【机器学习】K-means聚类分析
前言
聚类问题是无监督学习的问题,算法思想就是物以类聚,人以群分,聚类算法感知样本间的相似度,进行类别归纳,对新输入进行输出预测,输出变量取有限个离散值。本次我们使用两种方法对鸢尾花数据进行聚类。
- 无监督就是没有标签的进行分类
K-means 聚类算法
K-means聚类算法(k-均值或k-平均)聚类算法。算法思想就是首先随机确定k个中心点作为聚类中心,然后把每个数据点分配给最邻近的中心点,分配完成后形成k个聚类,计算各个聚类的平均中心点,将其作为该聚类新的类中心点,然后迭代上述步骤知道分配过程不在产生变化。
算法流程
- 随机选择K个随机点(成为聚类中心)
- 对数据集中的每个数据点,按照距离K个中心点的距离,将其与距离最近的中心点关联起来,与同一中心点关联的所有点聚成一类
- 计算每一组的均值,将改组所关联的中心点移动到平均值位置
- 重复上两步,直至中心点不再发生变化
优缺点
优点:
- 原理比较简单,实现容易,收敛速度快
- 聚类效果比较优
- 算法可解释度比较强
- 主要需要调参的参数仅仅是簇数K
缺点:
- K值选取不好把握
- 不平衡数据集聚类效果不佳
- 采用迭代方法,得到结果只是局部最优
- 对噪音和异常点比较敏感
鸢尾花聚类
数据集
数据集:数据集采用sklern中的数据集
数据集分布图:我们可以看出数据的大致分布情况
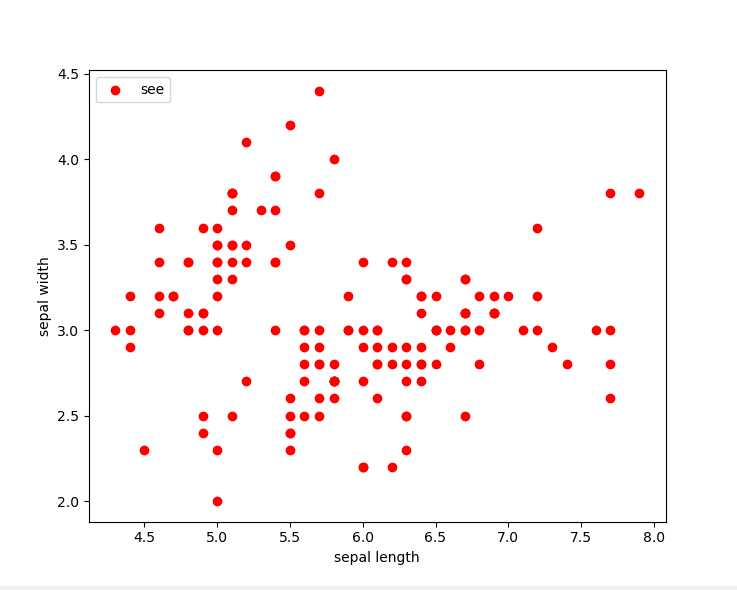
使用sklearn中的模型
# 鸢尾花数据集 150 条数据
## 导包
import numpy as np
import matplotlib.pyplot as plt
# 导入数据集包
from sklearn import datasets
from sklearn.cluster import KMeans
## 加载数据据集
iris = datasets.load_iris()
X = iris.data[:,:4]
print(X.shape) # 150*4
## 绘制二维数据分布图
## 前两个特征
plt.scatter(X[:,0],X[:,1],c='red',marker='o',label='see')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend(loc=2)
plt.show()
'''
直接调用包
'''
## 实例化K-means类,并定义训练函数
def Model(n_clusters):
estimator = KMeans(n_clusters=n_clusters)
return estimator
## 定义训练韩硕
def train(estimator):
estimator.fit(X)
## 训练
estimator = Model(3)
## 开启训练拟合
train(estimator=estimator)
## 可视化展示
label_pred = estimator.labels_ # 获取聚类标签
## 找到3中聚类结构
x0 = X[label_pred==0]
x1 = X[label_pred==1]
x2 = X[label_pred==2]
plt.scatter(x0[:,0],x0[:,1],c='red',marker='o',label='label0')
plt.scatter(x1[:,0],x1[:,1],c='green',marker='*',label='label1')
plt.scatter(x2[:,0],x2[:,1],c='blue',marker='+',label='label2')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend(loc=2)
plt.show()
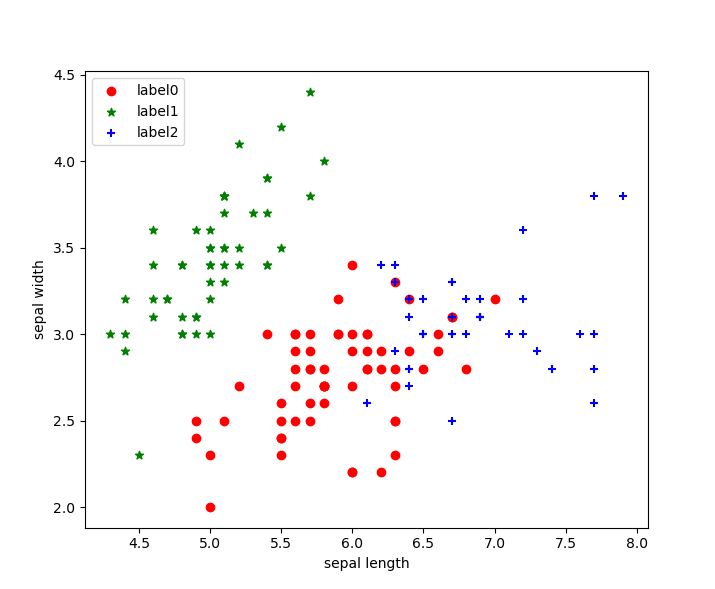
聚类结果
我们可以看出聚类结果按照我们的要求分为了三类,分别使用红、蓝、绿三种颜色进行了展示!
聚类效果图:
手写K-means算法
# 鸢尾花数据集 150 条数据
## 导包
import numpy as np
import matplotlib.pyplot as plt
# 导入数据集包
from sklearn import datasets
from sklearn.cluster import KMeans
## 加载数据据集
iris = datasets.load_iris()
X = iris.data[:,:4]
print(X.shape) # 150*4
## 绘制二维数据分布图
## 前两个特征
plt.scatter(X[:,0],X[:,1],c='red',marker='o',label='see')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend(loc=2)
plt.show()
'''
直接手写实现
'''
'''
1、随机初始化 随机寻找k个簇的中心
2、对这k个中心进行聚类
3、重复1、2,知道中心达到稳定
'''
### 欧氏距离计算
def distEclud(x,y):
return np.sqrt(np.sum((x-y)**2))
### 为数据集定义簇的中心
def randCent(dataSet,k):
m,n = dataSet.shape
centroids = np.zeros((k,n))
for i in range(k):
index = int(np.random.uniform(0,m))
centroids[i,:] = dataSet[index,:]
return centroids
## k均值聚类算法
def KMeans(dataSet,k):
m = np.shape(dataSet)[0]
clusterAssment = np.mat(np.zeros((m,2)))
clusterChange = True
## 1 初始化质心centroids
centroids = randCent(dataSet,k)
while clusterChange:
# 样本所属簇不在更新时停止迭代
clusterChange = False
# 遍历所有样本
for i in range(m):
minDist = 100000.0
minIndex = -1
# 遍历所有质心
# 2 找出最近质心
for j in range(k):
distance = distEclud(centroids[j,:],dataSet[i,:])
if distance<minDist:
minDist = distance
minIndex = j
# 更新该行所属的簇
if clusterAssment[i,0] != minIndex:
clusterChange = True
clusterAssment[i,:] = minIndex,minDist**2
# 更新质心
for j in range(k):
pointsInCluster = dataSet[np.nonzero(clusterAssment[:,0].A == j)[0]] # 获取对应簇类所有的点
centroids[j,:] = np.mean(pointsInCluster,axis=0)
print("cluster complete")
return centroids,clusterAssment
def draw(data, center, assment):
length = len(center)
fig = plt.figure
data1 = data[np.nonzero(assment[:,0].A == 0)[0]]
data2 = data[np.nonzero(assment[:,0].A == 1)[0]]
data3 = data[np.nonzero(assment[:,0].A == 2)[0]]
# 选取前两个数据绘制原始数据的散点
plt.scatter(data1[:,0],data1[:,1],c='red',marker='o',label='label0')
plt.scatter(data2[:,0],data2[:,1],c='green',marker='*',label='label1')
plt.scatter(data3[:,0],data3[:,1],c='blue',marker='+',label='label2')
# 绘制簇的质心点
for i in range(length):
plt.annotate('center',xy=(center[i,0],center[i,1]),xytext=(center[i,0]+1,center[i,1]+1),arrowprops=dict(facecolor='yellow'))
plt.show()
# 选取后两个维度绘制原始数据散点图
plt.scatter(data1[:, 2], data1[:, 3], c='red', marker='o', label='label0')
plt.scatter(data2[:, 2], data2[:, 3], c='green', marker='*', label='label1')
plt.scatter(data3[:, 2], data3[:, 3], c='blue', marker='+', label='label2')
# 绘制簇的质心点
for i in range(length):
plt.annotate('center', xy=(center[i, 2], center[i, 3]), xytext=(center[i, 2] + 1, center[i, 3] + 1),
arrowprops=dict(facecolor='yellow'))
plt.show()
## 调用
dataSet = X
k = 3
centroids,clusterAssment = KMeans(dataSet,k)
draw(dataSet,centroids,clusterAssment)
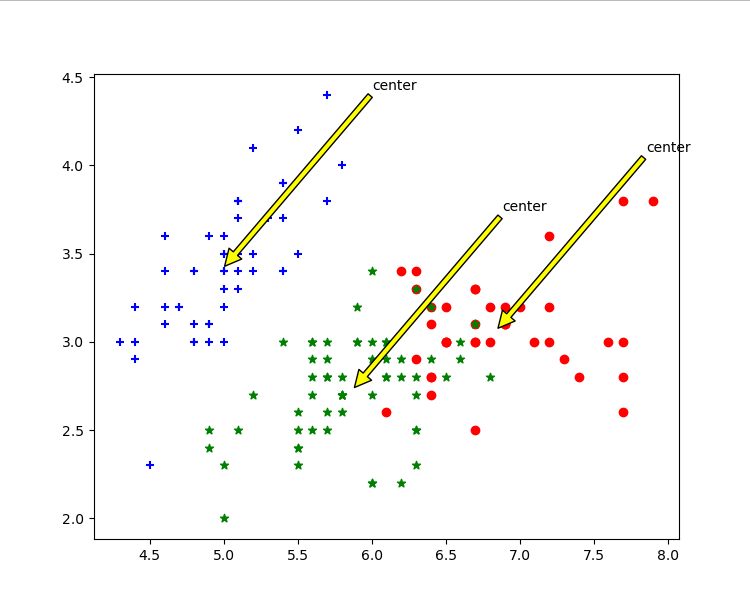
效果图展示
我们可以看到手写实现的也通过三种颜色实现类,可以看出两种方式实现结果是几乎相同的。
根据花萼长度花萼宽度聚类
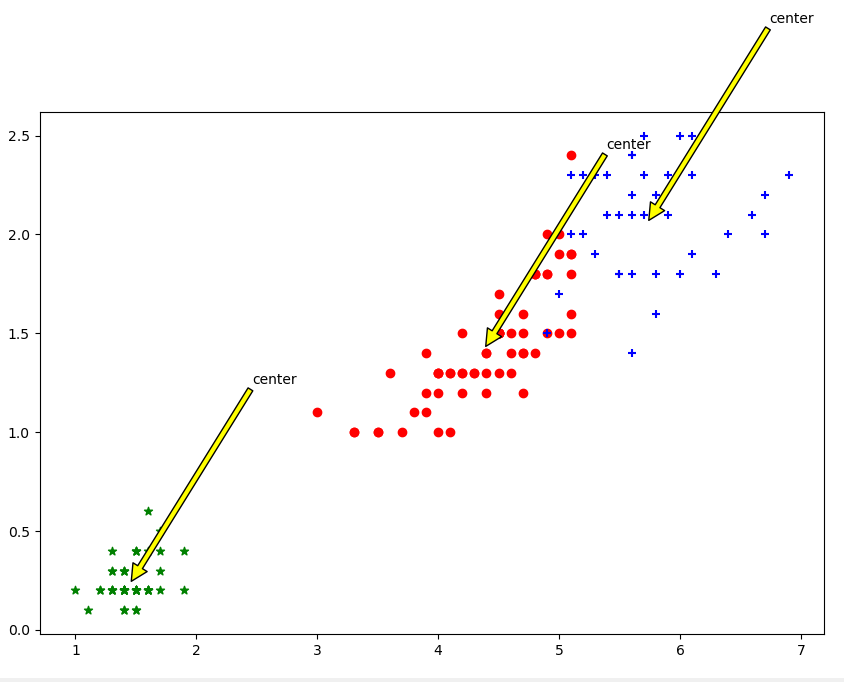
根据花瓣长度花瓣宽度聚类:
总结
我们既可以使用sklearn包中封装好的模型进行聚类分析,也可以自己手写实现,在某些问题上,两者都可以达到相同的结果,我们对于不同的问题可以更合适的方法进行处理。
【机器学习】K-means聚类分析的更多相关文章
- SPSS聚类分析:K均值聚类分析
SPSS聚类分析:K均值聚类分析 一.概念:(分析-分类-K均值聚类) 1.此过程使用可以处理大量个案的算法,根据选定的特征尝试对相对均一的个案组进行标识.不过,该算法要求您指定聚类的个数.如果知道, ...
- 秒懂机器学习---k临近算法(KNN)
秒懂机器学习---k临近算法(KNN) 一.总结 一句话总结: 弄懂原理,然后要运行实例,然后多解决问题,然后想出优化,分析优缺点,才算真的懂 1.KNN(K-Nearest Neighbor)算法的 ...
- 软件——机器学习与Python,聚类,K——means
K-means是一种聚类算法: 这里运用k-means进行31个城市的分类 城市的数据保存在city.txt文件中,内容如下: BJ,2959.19,730.79,749.41,513.34,467. ...
- [机器学习] k近邻算法
算是机器学习中最简单的算法了,顾名思义是看k个近邻的类别,测试点的类别判断为k近邻里某一类点最多的,少数服从多数,要点摘录: 1. 关键参数:k值 && 距离计算方式 &&am ...
- 机器学习---K最近邻(k-Nearest Neighbour,KNN)分类算法
K最近邻(k-Nearest Neighbour,KNN)分类算法 1.K最近邻(k-Nearest Neighbour,KNN) K最近邻(k-Nearest Neighbour,KNN)分类算法, ...
- 机器学习--K折交叉验证和非负矩阵分解
1.交叉验证 交叉验证(Cross validation),交叉验证用于防止模型过于复杂而引起的过拟合.有时亦称循环估计, 是一种统计学上将数据样本切割成较小子集的实用方法. 于是可以先在一个子集上做 ...
- 机器学习--K近邻 (KNN)算法的原理及优缺点
一.KNN算法原理 K近邻法(k-nearst neighbors,KNN)是一种很基本的机器学习方法. 它的基本思想是: 在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对 ...
- 机器学习-K近邻(KNN)算法详解
一.KNN算法描述 KNN(K Near Neighbor):找到k个最近的邻居,即每个样本都可以用它最接近的这k个邻居中所占数量最多的类别来代表.KNN算法属于有监督学习方式的分类算法,所谓K近 ...
- [机器学习]-K近邻-最简单的入门实战例子
本篇文章分为两个部分,前一部分主要简单介绍K近邻,后一部分是一个例子 第一部分--K近邻简介 从字面意思就可以容易看出,所谓的K近邻,就是找到某个样本距离(这里的距离可以是欧式距离,曼哈顿距离,切比雪 ...
随机推荐
- 谈谈.NET Core下如何利用 AsyncLocal 实现共享变量
前言 在Web 应用程序中,我们经常会遇到这样的场景,如用户信息,租户信息本次的请求过程中都是固定的,我们希望是这种信息在本次请求内,一次赋值,到处使用.本文就来探讨一下,如何在.NET Core 下 ...
- 比较爽的导航查询 功能 - SqlSugar ORM
1.导航查询特点 作用:主要处理主对象里面有子对象这种层级关系查询 1.1 无外键开箱就用 其它ORM导航查询 需要 各种配置或者外键,而SqlSugar则开箱就用,无外键,只需配置特性和主键就能使用 ...
- Java 18 新特性:简单Web服务器 jwebserver
在今年3月下旬的时候,Java版本已经更新到了18.接下来DD计划持续做一个系列,主要更新从Java 9开始的各种更新内容,但我不全部都介绍,主要挑一些有意思的内容,以文章和视频的方式来给大家介绍和学 ...
- “如何实现集中管理、灵活高效的CI/CD”研讨会报名即将截止
如何实现集中管理.灵活高效的CI/CD ZOOM中文在线研讨会将于 2022年3月29日,星期二,下午3:00-5:00, 也就是 明天 举行, 如果您还未注册,点击按钮,立即注册此次研讨会(注册即可 ...
- 聊聊 node 如何优雅地获取 mac 系统版本
背景 今天突然碰到了一个兼容性需求,需要根据不同 macOS 版本,进行不同的兼容性处理. 没想到看似简单的需求,中间也经历了一番波折,好在最后解决了问题. 在此记录一下解决问题的过程,也方便其他有类 ...
- 【Vagrant】启动安装Homestead卡在 SSH auth method: private key
注意:通过查找资料发现,导致这个问题的原因有很多,我的这个情况只能是一个参考. 问题描述 今天在使用虚拟机的时候,由于存放虚拟机的虚拟磁盘(vmdk文件)的逻辑分区容量不足(可用容量为0了).然后在使 ...
- kNN-准备数据
在上一小节,我们大概了解了kNN算法的基本原理,现在我们要进行数据的处理 本小节所用数据集来自[机器学习实战]:Machine Learning in Action (manning.com) 下载数 ...
- 如何生成一个java文档
如何生成一个java文档 众所周知,一个程序给别人看可能可以看懂,几万行程序就不一定了.在更多的时候,我们并不需要让别人知道我们的程序是怎么写的,只需要告诉他们怎么用的.那么,api文档就发挥了它的作 ...
- 监控工具:nmon
软件介绍 分析工具 分析 AIX 和 Linux 性能的免费工具, 这个高效的工具可以工作于任何哑屏幕.telnet 会话.甚至拨号线路.另外,它并不会消耗大量的 CPU 周期,通常低于百分之二. ...
- Spring Boot 2.7.0发布,2.5停止维护,节奏太快了吧
这几天是Spring版本日,很多Spring工件都发布了新版本, Spring Framework 6.0.0 发布了第 4 个里程碑版本,此版本包含所有针对 5.3.20 的修复补丁,以及特定于 6 ...