【大数据面试】Flink 01 概述:包含内容、层次架构、运行组件、部署模式、任务提交流程、任务调度概念、编程模型组成
一、概述
1、介绍
对无界和有界数据流进行有状态计算的分布式引擎和框架,并可以使用高层API编写分布式任务,主要包括:
DataSet API(批处理):静态数据抽象为分布式数据集,方便使用操作符进行处理(Python)
DataStream API(流处理):对分布式流数据处理,从而进行各种操作
Table API:将结构化数据抽象为关系表,并使用类SQL的DSL的表进行查询
其他特定领域的库,例如机器学习、图计算
2、分层架构介绍
(1)介绍
分层架构,下层组件提供抽象服务于上层
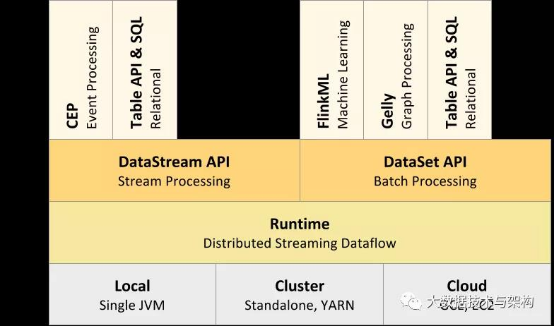
(2)自下而上各层介绍
Deploy层:Flink的不同部署模式,包括local、Standalone脱机、Cluster、Cloud等
Runtime层:提供Flink计算的核心实现(过程函数ProcessFunction)
API层:面向流(DataStream)处理和批(Batch)处理的API
Libraries层:应用框架,CEP(复杂事件处理)、基于SQL的操作(Table/SQL API)
(3)详解
Runtime层:有状态流通过过程函数(ProcessFunction)嵌入到DataStreamAPI中
API层:DataStream API提供了通用的数据处理构建模块,比如多种形式的转换(transformations),连接(joins),聚合(aggregations),窗口操作(windows)等等。
Libraries层:TableAPI是以表为中心的声明式编程,提供可比较的操作,执行前经过内置优化器进行优化
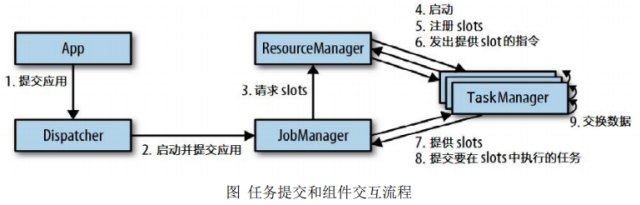
3、运行组件
(1)组成
作业管理器(JobManager)、资源管理器(ResourceManager)、任务管理器(TaskManager),以及分发器(Dispatcher)
(2)各组件功能
作业管理器JobManager:集群管理者Master和协调者、将作业图(JobGraph)转化为数据流图/执行图;请求资源、分发、协调;
资源管理器ResourceManager:(分配slot插槽)将有空闲插槽的TaskManager分配给JobManager,发起会话、中止释放资源;
任务管理器TaskManager:负责执行计算,(包含一定并发量)注册插槽、与同一程序的task M交换数据;
分发器Dispatcher:跨作业运行、为应用提交提供了REST接口。
Client:将Flink程序提交到集群,建立到JobManager的连接,将Flink Job提交给JobManager
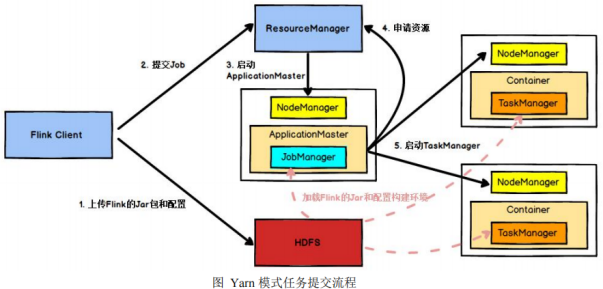
4、Flink的部署模式
(1)Standalone模式
(2)Yarn模式-Hadoop>2.2
两种模式:Session-Cluster和Per-Job-Cluster模式
何时向yarn申请资源,创建flink集群
(3)Kubernetes部署
启动Flink的docker组件:JobManager、TaskManager、JobManagerService
5、任务提交流程
(1)常规
(2)yarn模式
6、任务调度相关概念
(1)TaskManger与Slots:JVM进程、Task Slot是静态的概念,是指TaskManager具有的并发执行能力
(2)程序与数据流(DataFlow):Flink程序-Source、Transformation和Sink,转换运算(transformations)跟dataflow中的算子(operator)是一一对应的关系
(3)执行图(ExecutionGraph):直接映射成的数据流图是StreamGraph,也被称为逻辑流图,需要转换为物理视图
执行图包括4层:StreamGraph->JobGraph->ExecutionGraph->物理执行图
(4)并行度(Parallelism):特定算子的子任务(subtask)的个数
算子之间传输数据的形式:One-to-one类似于窄依赖,Redistributing类似于宽依赖
(5)任务链(OperatorChains):相同并行度的One-to-one操作算子,形成一个task,减少线程之间的切换和基于缓存区的数据交换
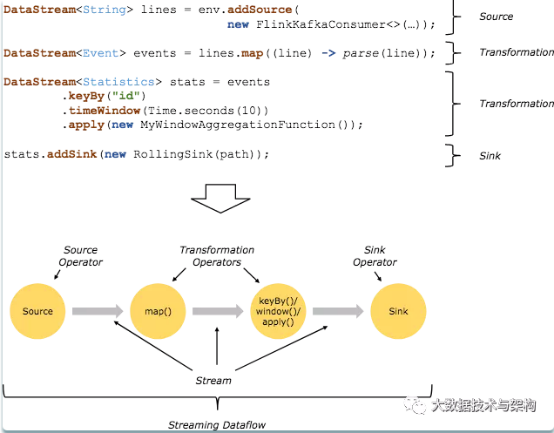
7、Flink的基础编程模型
Flink 程序的基本构建是数据输入来自一个 Source,Source 代表数据的输入端,经过 Transformation 进行转换,然后在一个或者多个Sink接收器中结束。
数据流(stream)就是一组永远不会停止的数据记录流,而转换(transformation)是将一个或多个流作为输入,并生成一个或多个输出流的操作。
执行时,Flink程序映射到 streaming dataflows,由流(streams)和转换操作(transformation operators)组成。
【大数据面试】Flink 01 概述:包含内容、层次架构、运行组件、部署模式、任务提交流程、任务调度概念、编程模型组成的更多相关文章
- 【大数据面试】【框架】Hive:架构、计算引擎、比较、内外部表、by、函数、优化、数据倾斜、动静态分区
一.组成 1.架构 源数据原本是存在dubby数据库,存在MySQL可以支持多个客户端 客户端.数据存储(HDFS).MR计算引擎 2.计算引擎的选择 MR引擎:基于磁盘,计算时间长,但一定能算出结果 ...
- 面试系列二:精选大数据面试真题JVM专项-附答案详细解析
公众号(五分钟学大数据)已推出大数据面试系列文章-五分钟小面试,此系列文章将会深入研究各大厂笔面试真题,并根据笔面试题扩展相关的知识点,助力大家都能够成功入职大厂! 大数据笔面试系列文章分为两种类型: ...
- 大数据及Hadoop的概述
一.大数据存储和计算的各种框架即工具 1.存储:HDFS:分布式文件系统 Hbase:分布式数据库系统 Kafka:分布式消息缓存系统 2.计算:Mapreduce:离线计算框架 stor ...
- Laxcus大数据管理系统2.0(12)- 第十章 运行
第十章 运行 本章将介绍一些Laxcus集群基本运行.使用情况,结合图片和表格表示.地点是我们的大数据实验室,使用我们的实验集群.数据来自于我们的合作伙伴,软件平台混合了Windows和Fedora ...
- 【大数据】Summingbird(Storm + Hadoop)的demo运行
一.前言 为了运行summingbird demo,笔者走了很多的弯路,并且在国内基本上是查阅不到任何的资料,耗时很久才搞定了demo的运行.真的是一把辛酸泪,有兴趣想要研究summingbird的园 ...
- 【大数据面试】Flink 04:状态编程与容错机制、Table API、SQL、Flink CEP
六.状态编程与容错机制 1.状态介绍 (1)分类 流式计算分为无状态和有状态 无状态流针对每个独立事件输出结果,有状态流需要维护一个状态,并基于多个事件输出结果(当前事件+当前状态值) (2)有状态计 ...
- 【大数据面试】Flink 03-窗口、时间语义和水印、ProcessFunction底层API
三.窗口 1.窗口的介绍 (1)含义 将无限的流式数据切割为有限块处理,以便于聚合等操作 (2)图解 2.窗口的分类 (1)按性质分 Flink 支持三种划分窗口的方式,time.count和会话窗口 ...
- 【大数据面试】Flink 02 基本操作:入门案例、Env、Source、Transform、数据类型、UDF、Sink
二.基本操作 1.入门案例 (1)批处理wordcount--DataSet val env = ExecutionEnvironment.getExecutionEnvironment // 从文件 ...
- Hadoop大数据面试--Hadoop篇
本篇大部分内容參考网上,当中性能部分參考:http://blog.cloudera.com/blog/2009/12/7-tips-for-improving-mapreduce-performanc ...
随机推荐
- Logstash:如何使用Elasticsearch,Logstash和Kibana管理Apache日志
- Elasticsearch:mapping定制
- KVM下virtio驱动虚拟机XML配置文件分析
[root@opennebula qemu]# pwd /etc/libvirt/qemu [root@opennebula qemu]# ls networks one-12.xml one-12. ...
- 采用阿里云 yum的方式安装ceph
首先机器需要联网,并且配置网络yum源,epel源,可从阿里开源镜像站中下载源文件. 注:EPEL (Extra Packages for Enterprise Linux)是基于Fedora的一个项 ...
- cAdvisor容器监控规则
其他说明参考host主机监控规则:https://www.cnblogs.com/sanduzxcvbnm/p/13589848.html 在prometheus主程序目录下的rules目录下新建do ...
- electron 基础
electron 基础 前文我们快速的用了一下 electron.本篇将进一步介绍其基础知识点,例如:生命周期.主进程和渲染进程通信.contextBridge.预加载(禁用node集成).优雅的显示 ...
- PAT (Basic Level) Practice 1014 福尔摩斯的约会 分数 20
大侦探福尔摩斯接到一张奇怪的字条: 我们约会吧! 3485djDkxh4hhGE 2984akDfkkkkggEdsb s&hgsfdk d&Hyscvnm 大侦探很快就明白了,字 ...
- go使用JWT进行跨域认证最全教学
JWT前言 JWT是JSON Web Token的缩写.JWT本身没有定义任何技术实现,它只是定义了一种基于Token的会话管理的规则,涵盖Token需要包含的标准内容和Token的生成过程. JWT ...
- HDU2586 How far away ? (树链剖分求LCA)
用树链剖分求LCA的模板: 1 #include<iostream> 2 #include<algorithm> 3 using namespace std; 4 const ...
- Spring 深入——IoC 容器 01
IoC容器的实现学习--01 目录 IoC容器的实现学习--01 简介 IoC 容器系列的设计与实现:BeanFactory 和 ApplicationContext BeanFactory load ...