一次的爬虫全过程,成功的爬出了图片,心里还是美滋滋的。
现在正在着手给python加个界面运行,等好了,发个随笔记录一下。
Python3.0版本 从听说python可以做爬虫到自己第一成功做出爬虫的经历的更多相关文章
- Python3.0 调用HTMLTestRunner生成的报告中不能显示用例中print函数的输出
官方原生的HTMLTestRunner.py支持python2.0版本,python3.0版本的使用需要做一些修改: Python3调用HTMLTestRunner执行用例生成测试报告中,不能正常显示 ...
- Python3笔记001 - 1.1 python概述
第1章 认识python python语言特点 跨平台 开源的 解释型 面向对象 python语言的特点是:以对象为核心组织代码,支持多种编程范式,采用动态类型,自动进行内存回收,并能调用C语言库进行 ...
- HTMLTestRunner修改Python3的版本
在拜读虫师大神的Selenium2+Python2.7时,发现生成HTMLTestRunner的测试报告使用的HTMLTestRunner的模块是用的Python2的语法.而我本人比较习惯与Pytho ...
- Python的简介以及安装和第一个程序以及用法
Python的简介: 1.Python是一种解释型.面向对象.动态数据类型的高级程序设计语言.自从20世纪90年代初Python语言诞生至今,它逐渐被广泛应用于处理系统管理任务和Web编程.Pytho ...
- 【和我一起学Python吧】Python3.0与2.X版本的区别
做为一个前端开发的码农,却正在阅读最新版的<A byte of Python>.发现Python3.0在某些地方还是有些改变的.准备慢慢的体会,与老版本的<A byte of Pyt ...
- python改成了python3的版本,那么这时候yum就出问题了
既然把默认python改成了python3的版本,那么这时候yum就出问题了,因为yum貌似不支持python3,开发了这个命令的老哥也不打算继续写支持python3的版本了,所以,如果和python ...
- Element-ui 2.8.0版本中提升表格性能,做了哪些事情,原理是什么
背景 项目中一直用element-ui,之前用el-table的时候,发现表格数据较多时,滑动表格就会很卡.我们的表格中只有200行数据,每行大概有30的字段,表格滑动就卡的不行.在Element-u ...
- 你都用python来做什么?
首页发现话题 提问 你都用 Python 来做什么? 关注问题写回答 编程语言 Python 编程 Python 入门 Python 开发 你都用 Python 来做什么? 发现很 ...
- python3.0笔记
python文件头 #!/usr/bin/env python # -*- coding: utf- -*- ''' Created on 2017年5月9日 @author: Administrat ...
随机推荐
- html 图片拖动不出来的脚本
function imgdragstart() { return false; } $(function(){ for (i in document.images) document.images[i ...
- Windows环境下搭建MosQuitto服务器
Windows环境下搭建MosQuitto服务器 2018年04月16日 22:00:01 wistronpj 阅读数:1185 摘自:https://blog.csdn.net/pjlxm/art ...
- tomcat端口作用
<Server port="8005" shutdown="SHUTDOWN"> <Connector port="8080&q ...
- vue项目引入第三方js插件,单个js文件引入成功,使用该插件方法时报错(问题已解决)
1.引入第三方js文件,npm安装不了 2.控制台显示引入成功 3.在methods下使用 图片看不清请看下面代码 updateTime() { setInterval(()=>{ var cd ...
- phpstury 升级mysql5.7
今天在往本地导数据表的时候老是报错: [Err] 1294 - Invalid ON UPDATE clause for '字段名' column 报错的数据表字段: `字段名` datetime D ...
- [Selenium With C#基础教程] Lesson-05 文本框
作者:Surpassme 来源:http://www.jianshu.com/p/7dca7d0d1ea3 声明:本文为原创文章,如需转载请在文章页面明显位置给出原文链接,谢谢. 文本框在Web页面中 ...
- CentOS7安装confluenceWIKI并破解汉化
关闭防火墙和selinux 开始搭建Wiki前,需要下载一些软件包. wget https://www.atlassian.com/software/confluence/downloads/bi ...
- js防windos锁屏功能实现
<li class="layui-nav-item"> <a href="javascript:;" id="lock"& ...
- New Year, New Devs: Sharpen your C# Skills
At the beginning of each new year, many people take on a challenge to learn something new or commit ...
- Java Integer为代表的包装类
Java种的Integer是int的包装类型 1. Integer 是int的包装类型,数据类型是类,初值为null 2. 初始化时 int i = 1; Integer i = new Intege ...