使用Puppeteer进行数据抓取(三)——简单的示例
本文以一个示例简单的介绍一下puppeteer的用法,我们的目的是:获取我博客上的文章的前十页的所有随笔的标题和链接。由于puppeteer本身是自动化chorme,因此这里我们的步骤和手动操作浏览器差不多:
- 打开chrome,跳转到博客首页
- 获取所有博客标题信息
- 点击下一页按钮,跳转到下一页
- 重复2、3两步,直到所有信息采集完毕
获取信息
采集过程中比较麻烦的一步就是信息的采集,和传统采集html后解析的方式不同的时,由于chrome本身有完整的js引擎,因此我们采用注入一段js,利用该js采集到我们的信息,并通过puppeteer返回给应用程序的方式。由于puppete本身是采用的chrome,因此编写采集信息函数这一过程完全可以在chrome上进行。
首先用chrome打开我的博客的首页http://www.cnblogs.com/TianFang/,打开chrome devtool,获取标题的css path。然后我们可以利用chrome的snippets简单的写一个获取所有标题信息的函数:
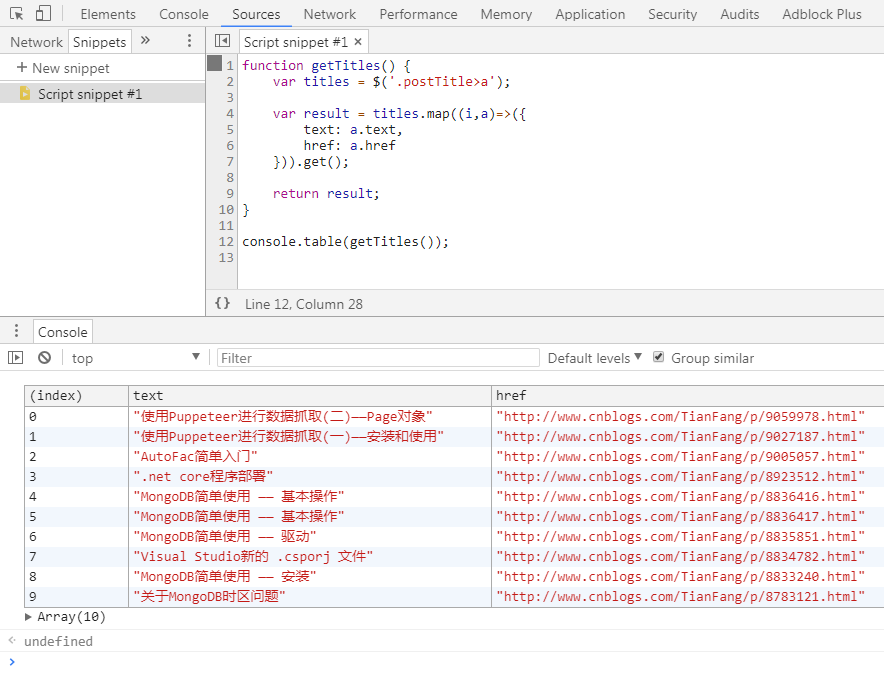
本身就蜘蛛程序而言,编写获取脚本内容的这个部分是比较繁琐的,需要不断的反复调试。但使用snippets直接编写函数大大简化了这一过程,它的主要好处有:
- 可以直接使用各种js函数,可以直接操作各种dom对象
- 利用snippets编写可以在chrome中实时调试,
- 可以实时查看生成结果
然后我们只需要将这个函数放到node中,利用puppeteer跳转到相应的页面,使用page.evaluate函数执行这个函数即可。
async function getTitles() {
var titles = $('.postTitle>a');
var result = titles.map((i, a) => ({
text: a.text,
href: a.href
})).get();
console.table(result);
return result;
}
var titles = await page.evaluate(getTitles);
console.log(titles);
一个需要注意的地方是,这个函数实际上是在chrome中执行的,puppeteer要求在chrome中执行的函数必须是异步的,因此需要加上async关键字。
页面跳转
下一步需要解决的问题就是如何跳转到下一页了。方法也比较简单:分析一下页面,找到下一页的连接,执行js模拟点击即可:
page.evaluate(async() => $(`a:contains('下一页')`)[0].click());
完整代码如下:
const puppeteer = require('puppeteer');
const chrome_exe = String.raw`${process.env["ProgramFiles(x86)"]}\Google\Chrome\Application\chrome.exe`;
const user_data_path = String.raw`${process.env.LocalAppData}\Google\Chrome\User Data\Default`;
async function run() {
const browser = await puppeteer.launch({
headless: false,
userDataDir: user_data_path,
executablePath: chrome_exe
});
const page = await browser.newPage();
page.setViewport({ width: 1600, height: 900 });
await page.goto('http://www.cnblogs.com/TianFang');
for (var i = 0; i < 10; i++) {
console.log(i);
console.log(page.url());
var titles = await page.evaluate(getTitles);
console.log(titles);
await page.evaluate(async() => $(`a:contains('下一页')`)[0].click());
await page.waitForNavigation();
await sleep(1000);
}
};
async function getTitles() {
var titles = $('.postTitle>a');
var result = titles.map((i, a) => ({
text: a.text,
href: a.href
})).get();
console.table(result);
return result;
}
async function sleep(timeout) {
return new Promise(resolve => setTimeout(resolve, timeout));
}
run();
整个过程还是非常简单的, 执行结果如下:
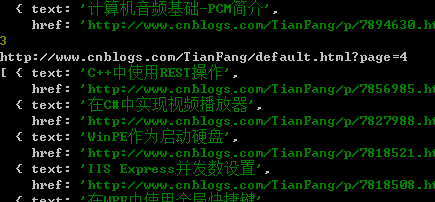
另外值得一提的是,细心的朋友可能注意到这里我们编写一个可以await的sleep函数。
async function sleep(timeout) {
return new Promise(resolve => setTimeout(resolve, timeout));
}
这个函数本身不是必须的,但在编写蜘蛛程序过程中却经常需要等待的,使用await异步等待可以大大提高代码的可读性,由于node本身没有提供可以await的sleep函数。并且这个函数非常实用,这里就自己实现了一个,记录一下,以备以后使用。
使用Puppeteer进行数据抓取(三)——简单的示例的更多相关文章
- 使用Puppeteer进行数据抓取(一)——安装和使用
Puppeteer是 Google Chrome 团队官方的Chrome 自动化工具.它本身是基于Chrome Dev Protocol协议实现的,但它提供了更高层次API封装,使用起来更加方便快捷. ...
- 使用Puppeteer进行数据抓取(二)——Page对象
page对象是puppeteer最常用的对象,它可以认为是chrome的一个tab页,主要的页面操作都是通过它进行的.Google的官方文档详细介绍了page对象的使用,这里我只是简单的小结一下. 客 ...
- 使用Puppeteer进行数据抓取(四)——图片下载
大多数情况下,图片获取并不是很困难的事情,获取图片的url,然后模拟浏览器请求即可.但是,有的时候这种方法往往无法生效,常见的情形有: 动态图片,每次获取都是一个新的,例如图片验证码,重新获取时是一个 ...
- 使用Puppeteer进行数据抓取(四)——快速调试
在我们使用chrome作为爬虫获取网页数据时,往往需如下几步. 打开chrome 导航至目标页面 等待目标页面加载完成 解析目标页面数据 保存目标页面数据 关闭chrome 我们实际的编码往往集中在第 ...
- Twitter数据抓取
说明:这里分三个系列介绍Twitter数据的非API抓取方法.有兴趣的QQ群交流: BitCrawler网络爬虫QQ群 322937592 1.Twitter数据抓取(一) 2.Twitter数据抓取 ...
- 网页数据抓取工具,webscraper 最简单的数据抓取教程,人人都用得上
Web Scraper 是一款免费的,适用于普通用户(不需要专业 IT 技术的)的爬虫工具,可以方便的通过鼠标和简单配置获取你所想要数据.例如知乎回答列表.微博热门.微博评论.淘宝.天猫.亚马逊等电商 ...
- 【Python入门只需20分钟】从安装到数据抓取、存储原来这么简单
基于大众对Python的大肆吹捧和赞赏,作为一名Java从业人员,我本着批判与好奇的心态买了本python方面的书<毫无障碍学Python>.仅仅看了书前面一小部分的我......决定做一 ...
- 数据抓取的艺术(三):抓取Google数据之心得
本来是想把这部分内容放到前一篇<数据抓取的艺术(二):数据抓取程序优化>之中.但是随着任务的完成,我越来越感觉到其中深深的趣味,现总结如下: (1)时间 时间是一个与抓取规模相形而 ...
- python-requests 简单实现数据抓取
安装包: requests,lxmlrequest包用于进行数据抓取,lxml用来进行数据解析对于对网页内容的处理,由于html本身并非如数据库一样为结构化的查询所见即所得,所以需要对网页的内容进行分 ...
随机推荐
- 20145234黄斐《Java程序设计》第八周
教材学习内容总结 第十四章-NIO与NIO2 NIO与IO的区别 NIO Channel继承框架 想要取得Channel的操作对象,可以使用Channels类,它定义了静态方法newChannel() ...
- [转]linux各文件夹介绍
本文来自linux各文件夹的作用的一个精简版,作为个人使用笔记. 下面简单看下linux下的文件结构,看看每个文件夹都是干吗用的? /bin 二进制可执行命令 /dev 设备特殊文件 /etc 系统管 ...
- 使用 scm-manager 搭建 git/svn 代码管理仓库(二)
主要介绍scm的配置. 1.配置为在Windows服务中启动scm-manager的启动方式有多种,可以在DOS(即命令行CMD模式)中启动,也可以在Windows服务中启动. 下面我们采用Windo ...
- Contrastive Loss (对比损失)
参考链接:https://blog.csdn.net/yanqianglifei/article/details/82885477 https://blog.csdn.net/qq_37053885/ ...
- blockchain 名词解释
1.UTXO UTXO是比特币交易的基本单位UTXO(Unspent Transaction Outputs)是未花费的交易输出,它是比特币交易生成及验证的一个核心概念.交易构成了一组链式结构,所有合 ...
- Centos6.5下升级Python版本
Cenos6.5升级Python2.6到2.7 1.下载源码包 wget https://www.python.org/ftp/python/2.7.12/Python-2.7.12.tgz 2.进行 ...
- sort命令的k选项大讨论【转】
本原创文章属于<Linux大棚>博客,博客地址为http://roclinux.cn.文章作者为rocrocket. 为了防止某些网站的恶性转载,特在每篇文章前加入此信息,还望读者体谅. ...
- mavean项目的jar位置的影响
由于项目的数据库需求改变了,有mysql数据库变为oracle的,那么对于项目就是需要改变数据库连接池.这个项目运用了mavean框架,那么下载jar在pom.xml文件中填写就可以了,但是oracl ...
- ElastAlert告警
ElastAlert告警 https://blog.csdn.net/qq_38369069/article/details/80842432
- python 实现远端ftp文件上传下载
python 实现ftp上传下载 * 脚本需要传入两个参数,参数1为需要从远端ftp站点下载文件名称,参数2为已知需要下载的文件md5值,文件下载完成后会自动进行md5值校验 * 运行示例 [root ...