B树-插入
B树系列文章
1. B树-介绍
2. B树-查找
3. B树-插入
4. B树-删除
插入
根据B树的以下两个特性
- 每一个结点最多有m个子结点
- 有k个子结点的非叶子结点拥有 k − 1 个键
可以得出,B树每个结点存放键的数量是有上限的是m-1,因此插入操作可能导致结点“溢出”。
插入操作的重点和难点在于结点“溢出”后的再平衡操作
假设有一棵3阶B树,如下图所示。
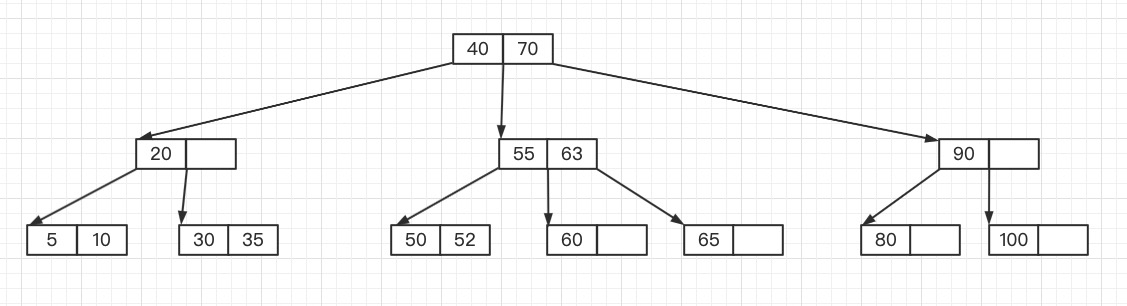
通过给这棵3阶B树插入键值53,来分析B树插入键值的过程。
首先,参考查找的步骤,最终定位到53应该插入到Node21结点的最后
但是这是一个3阶B树,每个结点拥有键的最大数量为2,因此插入53会导致Node21"溢出"
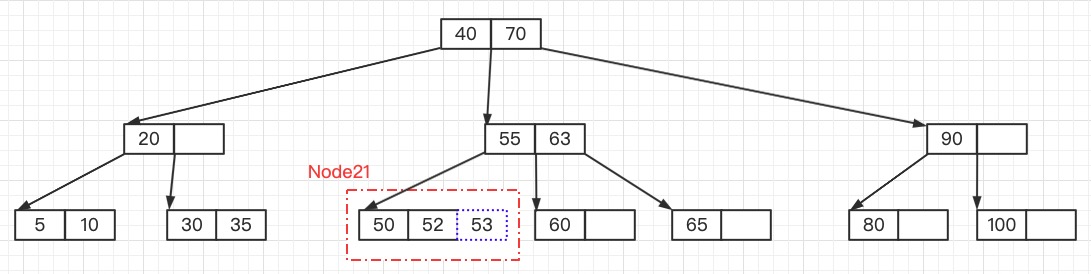
由于Node21结点“溢出”,需要对Node21进行拆分,拆分方法如下
- 从该结点的原有键和新的键中选择出中位数,这个中位数作为分隔值
- 小于这一中位数的键放入左边结点,大于这一中位数的键放入右边结点,中位数作为分隔值。
- 分隔值被插入到父结点中,这可能会造成父结点分裂,分裂父结点时可能又会使它的父结点分裂,以此类推。如果没有父结点(这一结点是根结点),就创建一个新的根结点(增加了树的高度)。
下图是对Node21进行拆分的结果,Node21分裂成两个新的结点和分隔值53,53需要插入父结点中
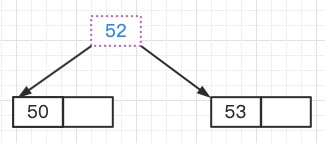
将分隔值插入父结点中,形成Node2结点,原来的Node21结点被拆分为新的Node21和Node22结点
可以看出来,此时Node2结点键的数量达到了阶数,即达到“溢出”条件了
因此,需要继续对Node2进行拆分

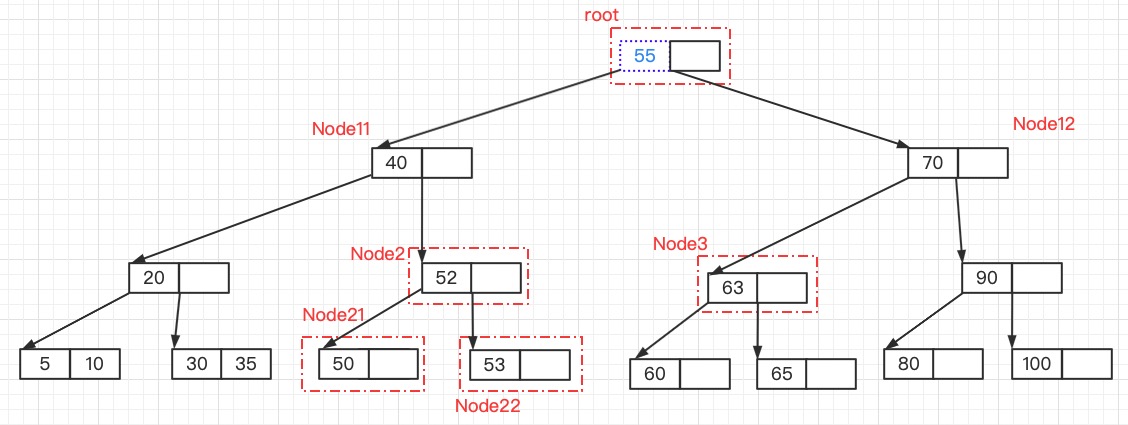
对Node2进行拆分,中间值55提升到root结点,原来的Node2结点拆分成Node2和Node3两个新结点
同样的,此时root结点也“溢出”了,需要对root结点进行拆分
对root结点的拆分,最终造成B树高度的增加

对根结点进行拆分,55被提升,需要创建新的根结点存放键55,键值40和70分别构成新的两个儿子结点,分别是Node1和Node12
此时B数重新平衡了。
这里总结下
所有的插入都从根结点开始。要插入一个新的键,首先搜索这棵树找到新键应该被添加到的对应结点。将新键插入到这一结点中的步骤如下:
如果结点拥有的键数量小于最大值,那么有空间容纳新的键。将新键插入到这一结点,且保持结点中键有序。
否则的话这一结点已经满了,将它平均地拆分成两个结点:
从该结点的原有键和新的键中选择出中位数
小于这一中位数的键放入左边结点,大于这一中位数的键放入右边结点,中位数作为分隔值。
分隔值被插入到父结点中,这可能会造成父结点分裂,分裂父结点时可能又会使它的父结点分裂,以此类推。如果没有父结点(这一结点是根结点),就创建一个新的根结点(增加了树的高度)。
这里是插入的代码
/**
* 插入key
* 时间复杂度为O(logn)
**/
func (bTreeNode *BTreeNode) intert(key int, m int) ([]*BTreeNode, int) {
// 找到第一个不比key小的,注意leaf的数量比key数量多1
idx := 0
for idx < bTreeNode.keyNum && key > bTreeNode.keyList[idx] {
idx++
} // BTreeNode已有该key
if idx < bTreeNode.keyNum && bTreeNode.keyList[idx] == key {
return nil, 0
} if bTreeNode.isLeaf { // 叶子结点
// idx及idx后面元素往后移动
if idx < m-1 {
copy(bTreeNode.keyList[idx+1:], bTreeNode.keyList[idx:])
}
bTreeNode.keyList[idx] = key
bTreeNode.keyNum += 1
} else { // 非叶子结点
// 判断结点是否要满了
// 先往上提
children, midKey := bTreeNode.leafList[idx].intert(key, m)
if children != nil {
// idx是midKey的插入位置,idx后面元素往后移动
if idx < m-1 {
copy(bTreeNode.keyList[idx+1:], bTreeNode.keyList[idx:])
copy(bTreeNode.leafList[idx+2:], bTreeNode.leafList[idx+1:])
}
bTreeNode.keyList[idx] = midKey
bTreeNode.leafList[idx] = children[0]
bTreeNode.leafList[idx+1] = children[1]
bTreeNode.keyNum += 1
}
} if bTreeNode.keyNum == m { // 节点key数量超了
// 从中间将该结点一分为2
mid := bTreeNode.keyNum / 2
midKey := bTreeNode.keyList[mid] // 左儿子
leftNode := createNode(m, mid, bTreeNode.isLeaf)
copy(leftNode.keyList, bTreeNode.keyList[:mid])
copy(leftNode.leafList, bTreeNode.leafList[:mid+1]) // 右边儿子
rightNode := createNode(m, m-mid-1, bTreeNode.isLeaf)
copy(rightNode.keyList, bTreeNode.keyList[mid+1:])
copy(rightNode.leafList, bTreeNode.leafList[mid+1:]) return []*BTreeNode{leftNode, rightNode}, midKey
}
return nil, 0
} /** 插入key
* 时间复杂度O(logn)
**/
func (bTree *BTree) Insert(key int) {
children, midKey := bTree.root.intert(key, bTree.m)
if children != nil {
root := createNode(bTree.m, 1, false)
root.keyList[0] = midKey
root.leafList[0] = children[0]
root.leafList[1] = children[1]
bTree.root = root
}
}
B树-插入的更多相关文章
- AVL树插入和删除
一.AVL树简介 AVL树是一种平衡的二叉查找树. 平衡二叉树(AVL 树)是一棵空树,或者是具有下列性质的二叉排序树: 1它的左子树和右子树都是平衡二叉树, 2且左子树和右子树高度之差的 ...
- B树——插入和删除
B树--插入和删除 B树的插入 5阶B数--结点关键字个数向上取整m/2-1≤n≤m-1 即2≤n≤4 连续插入5个元素后,超出来了. 在插入key后,若导致原结点关键字数超过上限,则从中间位置(m/ ...
- AVL树插入操作实现
为了提高二插排序树的性能,规定树中的每个节点的左子树和右子树高度差的绝对值不能大于1.为了满足上面的要求需要在插入完成后对树进行调整.下面介绍各个调整方式. 右单旋转 如下图所示,节点A的平衡因子(左 ...
- AVL树插入(Python实现)
建立AVL树 class AVLNode(object): def __init__(self,data): self.data = data self.lchild = None self.rchi ...
- HDU 5687 字典树插入查找删除
题目:http://acm.hdu.edu.cn/showproblem.php?pid=5687 2016百度之星资格赛C题,直接套用字典树,顺便巩固了一下自己对字典树的理解 #include< ...
- Trie树的创建、插入、查询的实现
原文:http://blog.chinaunix.net/xmlrpc.php?r=blog/article&uid=28977986&id=3807947 1.什么是Trie树 Tr ...
- B+树的插入、删除(附源代码)
B+ Tree Index B+树的插入 B+树的删除 完整测试代码 Basic B+树和B树类似(有关B树:http://www.cnblogs.com/YuNanlong/p/6354029.ht ...
- AVL树的插入与删除
AVL 树要在插入和删除结点后保持平衡,旋转操作必不可少.关键是理解什么时候应该左旋.右旋和双旋.在Youtube上看到一位老师的视频对这个概念讲解得非常清楚,再结合算法书和网络的博文,记录如下. 1 ...
- [BZOJ3065]带插入区间K小值 解题报告 替罪羊树+值域线段树
刚了一天的题终于切掉了,数据结构题的代码真**难调,这是我做过的第一道树套树题,做完后感觉对树套树都有阴影了......下面写一下做题记录. Portal Gun:[BZOJ3065]带插入区间k小值 ...
随机推荐
- Redis基础与性能调优
Redis是一个开源的,基于内存的结构化数据存储媒介,可以作为数据库.缓存服务或消息服务使用. Redis支持多种数据结构,包括字符串.哈希表.链表.集合.有序集合.位图.Hyperloglogs等. ...
- Java 将HTML转为Word
本文以Java代码为例介绍如何实现将HTML文件转为Word文档(.docx..doc).在实际开发场景中可参考此方法来转换.下面详细方法及步骤. 在编辑代码前,请先在程序中导入Spire.Doc.j ...
- 超 Nice 的表格响应式布局小技巧
今天,遇到了一个很有意思的问题,一名群友问我,仅仅使用 CSS,能否实现这样一种响应式的布局效果: 简单解析一下效果: 在屏幕视口较为宽时,表现为一个整体 Table 的样式 而当屏幕视口宽度较小时, ...
- DTCC 干货分享:Real Time DaaS - 面向TP+AP业务的数据平台架构
2021年10月20日,Tapdata 创始人唐建法(TJ)受邀出席 DTCC 2021(中国数据库技术大会),并在企业数据中台设计与实践专场上,发表主旨演讲"Real Time Daa ...
- Tapdata 实时数据融合平台解决方案(二):理解数据中台
作者介绍:TJ,唐建法,Tapdata 钛铂数据 CTO,MongoDB中文社区主席,原MongoDB大中华区首席架构师,极客时间MongoDB视频课程讲师. 数据中台定义: 以打通部门或数据孤岛的统 ...
- Grammarly for Chrome-语法、用词自动检查
从语法和拼写到风格和语气,Grammarly帮助你消除写作错误,找到完美的词语来表达自己.当你在Gmail.Twitter.LinkedIn和几乎任何你发现自己在写作的地方写作时,你都会从Gramma ...
- 这么强?!Erda MySQL Migrator:持续集成的数据库版本控制
为什么要进行数据库版本控制? 现代软件工程逐渐向持续集成.持续交付演进,软件一次性交付了事的场景逐渐无法满足复杂多变的业务需求,"如何高效地进行软件版本控制"成为我们面临的挑战.同 ...
- 2022年字节跳动基础架构前端实习生凉经(4轮技术面+hr面)
技术一面 原文链接:https://juejin.cn/post/7120516854203809829 因为我之前的项目经验有开发小程序的,所以一开始就问了小程序的问题 1.小程序onload和on ...
- 如何给selenium.chrome写扩展拦截或转发请求
Selenium.WebDriver Selenium WebDriver 是一组开源 API,用于自动测试 Web 应用程序,利用它可以通过代码来控制chrome浏览器! 有时候我们需要mock接口 ...
- 基于ABP实现DDD--领域逻辑和应用逻辑
本文主要介绍了多应用层的问题,包括原因和实现.通过理解介绍了如何区分领域逻辑和应用逻辑,哪些是正确的实践,哪些是不推荐的或者错误的实践. 一.多应用层的问题 1.多应用层介绍 不知道你们是否会 ...