【大数据面试】【框架】Hive:架构、计算引擎、比较、内外部表、by、函数、优化、数据倾斜、动静态分区
一、组成
1、架构
源数据原本是存在dubby数据库,存在MySQL可以支持多个客户端
客户端、数据存储(HDFS)、MR计算引擎
2、计算引擎的选择
MR引擎:基于磁盘,计算时间长,但一定能算出结果【一般用于计算周指标、月指标、年指标,一个任务3-5天】
tez引擎:基于内存,计算时间快,如果宕机,数据直接丢掉【一般用于临时调试,但容易出现OOM】
Spark引擎:既基于内存,也会落盘,居中【一般用于每天的定时任务】
二、与MySQL/Hbase的区别
hive MySQL Hbase
1、数据量大小 大 小
2、速度 数据量大/快 数据量小/慢
3、擅长 查询 增删改查 擅长插入不擅长查询
三、内部表和外部表的区别【出现频率最高&最简单】
1、最重要-元数据、原始数据
删除数据的时候,内部表会将元数据和原始数据全部删除,外部表只会删除元数据,原始数据不会被删除
2、在公司生产环境下,什么情况创建内部表,什么情况创建外部表
先导入hdfs,再将hdfs与hive表进行关联
绝大多数场景都是创建外部表【多个人共同使用】
只有在自己使用的临时表时,才会创建内部表
四、四个by
1、用法
order by:全局排序,针对自己用的临时表
sort by:排序
distribute by:分区
c:排序和分区字段相同时使用
5、在生产环境下
是否使用order by
不用,全局排序,数据量比较大
京东40-50T内存,都会OOM
s+d用的比较多:主要是在分区内部进行排序,效果最佳
c用的也会比较少
五、函数
1、系统函数
时间相关(日、月、周的处理)
日:date_add date_sub
周:next_day
月:date_format last_day
解析json☆:get_json_object
2、自定义函数
(1)组成
自定义UDF:项目中使用UDF解析公共字段
自定义UDTF:项目中使用UDTF解析具体的事件字段
自定义UDAF(spark)
(2)如果项目中不使用UDAF和UDTF能否对数据解析?
可以用系统函数,get_json_object【不定义】
(3)用系统函数能解决,为什么还要自定义
如果使用系统函数,解析失败只会抛出异常,不会抛出因为什么原因没解析出来
而自定义的方式,可以将每一个过程日志打印出来【更灵活,方便调试】
(4)自定义UDF步骤
定义一个类,继承UDF,重写内部的evaluate方法(实现其业务逻辑)
(5)自定义UDTF的步骤
定义一个类,继承GenericUDTF,重写内部的初始化、process、stop
(5)使用步骤
打包 =》上传到集群 =》在hive里面创建永久函数
3、窗口函数☆
rank
over
需要手写topn☆(使用开窗的方式)
六、Hive的优化
1、mapjoin
默认是打开的,不要关闭
2、行列过滤
出题形式,join where==》优化后先where后join
能提前过滤就提前过滤,再进行join操作
3、创建分区表
分桶【少】:对数据不太清楚时(不同key数据量不同,将key打散,对数据分组采样,)【分区表的优化手段】
分区表更常见
4、小文件处理
combinInputformat减少切片,进而减少map task,从而减少内存分配
开启JVM重用
采用merge的方式:
针对maponly的任务,默认打开-执行完任务后,会将小于16M的文件合并到256M(hive的块大小)
针对MapReduce任务,需要打开merge功能
5、合理设置map个数和reduce个数
map个数怎么设置:切片的大小-规则为max(0, min(块大小, Long的最大值))
128M数据对应1G内存
6、压缩
好处:减少磁盘所占的空间,减少网络传输
坏处:增加了解压缩计算
7、采用列式存储ORC/parquet
好处:提高查询效率,提高压缩比例 100G==> 10G ==》5-6G
如:
id name age
1 zhangsan 15
2 lisi 18
行存:1 zhangsan 15,2 lisi 18
select age from user,属于随机存储
列式存储:1 2 zhangsan lisi 15 18
select age from user,直接取 15 18,属于顺序读写
8、在reduce端开启combiner
要求不能影响最终的业务逻辑
七、数据倾斜
1、数据倾斜的表现
hql发生在reduce聚合时
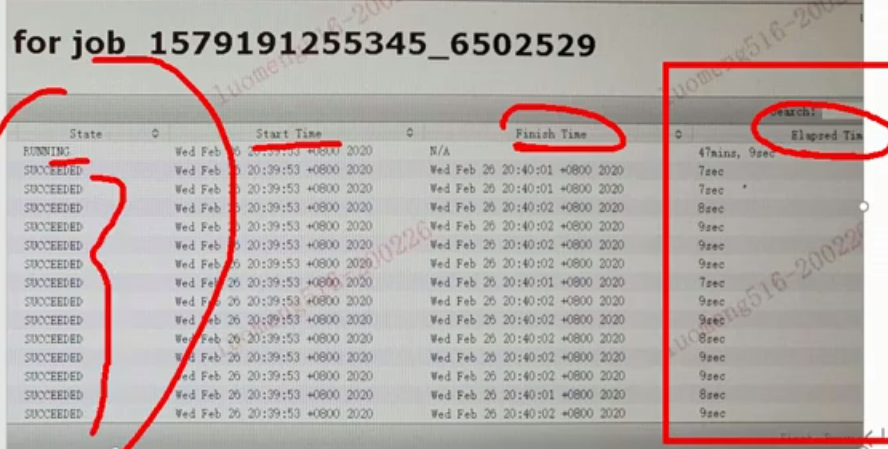
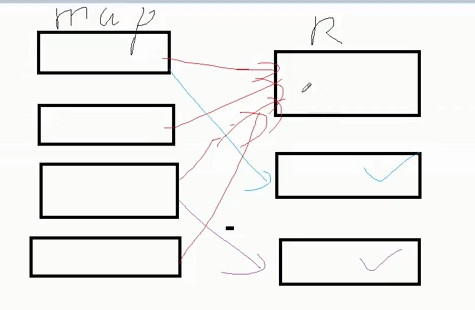
2、什么情况下会产生数据倾斜
不同数据类型关联产生数据倾斜(用户表中的id为int类型,log表中定义的用户id是string类型,两张表进行join操作时,数据不匹配,所有数据进入同一个reduce,其他都为空)
解决方式:

3、如何解决数据倾斜
(1)group by由于distinct group by
(2)在map端对数据进行join
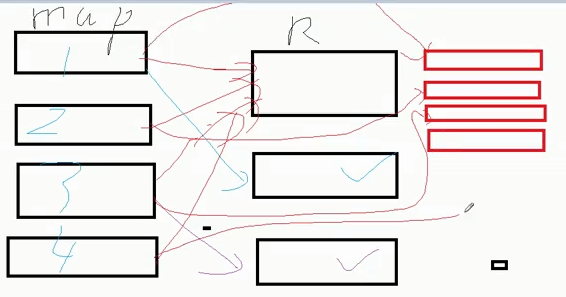
(3)开启数据倾斜时负载均衡

数据倾斜时,对reduce任务拆分,加随机数把数据打散,拆成多个reduce
将多个执行的reduce重新聚合,按照groupby,将同一个key的聚合为一个reduce
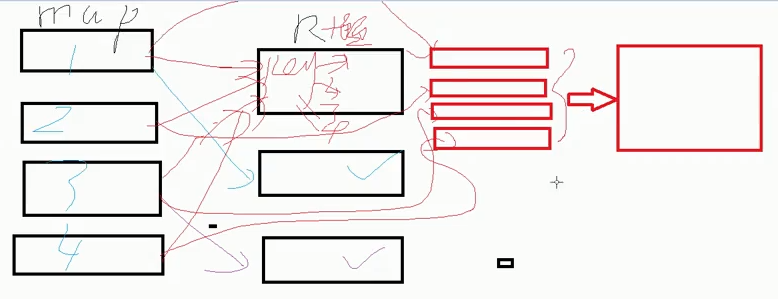
(4)控制数据分布,避免数据倾斜【类型不一致/空值】
默认值为空数据的值很大,可以在后面加随机数
将空值的分配一个特殊的值

八、hql练习
1、用的是动态分区吗,动态分区的底层原理
静态分区
insert overwrite table1 patition(dt=2021-12-14)
select age, name from user
动态分区
insert overwrite table1 patition(dt)
select age, name,dt from user
或
select age, name,'2021-12-14' from user
2、各自特点
静态是编译期时用户传递过来的
动态分区是执行SQL语句的时候才会决定(动态添加的值)
3、hive的字段分隔符
默认分隔符是\001,即^A
咱们使用的是\t
能否采用\abc作为分隔符
能,按照规范,前面不要出现这些字段,
如果出现,会产生什么后果
抛异常、类型不匹配(转换异常)
出现了,要对其进行转义,转义为普通的字符
【大数据面试】【框架】Hive:架构、计算引擎、比较、内外部表、by、函数、优化、数据倾斜、动静态分区的更多相关文章
- hive,分桶,内外部表,分区
简单的word-count操作: [root@master test-map]# head -10 The_Man_of_Property.txt #先看看数据Preface“The Forsy ...
- Hive:动静态分区
http://hugh-wangp.iteye.com/blog/1612268 http://blog.csdn.net/opensure/article/details/46537969 使用静态 ...
- FastAPI框架入门 基本使用, 模版渲染, form表单数据交互, 上传文件, 静态文件配置
安装 pip install fastapi[all] pip install unicorn 基本使用(不能同时支持,get, post方法等要分开写) from fastapi import Fa ...
- 入门大数据---Hive计算引擎Tez简介和使用
一.前言 Hive默认计算引擎时MR,为了提高计算速度,我们可以改为Tez引擎.至于为什么提高了计算速度,可以参考下图: 用Hive直接编写MR程序,假设有四个有依赖关系的MR作业,上图中,绿色是Re ...
- 揭秘阿里云EB级大数据计算引擎MaxCompute
日前,全球权威咨询与服务机构Forrester发布了<The Forrester WaveTM: Cloud Data Warehouse, Q4 2018>报告.这是Forrester ...
- 大数据技术之Hive
第1章 Hive入门 1.1 什么是Hive Hive:由Facebook开源用于解决海量结构化日志的数据统计. Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提 ...
- 奇点云数据中台技术汇(三)| DataSimba系列之计算引擎篇
随着移动互联网.云计算.物联网和大数据技术的广泛应用,现代社会已经迈入全新的大数据时代.数据的爆炸式增长以及价值的扩大化,将对企业未来的发展产生深远的影响,数据将成为企业的核心资产.如何处理大数据,挖 ...
- 【大数据面试】Hbase:数据、模型结构、操作、读写数据流程、集成、优化
一.概述 1.概念 分布式.可扩展.海量数据存储的NoSQL数据库 2.模型结构 (1)逻辑结构 store相当于某张表中的某个列族 (2)存储结构 (3)模型介绍 Name Space:相当于数据库 ...
- 【HBase】简介、结构、数据模型、快速入门部署、shell操作、架构原理、读写数据流程、数据刷写、压缩、分割、Phoenix、表的映射、与hive集成、优化
一.简介 1.定义 分布式.可扩展.支持海量数据存储的NoSQL数据库 2.数据模型 2.1逻辑结构 2.2物理存储结构 2.3数据模型介绍 Name Space:相当于数据库,包含很多张表 Regi ...
随机推荐
- Pod 的生命周期
上图展示了一个 Pod 的完整生命周期过程,其中包含 Init Container.Pod Hook.健康检查 三个主要部分,接下来我们就来分别介绍影响 Pod 生命周期的部分: 首先在介绍 Pod ...
- MySQL一致性读原来是有条件的
众所周知,在设定了隔离等级为Repeatable Read及以上时,InnoDB 可以实现数据的一致性读.换句话来说,就是事务执行的任意时刻,读取到的数据是同一个快照,不会受到其他事务的更新影响. 以 ...
- 使用Filebeat传送多行日志
文章转载自:https://blog.csdn.net/UbuntuTouch/article/details/106272704 在解决应用程序问题时,多行日志为开发人员提供了宝贵的信息. 堆栈跟踪 ...
- 监控MySQL运行状态:MySQLD Exporter
具体监控配置详看这篇文章:https://www.cnblogs.com/sanduzxcvbnm/p/13094580.html 为了确保数据库的稳定运行,通常会关注一下四个与性能和资源利用率相关的 ...
- 详解JS中 call 方法的实现
摘要:本文将全面的,详细解析call方法的实现原理 本文分享自华为云社区<关于 JavaScript 中 call 方法的实现,附带详细解析!>,作者:CoderBin. 本文将全面的,详 ...
- .NET 5 设计 API (资源站)
跟新于 2022-11日 数据抓取端 随着数据的增多,问题也越来越多 用redis 主要是为了 以后进行,多个数据库写入. 例如我搭建一个 别的数据库论坛,我直接拿数据去redis里面拿,就不用跨库查 ...
- Linux 下搭建 HBase 环境
Linux 下搭建 HBase 环境 作者:Grey 原文地址: 博客园:Linux 下搭建 HBase 环境 CSDN:Linux 下搭建 HBase 环境 前置工作 首先,需要先完成 Linux ...
- 齐博X1数据表之系统参数
https://v.youku.com/v_show/id_XMzg0MTEzMzEyOA== 不会插入视频 直接发 优酷地址吧= =!
- python3使用mutagen进行音频元数据处理
python版本:python 3.9 mutagen版本:1.46.0 mutagen是一个处理音频元数据的python模块,支持多种音频格式,是一个纯粹的python库,仅依赖python标准 ...
- rocky二进制安装mysql8.0
(ubuntu的有点问题) 点击查看代码 #!/bin/bash Version=`cat /etc/os-release |awk -F'"| ' '/^NAME/{print $2}'` ...