儿童节,和 AI 一起通关 “超级马里奥兄弟”
摘要:六一儿童节,快来训练一款自己的游戏 AI,用代码让马里奥从大反派酷霸王的魔掌里救回桃花公主。
本文分享自华为云社区《儿童节,和 AI 一起通关 “超级马里奥兄弟”》,作者:华为云社区精选。
在蘑菇王国,流传着这样一个故事:
某天,操纵着强力魔法的大乌龟酷霸王一族侵略了蘑菇们居住的和平王国。蘑菇一族都被酷霸王变成了岩石、砖块等形状,蘑菇王国即将灭亡。
只有蘑菇王国的桃花公主,才能解开魔法,让蘑菇们苏醒。
然而,她却被大魔王酷霸王所捉住。
为了打倒乌龟一族、救出桃花公主、给蘑菇王国带回和平,水管工马里奥决定站出来,向酷霸王发起挑战。
是的,这就是童年游戏《超级马里奥》的故事。
你是不是仍旧对马里奥这个游戏记忆犹新,是不是仍旧对过关焦头烂额,六一儿童节,快来训练一款自己的游戏 AI,用代码让马里奥从大反派酷霸王的魔掌里救回桃花公主。
当 AI 玩起超级马里奥
基于华为云一站式AI开发平台ModelArts,利用强化学习中的 PPO 算法来玩超级马里奥,对于绝大部分关卡,训练出来的 AI 智能体都可以在 1500 个 episode 内学会过关。
ModelArts 是面向开发者的一站式 AI 平台,支持海量数据预处理及交互式智能标注、大规模分布式训练、自动化模型生成,及端 - 边 - 云模型按需部署能力,可以让 AI 应用开发到商用部署缩短为分钟级别。
就算不懂代码,也可以按照教程案例,通过简单的调参,一步步实现游戏 AI 开发,成为超级马里奥闯关王者。
话不多说,先来看看实际的效果:

超级马里奥游戏 AI 的整体开发流程为:创建马里奥环境 -> 构建 PPO 算法 -> 训练 -> 推理 -> 可视化效果,目前可以在AI Gallery上免费体验。
AI Gallery 是在 ModelArts 的基础上构建的开发者生态社区, 支持算法、模型、数据集、Notebook 案例和技术文章的共享。
下面,童年回忆杀走起。
PPO 算法科普
因为这个游戏 AI 是基于 PPO 算法来训练的,所以先简单科普一下强化学习算法。PPO 算法有两种主要形式:PPO-Penalty 和 PPO-Clip (PPO2)。在这里,我们讨论 PPO-Clip(OpenAI 使用的主要形式)。 PPO 的主要特点如下:
- PPO 属于 on-policy 算法
- PPO 同时适用于离散和连续的动作空间
- 损失函数 PPO-Clip 算法最精髓的地方就是加入了一项比例用以描绘新老策略的差异,通过超参数 ϵ 限制策略的更新步长:
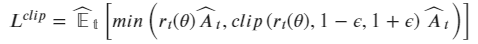
- 更新策略:
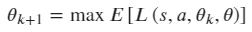
- 探索策略 PPO 采用随机探索策略。
- 优势函数 表示在状态 s 下采取动作 a,相较于其他动作有多少优势,如果 > 0, 则当前动作比平均动作好,反之,则差
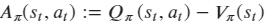
算法主要流程大致如下:
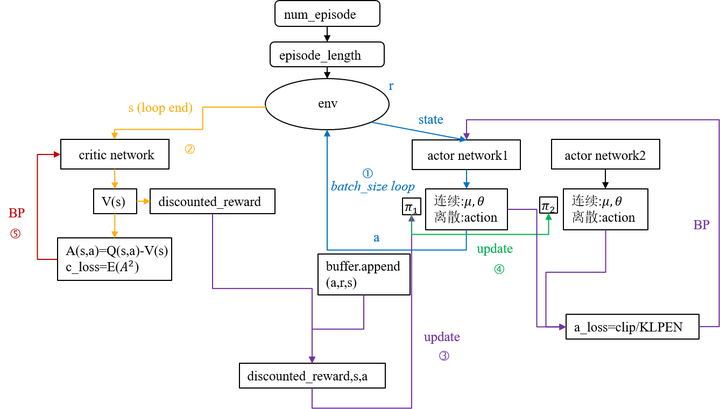
看起来有点复杂,不用担心,即便你不懂这些算法,有了华为云 ModelArts,可以跟着下面的步骤轻松实现超级马里奥游戏 AI 的强化学习。
开发步骤
本案例运行环境为 Pytorch-1.0.0,且需使用 GPU 运行,开始之前一定要选择对应的硬件规格。在 ModelArts Jupyter 中,只要点击代码前面的箭头,就能自动运行。
1. 程序初始化
第 1 步:安装基础依赖
!pip install -U pip
!pip install gym==0.19.0
!pip install tqdm==4.48.0
!pip install nes-py==8.1.0
!pip install gym-super-mario-bros==7.3.2
第 2 步:导入相关的库
import os
import shutil
import subprocess as sp
from collections import deque import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.multiprocessing as _mp
from torch.distributions import Categorical
import torch.multiprocessing as mp
from nes_py.wrappers import JoypadSpace
import gym_super_mario_bros
from gym.spaces import Box
from gym import Wrapper
from gym_super_mario_bros.actions import SIMPLE_MOVEMENT, COMPLEX_MOVEMENT, RIGHT_ONLY
import cv2
import matplotlib.pyplot as plt
from IPython import display import moxing as mox
2. 训练参数初始化
此处划重点,该部分参数可以自己调整,以训练出更好的效果。
opt={
"world": 1, # 可选大关:1,2,3,4,5,6,7,8
"stage": 1, # 可选小关:1,2,3,4
"action_type": "simple", # 动作类别:"simple","right_only", "complex"
'lr': 1e-4, # 建议学习率:1e-3,1e-4, 1e-5,7e-5
'gamma': 0.9, # 奖励折扣
'tau': 1.0, # GAE参数
'beta': 0.01, # 熵系数
'epsilon': 0.2, # PPO的Clip系数
'batch_size': 16, # 经验回放的batch_size
'max_episode':10, # 最大训练局数
'num_epochs': 10, # 每条经验回放次数
"num_local_steps": 512, # 每局的最大步数
"num_processes": 8, # 训练进程数,一般等于训练机核心数
"save_interval": 5, # 每{}局保存一次模型
"log_path": "./log", # 日志保存路径
"saved_path": "./model", # 训练模型保存路径
"pretrain_model": True, # 是否加载预训练模型,目前只提供1-1关卡的预训练模型,其他需要从零开始训练
"episode":5
}
如果你想选择其他关卡时,记得调整参数 world 和 stage ,这里默认的是第一关。
3. 创建环境
结束标志:
- 胜利:mario 到达本关终点
- 失败:mario 受到敌人的伤害、坠入悬崖或者时间用完
奖励函数:
- 得分:收集金币、踩扁敌人、结束时夺旗
- 扣分:受到敌人伤害、掉落悬崖、结束时未夺旗
# 创建环境
def create_train_env(world, stage, actions, output_path=None):
# 创建基础环境
env = gym_super_mario_bros.make("SuperMarioBros-{}-{}-v0".format(world, stage)) env = JoypadSpace(env, actions)
# 对环境自定义
env = CustomReward(env, world, stage, monitor=None)
env = CustomSkipFrame(env)
return env
# 对原始环境进行修改,以获得更好的训练效果
class CustomReward(Wrapper):
def __init__(self, env=None, world=None, stage=None, monitor=None):
super(CustomReward, self).__init__(env)
self.observation_space = Box(low=0, high=255, shape=(1, 84, 84))
self.curr_score = 0
self.current_x = 40
self.world = world
self.stage = stage
if monitor:
self.monitor = monitor
else:
self.monitor = None def step(self, action):
state, reward, done, info = self.env.step(action)
if self.monitor:
self.monitor.record(state)
state = process_frame(state)
reward += (info["score"] - self.curr_score) / 40.
self.curr_score = info["score"]
if done:
if info["flag_get"]:
reward += 50
else:
reward -= 50
if self.world == 7 and self.stage == 4:
if (506 <= info["x_pos"] <= 832 and info["y_pos"] > 127) or (
832 < info["x_pos"] <= 1064 and info["y_pos"] < 80) or (
1113 < info["x_pos"] <= 1464 and info["y_pos"] < 191) or (
1579 < info["x_pos"] <= 1943 and info["y_pos"] < 191) or (
1946 < info["x_pos"] <= 1964 and info["y_pos"] >= 191) or (
1984 < info["x_pos"] <= 2060 and (info["y_pos"] >= 191 or info["y_pos"] < 127)) or (
2114 < info["x_pos"] < 2440 and info["y_pos"] < 191) or info["x_pos"] < self.current_x - 500:
reward -= 50
done = True
if self.world == 4 and self.stage == 4:
if (info["x_pos"] <= 1500 and info["y_pos"] < 127) or (
1588 <= info["x_pos"] < 2380 and info["y_pos"] >= 127):
reward = -50
done = True self.current_x = info["x_pos"]
return state, reward / 10., done, info def reset(self):
self.curr_score = 0
self.current_x = 40
return process_frame(self.env.reset())
class MultipleEnvironments:
def __init__(self, world, stage, action_type, num_envs, output_path=None):
self.agent_conns, self.env_conns = zip(*[mp.Pipe() for _ in range(num_envs)])
if action_type == "right_only":
actions = RIGHT_ONLY
elif action_type == "simple":
actions = SIMPLE_MOVEMENT
else:
actions = COMPLEX_MOVEMENT
self.envs = [create_train_env(world, stage, actions, output_path=output_path) for _ in range(num_envs)]
self.num_states = self.envs[0].observation_space.shape[0]
self.num_actions = len(actions)
for index in range(num_envs):
process = mp.Process(target=self.run, args=(index,))
process.start()
self.env_conns[index].close() def run(self, index):
self.agent_conns[index].close()
while True:
request, action = self.env_conns[index].recv()
if request == "step":
self.env_conns[index].send(self.envs[index].step(action.item()))
elif request == "reset":
self.env_conns[index].send(self.envs[index].reset())
else:
raise NotImplementedError
def process_frame(frame):
if frame is not None:
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY)
frame = cv2.resize(frame, (84, 84))[None, :, :] / 255.
return frame
else:
return np.zeros((1, 84, 84))
class CustomSkipFrame(Wrapper):
def __init__(self, env, skip=4):
super(CustomSkipFrame, self).__init__(env)
self.observation_space = Box(low=0, high=255, shape=(skip, 84, 84))
self.skip = skip
self.states = np.zeros((skip, 84, 84), dtype=np.float32) def step(self, action):
total_reward = 0
last_states = []
for i in range(self.skip):
state, reward, done, info = self.env.step(action)
total_reward += reward
if i >= self.skip / 2:
last_states.append(state)
if done:
self.reset()
return self.states[None, :, :, :].astype(np.float32), total_reward, done, info
max_state = np.max(np.concatenate(last_states, 0), 0)
self.states[:-1] = self.states[1:]
self.states[-1] = max_state
return self.states[None, :, :, :].astype(np.float32), total_reward, done, info def reset(self):
state = self.env.reset()
self.states = np.concatenate([state for _ in range(self.skip)], 0)
return self.states[None, :, :, :].astype(np.float32)
4. 定义神经网络
神经网络结构包含四层卷积网络和一层全连接网络,提取的特征输入 critic 层和 actor 层,分别输出 value 值和动作概率分布。
class Net(nn.Module):
def __init__(self, num_inputs, num_actions):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(num_inputs, 32, 3, stride=2, padding=1)
self.conv2 = nn.Conv2d(32, 32, 3, stride=2, padding=1)
self.conv3 = nn.Conv2d(32, 32, 3, stride=2, padding=1)
self.conv4 = nn.Conv2d(32, 32, 3, stride=2, padding=1)
self.linear = nn.Linear(32 * 6 * 6, 512)
self.critic_linear = nn.Linear(512, 1)
self.actor_linear = nn.Linear(512, num_actions)
self._initialize_weights() def _initialize_weights(self):
for module in self.modules():
if isinstance(module, nn.Conv2d) or isinstance(module, nn.Linear):
nn.init.orthogonal_(module.weight, nn.init.calculate_gain('relu'))
nn.init.constant_(module.bias, 0) def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = F.relu(self.conv4(x))
x = self.linear(x.view(x.size(0), -1))
return self.actor_linear(x), self.critic_linear(x)
5. 定义 PPO 算法
def evaluation(opt, global_model, num_states, num_actions,curr_episode):
print('start evalution !')
torch.manual_seed(123)
if opt['action_type'] == "right":
actions = RIGHT_ONLY
elif opt['action_type'] == "simple":
actions = SIMPLE_MOVEMENT
else:
actions = COMPLEX_MOVEMENT
env = create_train_env(opt['world'], opt['stage'], actions)
local_model = Net(num_states, num_actions)
if torch.cuda.is_available():
local_model.cuda()
local_model.eval()
state = torch.from_numpy(env.reset())
if torch.cuda.is_available():
state = state.cuda() plt.figure(figsize=(10,10))
img = plt.imshow(env.render(mode='rgb_array')) done=False
local_model.load_state_dict(global_model.state_dict()) #加载网络参数\ while not done:
if torch.cuda.is_available():
state = state.cuda()
logits, value = local_model(state)
policy = F.softmax(logits, dim=1)
action = torch.argmax(policy).item()
state, reward, done, info = env.step(action)
state = torch.from_numpy(state) img.set_data(env.render(mode='rgb_array')) # just update the data
display.display(plt.gcf())
display.clear_output(wait=True) if info["flag_get"]:
print("flag getted in episode:{}!".format(curr_episode))
torch.save(local_model.state_dict(),
"{}/ppo_super_mario_bros_{}_{}_{}".format(opt['saved_path'], opt['world'], opt['stage'],curr_episode))
opt.update({'episode':curr_episode})
env.close()
return True
return False
def train(opt):
#判断cuda是否可用
if torch.cuda.is_available():
torch.cuda.manual_seed(123)
else:
torch.manual_seed(123)
if os.path.isdir(opt['log_path']):
shutil.rmtree(opt['log_path']) os.makedirs(opt['log_path'])
if not os.path.isdir(opt['saved_path']):
os.makedirs(opt['saved_path'])
mp = _mp.get_context("spawn")
#创建环境
envs = MultipleEnvironments(opt['world'], opt['stage'], opt['action_type'], opt['num_processes'])
#创建模型
model = Net(envs.num_states, envs.num_actions)
if opt['pretrain_model']:
print('加载预训练模型')
if not os.path.exists("ppo_super_mario_bros_1_1_0"):
mox.file.copy_parallel(
"obs://modelarts-labs-bj4/course/modelarts/zjc_team/reinforcement_learning/ppo_mario/ppo_super_mario_bros_1_1_0",
"ppo_super_mario_bros_1_1_0")
if torch.cuda.is_available():
model.load_state_dict(torch.load("ppo_super_mario_bros_1_1_0"))
model.cuda()
else:
model.load_state_dict(torch.load("ppo_super_mario_bros_1_1_0",torch.device('cpu')))
else:
model.cuda()
model.share_memory()
optimizer = torch.optim.Adam(model.parameters(), lr=opt['lr'])
#环境重置
[agent_conn.send(("reset", None)) for agent_conn in envs.agent_conns]
#接收当前状态
curr_states = [agent_conn.recv() for agent_conn in envs.agent_conns]
curr_states = torch.from_numpy(np.concatenate(curr_states, 0))
if torch.cuda.is_available():
curr_states = curr_states.cuda()
curr_episode = 0
#在最大局数内训练
while curr_episode<opt['max_episode']:
if curr_episode % opt['save_interval'] == 0 and curr_episode > 0:
torch.save(model.state_dict(),
"{}/ppo_super_mario_bros_{}_{}_{}".format(opt['saved_path'], opt['world'], opt['stage'], curr_episode))
curr_episode += 1
old_log_policies = []
actions = []
values = []
states = []
rewards = []
dones = []
#一局内最大步数
for _ in range(opt['num_local_steps']):
states.append(curr_states)
logits, value = model(curr_states)
values.append(value.squeeze())
policy = F.softmax(logits, dim=1)
old_m = Categorical(policy)
action = old_m.sample()
actions.append(action)
old_log_policy = old_m.log_prob(action)
old_log_policies.append(old_log_policy)
#执行action
if torch.cuda.is_available():
[agent_conn.send(("step", act)) for agent_conn, act in zip(envs.agent_conns, action.cpu())]
else:
[agent_conn.send(("step", act)) for agent_conn, act in zip(envs.agent_conns, action)]
state, reward, done, info = zip(*[agent_conn.recv() for agent_conn in envs.agent_conns])
state = torch.from_numpy(np.concatenate(state, 0))
if torch.cuda.is_available():
state = state.cuda()
reward = torch.cuda.FloatTensor(reward)
done = torch.cuda.FloatTensor(done)
else:
reward = torch.FloatTensor(reward)
done = torch.FloatTensor(done)
rewards.append(reward)
dones.append(done)
curr_states = state _, next_value, = model(curr_states)
next_value = next_value.squeeze()
old_log_policies = torch.cat(old_log_policies).detach()
actions = torch.cat(actions)
values = torch.cat(values).detach()
states = torch.cat(states)
gae = 0
R = []
#gae计算
for value, reward, done in list(zip(values, rewards, dones))[::-1]:
gae = gae * opt['gamma'] * opt['tau']
gae = gae + reward + opt['gamma'] * next_value.detach() * (1 - done) - value.detach()
next_value = value
R.append(gae + value)
R = R[::-1]
R = torch.cat(R).detach()
advantages = R - values
#策略更新
for i in range(opt['num_epochs']):
indice = torch.randperm(opt['num_local_steps'] * opt['num_processes'])
for j in range(opt['batch_size']):
batch_indices = indice[
int(j * (opt['num_local_steps'] * opt['num_processes'] / opt['batch_size'])): int((j + 1) * (
opt['num_local_steps'] * opt['num_processes'] / opt['batch_size']))]
logits, value = model(states[batch_indices])
new_policy = F.softmax(logits, dim=1)
new_m = Categorical(new_policy)
new_log_policy = new_m.log_prob(actions[batch_indices])
ratio = torch.exp(new_log_policy - old_log_policies[batch_indices])
actor_loss = -torch.mean(torch.min(ratio * advantages[batch_indices],
torch.clamp(ratio, 1.0 - opt['epsilon'], 1.0 + opt['epsilon']) *
advantages[
batch_indices]))
critic_loss = F.smooth_l1_loss(R[batch_indices], value.squeeze())
entropy_loss = torch.mean(new_m.entropy())
#损失函数包含三个部分:actor损失,critic损失,和动作entropy损失
total_loss = actor_loss + critic_loss - opt['beta'] * entropy_loss
optimizer.zero_grad()
total_loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)
optimizer.step()
print("Episode: {}. Total loss: {}".format(curr_episode, total_loss)) finish=False
for i in range(opt["num_processes"]):
if info[i]["flag_get"]:
finish=evaluation(opt, model,envs.num_states, envs.num_actions,curr_episode)
if finish:
break
if finish:
break
6. 训练模型
训练 10 Episode,耗时约 5 分钟
train(opt)
7. 使用模型推理游戏
定义推理函数
def infer(opt):
if torch.cuda.is_available():
torch.cuda.manual_seed(123)
else:
torch.manual_seed(123)
if opt['action_type'] == "right":
actions = RIGHT_ONLY
elif opt['action_type'] == "simple":
actions = SIMPLE_MOVEMENT
else:
actions = COMPLEX_MOVEMENT
env = create_train_env(opt['world'], opt['stage'], actions)
model = Net(env.observation_space.shape[0], len(actions))
if torch.cuda.is_available():
model.load_state_dict(torch.load("{}/ppo_super_mario_bros_{}_{}_{}".format(opt['saved_path'],opt['world'], opt['stage'],opt['episode'])))
model.cuda()
else:
model.load_state_dict(torch.load("{}/ppo_super_mario_bros_{}_{}_{}".format(opt['saved_path'], opt['world'], opt['stage'],opt['episode']),
map_location=torch.device('cpu')))
model.eval()
state = torch.from_numpy(env.reset()) plt.figure(figsize=(10,10))
img = plt.imshow(env.render(mode='rgb_array')) while True:
if torch.cuda.is_available():
state = state.cuda()
logits, value = model(state)
policy = F.softmax(logits, dim=1)
action = torch.argmax(policy).item()
state, reward, done, info = env.step(action)
state = torch.from_numpy(state) img.set_data(env.render(mode='rgb_array')) # just update the data
display.display(plt.gcf())
display.clear_output(wait=True) if info["flag_get"]:
print("World {} stage {} completed".format(opt['world'], opt['stage']))
break if done and info["flag_get"] is False:
print('Game Failed')
break
infer(opt)
World 1 stage 1 completed

最后
六一儿童节,快来华为云 AI Gallery 上体验 AI 闯关超级马里奥,无需考虑计算资源,环境的搭建,在 ModelArts 里跟着运行代码,点击链接在ModelArts里运行简单几行代码,手把手带你5分钟速成游戏王。
华为伙伴暨开发者大会 2022 火热来袭,重磅内容不容错过!
【精彩活动】
勇往直前・做全能开发者→12 场技术直播前瞻,8 大技术宝典高能输出,还有代码密室、知识竞赛等多轮神秘任务等你来挑战。即刻闯关,开启终极大奖!点击踏上全能开发者晋级之路吧!
【技术专题】
未来已来,2022 技术探秘→华为各领域的前沿技术、重磅开源项目、创新的应用实践,站在智能世界的入口,探索未来如何照进现实,干货满满点击了解
儿童节,和 AI 一起通关 “超级马里奥兄弟”的更多相关文章
- 不设目标也能通关「马里奥」的AI算法,全靠好奇心学习
在强化学习中,设计密集.定义良好的外部奖励是很困难的,并且通常不可扩展.通常增加内部奖励可以作为对此限制的补偿,OpenAI.CMU 在本研究中更近一步,提出了完全靠内部奖励即好奇心来训练智能体的方法 ...
- Unity制作出《超级马里奥》的2D和3D混合效果
现在来做点别的东西.Nintendo Switch上刚推出的<超级马里奥>中,有一些关卡混合了2D和3D的画面,这种效果十分让人印象深刻.如何在Unity中实现这个效果呢? 正常情况下,摄 ...
- 洛谷P1000超级马里奥的神奇解法
话说上过洛谷的都知道,有一道经典例题P1000超级马里奥,这一题,可以说是非常简单非常经典,但是就算如此,还是可以人才辈出,我是个比较循规蹈矩的人(雾),所以我的代码就比较平常,也就是直接输出了所要求 ...
- Vue.js快速介绍-超级马里奥像素艺术
原文出处:Quick Introduction to Vue.js - Super Mario Pixel Art ::代码我已经归纳在github上:[vue2-pixel-art]::::__查看 ...
- cocos2dx3.0 超级马里奥开发笔记(两)——正确的规划游戏逻辑
我将不得不拿出一个完整的开发笔记.由于个人原因.代码已OK该,博客,那么就不要粘贴代码,直接解释了整个游戏设计,更确切地说,当新手应该注意的地方发展. 1.继承类和扩展作用的权----展阅读(MVC) ...
- 【JavaScript游戏开发】使用HTML5+Canvas+JavaScript 封装的一个超级马里奥游戏(包含源码)
这个游戏基本上是建立在JavaScript模块化的开发基础上进行封装的,对游戏里面需要使用到的游戏场景进行了封装,分别实现了Game,Sprite,enemy,player, base,Animati ...
- 游戏编程算法与技巧 Game Programming Algorithms and Techniques (Sanjay Madhav 著)
http://gamealgorithms.net 第1章 游戏编程概述 (已看) 第2章 2D图形 (已看) 第3章 游戏中的线性代数 (已看) 第4章 3D图形 (已看) 第5章 游戏输入 (已看 ...
- FC红白机游戏列表(维基百科)
1055个fc游戏列表 日文名 中文译名 英文版名 发行日期 发行商 ドンキーコング 大金刚 Donkey Kong 1983年7月15日 任天堂 ドンキーコングJR. 大金刚Jr. Donkey K ...
- 剖析虚幻渲染体系(14)- 延展篇:现代渲染引擎演变史Part 1(萌芽期)
目录 14.1 本篇概述 14.1.1 游戏引擎简介 14.1.2 游戏引擎模块 14.1.3 游戏引擎列表 14.1.3.1 Unreal Engine 14.1.3.2 Unity 14.1.3. ...
随机推荐
- php运用validate+ajax检测用户名是否已存在
前提:如果还不知道什么是validate,请前往这里 一.remote rules: username:{ required:true, minlength:8, maxlength:8, remot ...
- Python使用函数实现杨辉三角
运行效果: 可在函数中指定阶层数,输出对应的杨辉三角 源代码如下: 1 # -*-coding:utf-8 -*- 2 ''' 3 chapter4_do.py 4 函数yanghui(n)用于输出n ...
- FastAPI(六十九)实战开发《在线课程学习系统》接口开发--修改密码
之前我们分享了FastAPI(六十八)实战开发<在线课程学习系统>接口开发--用户 个人信息接口开发.这次我们去分享实战开发<在线课程学习系统>接口开发--修改密码 我们梳理一 ...
- Java基础之浅谈接口
前言 前几篇文章我们已经把Java的封装.继承.多态学习完了,现在我们开始比较便于我们实际操作的学习,虽然它也是Java基础部分,但是其实入门容易,精通很难. 我认真的给大家整理了一下这些必须学会.了 ...
- Java 实例 - 读取文件内容
原文作者:菜鸟教程 原文链接:Java 实例 - 读取文件内容(建议前往原文以获得最佳体验) 按行读取文本文件 import java.io.*; public class Main { public ...
- c++对c的拓展_内联函数
目的:保持处理宏的高效及安全性 解决的问题:1.c中预处理宏有些难以发现的问题 2.c++ 中预处理不能访问类成员,不能作用类的成员函数 作用:无函数调用时开销,又可像普通函数般进行参数.返回值类型安 ...
- spring-Bean依赖注入-》普通数据类型
1.创建UserDao接口以及UserDaoImpl实现类(接口代码省略) public class UserDaoImpl implements UserDao { private String u ...
- 全国省市区县和乡镇街道行政区划矢量边界坐标经纬度地图最新数据免费下载 支持shp geojson json sql格式
关键词: 省市区三级, 乡镇四级, 全国, 行政区划, 坐标边界, 矢量数据, 地理围栏, 免费下载, 2018 2019 2020 2021 2022年份, 最新数据, 长期更新, 开源维护, 支持 ...
- OA办公软件篇(二)—权限管理
权限管理的背景 权限管理的作用 迭代历程 关键名词释义 权限管理模型 具体实现 写在最后 权限管理的背景 在OA办公软件篇(一)-组织架构一文中,我们说到组织架构是软件系统的权限体系的重要搭建依据 ...
- qt在linux下引用x11库编译错误的解决办法
首先安装x11的开发包,以debian9为例:sudo apt install xorg-dev这个解决.h头文件和.a库文件在qt的.pro文件中加入:LIBS += -lX11这个解决连接错误,注 ...