python数据分析与挖掘实战————银行分控模型(几种算法模型的比较)
一、神经网络算法:
1 import pandas as pd
2 from keras.models import Sequential
3 from keras.layers.core import Dense, Activation
4 import numpy as np
5 # 参数初始化
6 inputfile = 'C:/Users/76319/Desktop/bankloan.xls'
7 data = pd.read_excel(inputfile)
8 x_test = data.iloc[:,:8].values
9 y_test = data.iloc[:,8].values
10 inputfile = 'C:/Users/76319/Desktop/bankloan.xls'
11 data = pd.read_excel(inputfile)
12 x_test = data.iloc[:,:8].values
13 y_test = data.iloc[:,8].values
14
15 model = Sequential() # 建立模型
16 model.add(Dense(input_dim = 8, units = 8))
17 model.add(Activation('relu')) # 用relu函数作为激活函数,能够大幅提供准确度
18 model.add(Dense(input_dim = 8, units = 1))
19 model.add(Activation('sigmoid')) # 由于是0-1输出,用sigmoid函数作为激活函数
20 model.compile(loss = 'mean_squared_error', optimizer = 'adam')
21 # 编译模型。由于我们做的是二元分类,所以我们指定损失函数为binary_crossentropy,以及模式为binary
22 # 另外常见的损失函数还有mean_squared_error、categorical_crossentropy等,请阅读帮助文件。
23 # 求解方法我们指定用adam,还有sgd、rmsprop等可选
24 model.fit(x_test, y_test, epochs = 1000, batch_size = 10)
25 predict_x=model.predict(x_test)
26 classes_x=np.argmax(predict_x,axis=1)
27 yp = classes_x.reshape(len(y_test))
28
29 def cm_plot(y, yp):
30 from sklearn.metrics import confusion_matrix
31 cm = confusion_matrix(y, yp)
32 import matplotlib.pyplot as plt
33 plt.matshow(cm, cmap=plt.cm.Greens)
34 plt.colorbar()
35 for x in range(len(cm)):
36 for y in range(len(cm)):
37 plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center')
38 plt.ylabel('True label')
39 plt.xlabel('Predicted label')
40 return plt
41 cm_plot(y_test,yp).show()# 显示混淆矩阵可视化结果
42 score = model.evaluate(x_test,y_test,batch_size=128) # 模型评估
43 print(score)
结果以及混淆矩阵可视化如下:
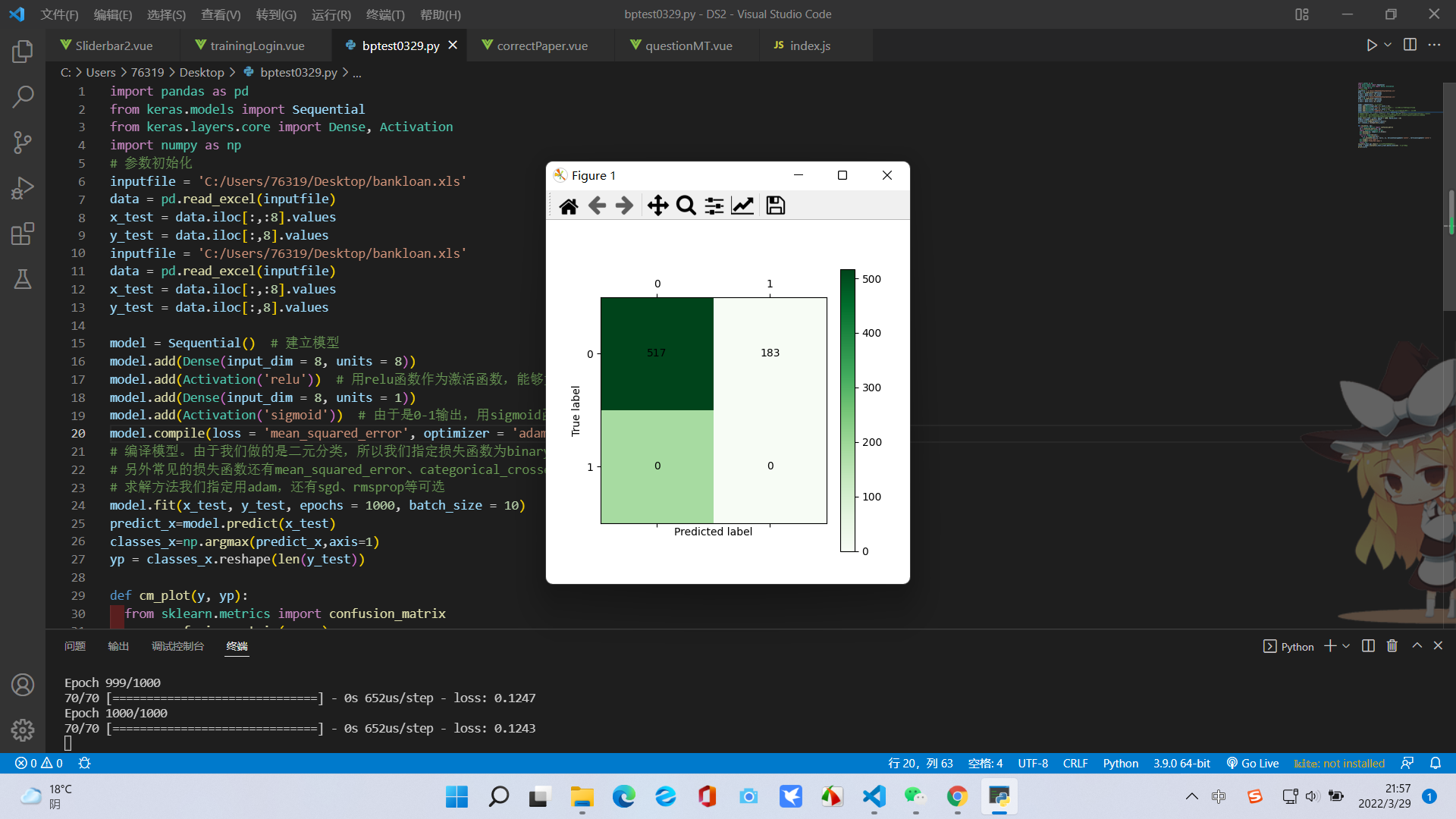
二、然后我们使用逻辑回归模型进行分析和预测:
import pandas as pd
inputfile = 'C:/Users/76319/Desktop/bankloan.xls'
data = pd.read_excel(inputfile)
print (data.head())
X = data.drop(columns='违约')
y = data['违约']
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1) model = LogisticRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(y_pred)
from sklearn.metrics import accuracy_score
score = accuracy_score(y_pred, y_test)
print(score)
def cm_plot(y, y_pred):
from sklearn.metrics import confusion_matrix #导入混淆矩阵函数
cm = confusion_matrix(y, y_pred) #混淆矩阵
import matplotlib.pyplot as plt #导入作图库
plt.matshow(cm, cmap=plt.cm.Greens) #画混淆矩阵图,配色风格使用cm.Greens,更多风格请参考官网。
plt.colorbar() #颜色标签
for x in range(len(cm)): #数据标签
for y in range(len(cm)):
plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True label') #坐标轴标签
plt.xlabel('Predicted label') #坐标轴标签
return plt
cm_plot(y_test, y_pred)
结果如下:
综上所述得出,两种算法模型总体上跑出来的准确率还是不错的,但是神经网络准确性更高一点。
python数据分析与挖掘实战————银行分控模型(几种算法模型的比较)的更多相关文章
- 学习参考《Python数据分析与挖掘实战(张良均等)》中文PDF+源代码
学习Python的主要语法后,想利用python进行数据分析,感觉<Python数据分析与挖掘实战>可以用来学习参考,理论联系实际,能够操作数据进行验证,基础理论的内容对于新手而言还是挺有 ...
- python数据分析与挖掘实战第二版pdf-------详细代码与实现
[书名]:PYTHON数据分析与挖掘实战 第2版[作者]:张良均,谭立云,刘名军,江建明著[出版社]:北京:机械工业出版社[时间]:2020[页数]:340[isbn]:9787111640028 学 ...
- 【读书笔记与思考】《python数据分析与挖掘实战》-张良均
[读书笔记与思考]<python数据分析与挖掘实战>-张良均 最近看一些机器学习相关书籍,主要是为了拓宽视野.在阅读这本书前最吸引我的地方是实战篇,我通读全书后给我印象最深的还是实战篇.基 ...
- python数据分析与挖掘实战
<python数据分析与挖掘实战>PDF&源代码&张良均 下载:链接:https://pan.baidu.com/s/1TYb3WZOU0R5VbSbH6JfQXw提取码: ...
- python 数据分析与挖掘实战01
python 数据分析与挖掘实战 day 01 08/02 这种从数据中"淘金",从大量数据包括文本中挖掘出隐含的.未知的.对决策有潜在价值关系.模式或者趋势,并用这些知识和规则建 ...
- 《Python数据分析与挖掘实战》读书笔记
大致扫了一遍,具体的代码基本都没看了,毕竟我还不懂python,并且在手机端的排版,这些代码没法看. 有收获,至少了解到以下几点: 一. Python的语法挺有意思的 有一些类似于JavaSc ...
- 《Python数据分析与挖掘实战》-第四章-数据预处理
点我看原版
- Python数据分析与挖掘所需的Pandas常用知识
Python数据分析与挖掘所需的Pandas常用知识 前言Pandas基于两种数据类型:series与dataframe.一个series是一个一维的数据类型,其中每一个元素都有一个标签.series ...
- R学习:《R语言数据分析与挖掘实战》PDF代码
分三个部分:基础篇.实战篇.提高篇.基础篇介绍了数据挖掘的基本原理,实战篇介绍了一个个真实案例,通过对案例深入浅出的剖析,使读者在不知不觉中通过案例实践获得数据挖掘项目经验,同时快速领悟看似难懂的数据 ...
随机推荐
- 手把手教你在命令行(静默)部署oracle 11gR2
文章目录 环境介绍 linux发行版 cpu.内存以及磁盘空间 敲黑板 关闭防火墙以及selinux 操作系统配置 使用阿里的yum源提速 安装依赖软件 设置用户最大进程数以及最大文件打开数 内核参数 ...
- 科普IIS是什么?IIS介绍!
1.Microsoft IIS 是允许在公共Intranet或Internet上发布信息的Web服务器.Internet Information Server通过运用超文本传输协议(HTTP)传输信息 ...
- spring IOC的理解,原理与底层实现?
从总体到局部 总 控制反转:理论思想,原来的对象是由使用者来进行控制,有了spring之后,可以把整个对象交给spring来帮我们进行管理 DI(依赖注入):把对应的属性 ...
- 【程序员的实用工具推荐】 Mac 效率神器 Alfred
Alfred 是一款功能非常强大,能有效提升 Mac 电脑使用效率的神器.可以说有了 Alfred 你就基本上可以脱离鼠标实现各种操作.相比 Mac 自带的聚焦搜索,完全可以称得上拥有碾压性的优势. ...
- C语言中左值和右值的理解
左值顾名思义等号左边,右值等号右边. 左值一般指的内存占用的一个符号: 右值指的是常量或者常量表达式: 当然左值也可以通过一些常用的运算符,例如加减乘除/&转化为右值 注意:不是所有的变量都能 ...
- 信而泰IPv6协议一致性测试解决方案
信而泰IPv6协议一致性测试解决方案 背景 中国已经开始逐步进入万物互联的社会,相比原来的手机.电脑等接入网络,万物互联时代接入网络的智能终端会海量增加,而且在万物互联时代,网络的流量巨大,互联的 ...
- MySQL常用查询命令(单表查询)
查询语法如下: select... from... where... group by... (having)... order by...; 顺序是from (从指定表中) where (具体条件) ...
- csv/json/list/datatable导出为excel的通用模块设计
导出excel的场景我一般都是一个List直接导出成一张sheet,用Npoi.Mapper库很方便,最近我经常是需要将接口返回的jsonarray转成一张excel表,比如从elasticsearc ...
- Java:List(二)——List、ArrayList、LinkedList
List 模块:java.util.List 说明 List接口,表明一个序列 用法:List <E> ①直接用List承接一个ArrayList或LinkedList List < ...
- Phoenix使用
目录 Phoenix连接 Phoenix常用命令 表映射 视图映射 表映射 Phoenix二级索引 开启索引支持 全局索引 创建索引后 创建多条件索引后 本地索引 覆盖索引 总结 Phoenix JD ...