Spark2.3文档翻阅的一点简略笔记(WaterMarking)
写本文原因是之前已经将官网文档阅读过几遍,但是后来工作接触spark机会较少所以没有跟进新特性,利用周末一点闲暇时间粗略阅读一篇,将自己之前遇见过的问题解决过的问题印象不深刻的问题做一下记录。
1关于RDD缓存:
Don’t spill to disk unless the functions that computed your datasets are expensive, or they filter a large amount of the data. Otherwise, recomputing a partition may be as fast as reading it from disk. 除非生成RDD的计算逻辑非常复杂,否则不要溢写到磁盘,性能低。当数据丢失重新计算都比读取磁盘快。
2 spark 加速器新特性:
While this code used the built-in support for accumulators of type Long, programmers can also create their own types by subclassing AccumulatorV2. The AccumulatorV2 abstract class has several methods which one has to override: reset for resetting the accumulator to zero, add for adding another value into the accumulator, merge for merging another same-type accumulator into this one. Other methods that must be overridden are contained in the API documentation. For example, supposing we had a MyVector class representing mathematical vectors, we could write:
支持新的方法,reset,merg等方法;reset将加速器置0,merge方法用于合并另一个类型相同的加速器。
注意:
For accumulator updates performed inside actions only, Spark guarantees that each task’s update to the accumulator will only be applied once, i.e. restarted tasks will not update the value. In transformations, users should be aware of that each task’s update may be applied more than once if tasks or job stages are re-executed.
Accumulators do not change the lazy evaluation model of Spark. If they are being updated within an operation on an RDD, their value is only updated once that RDD is computed as part of an action. Consequently, accumulator updates are not guaranteed to be executed when made within a lazy transformation like map().
核心要点是:
加速器只有在action算子执行时候才会真正运算,加速器不会改变Spark的延迟计算模型。例如错误代码:
val accum = sc.longAccumulator
data.map { x => accum.add(x); x }
// Here, accum is still 0 because no actions have caused the map operation to be computed.
3:Spark使用Spark提供的API进行提交作业
Launching Spark jobs from Java / Scala
The org.apache.spark.launcher package provides classes for launching Spark jobs as child processes using a simple Java API.
4:关于Structured Streaming文档新特性
Structured Streaming在Spark2.3之前是一款基于Sparl SQL引擎的流处理计算引擎,将流数据抽象为意向无界限的表,每当有流数据到来时候进行追加或者更新结果;但是当Spark2.3的到到来,Spark提供了一种新的连续更低延迟的连续流处理引擎,直白说就是不是基于微批次的而是真正的流处理引擎。
官方文档原文:
Internally, by default, Structured Streaming queries are processed using a micro-batch processing engine, which processes data streams as a series of small batch jobs thereby achieving end-to-end latencies as low as 100 milliseconds and exactly-once fault-tolerance guarantees. However, since Spark 2.3, we have introduced a new low-latency processing mode called Continuous Processing, which can achieve end-to-end latencies as low as 1 millisecond with at-least-once guarantees. Without changing the Dataset/DataFrame operations in your queries, you will be able to choose the mode based on your application requirements.
5:Structured Streaming处理流数据的过程
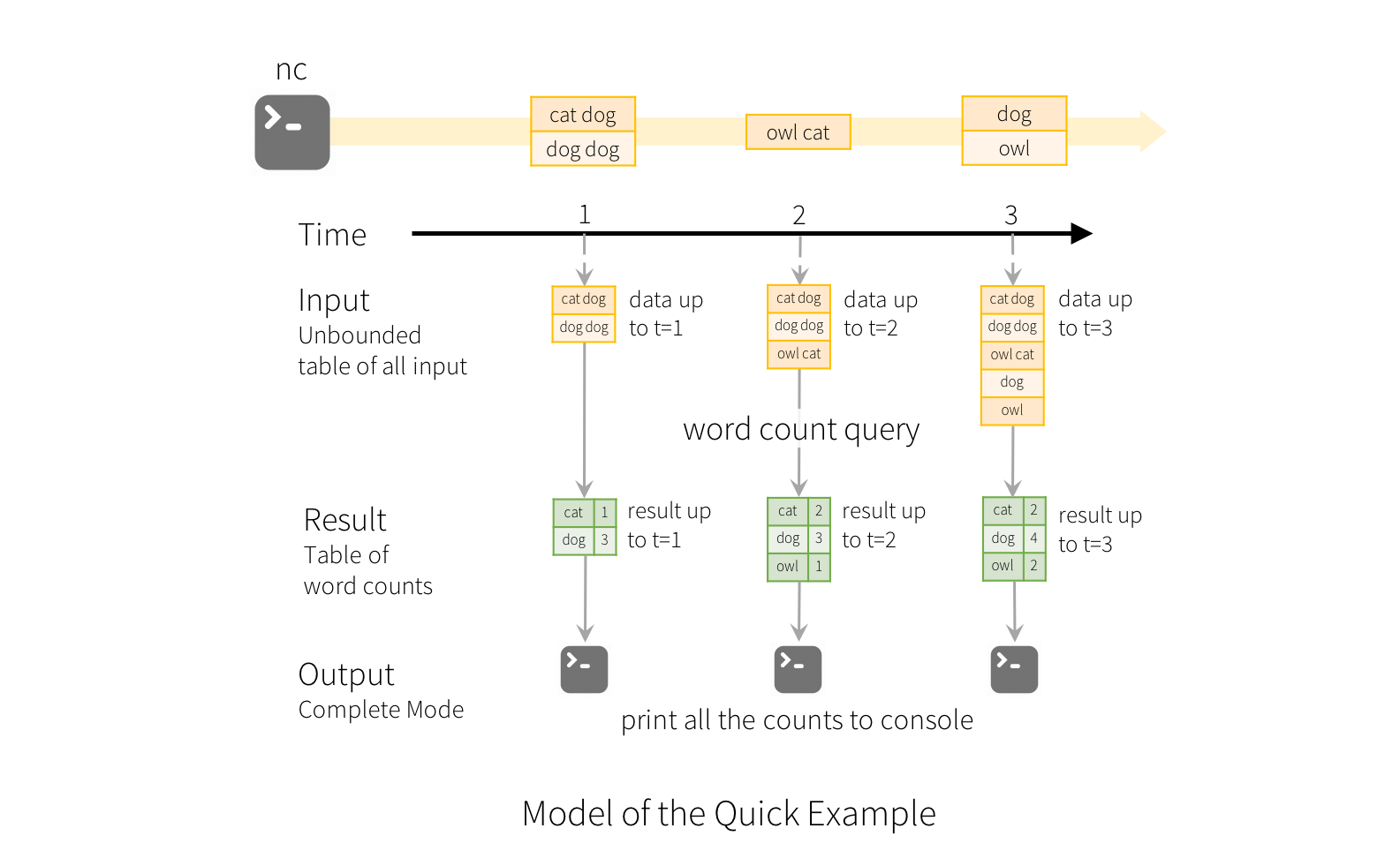
Spark并不保存输入的数据,处理完毕新到来的流数据之后便开始进行回收新数据,只保存新到来的流数据的状态信息(对于wordcount而言就是新来的数据的wordcount结果,然后这部分结果更新到ResultTable中)。原文:
Note that Structured Streaming does not materialize the entire table. It reads the latest available data from the streaming data source, processes it incrementally to update the result, and then discards the source data.it only keeps around the minimal intermediate state data as required to update the result 。
延迟数据的处理:对于迟到的数据处理spark也是用watermarking机制,watermarking就是允许延迟的时间阈值,spark根据这个阈值进行清除中间状态数据。
6:关于WaterMarking原文:
a: watermarking是什么?
Since Spark 2.1, we have support for watermarking which allows the user to specify the threshold of late data, and allows the engine to accordingly clean up old state.
译文:指定的延迟阈值的数值并不是watermark,延迟时间阈值是一个单独的参数用于指定可以接受的延迟。watermark最重要的用途让计算引擎根据watermark进行清理不必要的中间状态,watermark=计算引擎看见的最大eventtime-延迟时间阈值。当迟到的数据在watermark之前的话则就放弃,否则进行处理。估计你们看着有点难懂:举个例子,例如此时watermark=12:05,突然来一个记录的时间是12:03,此时该记录将会被丢失,因为12:05之前的中间数据已经被清除,但是如果迟到的记录时间是12:06的话则就可以被正常处理。
例如图:

图中迟到的记录 (12:04 donkey)看到的watermark=12:11,12:04记录属于12:00-12:10窗口中,但是由于12:11之前的数据都被清除了,所以12:00-12:10数据被清除,所以12:04的数据是无法被处理的,因此丢丢弃。
b: watermarking如何工作?
In other words, late data within the threshold will be aggregated, but data later than the threshold will start getting dropped .
7:Continuous Processing
Continuous Processing是一个新的计算引擎,是一个真正的连续流处理引擎,高容错,低延迟等特性,但是一次性语义保证是:最少一次,即: at-least-once。
Spark2.3文档翻阅的一点简略笔记(WaterMarking)的更多相关文章
- css文档之盒模型阅读笔记
前段时间抽空仔细阅读了w3c的css文档关于盒模型方面的一些基础知识.边读边记录了一些要点,在此做些整理,与大家分享,如有理解有误之处,请不吝指教. 1.综述 文档中的每个元素被描绘为矩形盒子.渲染引 ...
- 基于swagger进行接口文档的编写
0. 前言 近期忙于和各个银行的代收接口联调,根据遇到的问题,对之前编写的接口进行了修改,需求收集和设计接口时想到了方方面面,生产环境下还是会遇到意想不到的问题,好在基本的执行逻辑已确定,因此只是对接 ...
- java简单实现用语音读txt文档
最近比较无聊,随便翻着博客,无意中看到了有的人用VBS读文本内容,也就是读几句中文,emmm,挺有趣的,实现也很简单,都不需要安装什么环境,直接新建txt文件,输入一些简单的vbs读文本的代码,然后将 ...
- Elasticsearch-如何控制存储和索引文档(_source、_all、返回源文档的某些字段)
Elasticsearch-如何控制存储和索引文档(_source._all) _source:可以在索引中存储文档._all:可以在单个字段上索引所有内容. 1. 存储原有内容的_source _s ...
- 下载网页中的 pdf 各种姿势,教你如何 carry 各种网页上的 pdf 文档。
关联词: PDF 下载 FLASH 网页 HTML 报告 内嵌 浏览器 文档 FlexPaperViewer swfobject. 这个需求是最近帮一个妹子处理一下各大高校网站里的 PDF 文档下载, ...
- 自定义WIZ文档模板
WIZ文档模板 1.在wiz笔记里面新建一个笔记,并将其做成一个模板 例子: 2.该作为模板的笔记制作完成后,右键-高级-另存为 导出为html格式 3.将导出的文件和文件夹(有时候只有一个htm文 ...
- 每天一点Linux-01文档系统
Windows: 以多根的方式组织文档 C: D: E:Linux: 以单根的方式组织文档 / /目录结构: FSH (Filesystem Hierarchy Standard) [root@yan ...
- DL4NLP —— seq2seq+attention机制的应用:文档自动摘要(Automatic Text Summarization)
两周以前读了些文档自动摘要的论文,并针对其中两篇( [2] 和 [3] )做了presentation.下面把相关内容简单整理一下. 文本自动摘要(Automatic Text Summarizati ...
- [转]OpenContrail 体系架构文档
OpenContrail 体系架构文档 英文原文:http://opencontrail.org/opencontrail-architecture-documentation/ 翻译者:@KkBLu ...
随机推荐
- MFC控件之Combo Box
下拉链表Combo-box Control 常用属性: Sort:对添加到列表框的字符串进行自动排序.(对指定位置的元素项无效) Type:有三个类型 Simple:没有下拉按钮,可以输入字符串,可以 ...
- java.lang.ClassCastException: java.lang.Short cannot be cast to java.lang.String(Short类型无法强转成String类型)
有一行Java代码如下: String code1 = (String)qTable1.getValueAt(i, 0); 这是一个Java的图形界面获取表格中值的代码,其中qTable1.getVa ...
- 畅通工程(hdu1863)并查集
畅通工程 Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Submi ...
- JavaScript中=、==、===以及!=、!==的区别与联系
JavaScript中=.==.===以及!=.!==的区别与联系 在JavaScript中,“=”代表赋值操作:“==”先转换类型再比较,“===”先判断类型,如果不是同一类型直接为false. ...
- 集合框架二(Collection接口实现类常用遍历方法)
四种常用遍历方式 Collection coll = new ArrayList(); coll.add("123"); coll.add("456"); co ...
- 从零开始学习html(十)CSS格式化排版——上
一.文字排版--字体 <!DOCTYPE HTML> <html> <head> <meta http-equiv="Content-Type&qu ...
- windows 10安装jdk8
1.下载jdk,选择jdk软件版本和对应windows 32/64位版本 jdk下载链接:https://www.oracle.com/technetwork/java/javase/download ...
- 简单CNN 测试例
1.训练数据: import tensorflow as tf import cv2 import os import numpy as np import time import matplotli ...
- cmd 命令总结
1.windows 系统定时关机 定时关机:shutdown -s -t 300 at 18:30 shutdown -s 取消定时:shutdown -a 注意:3 ...
- 互联网,IT,大数据,机器学习,AI知识tag云
互联网基础: tcp/ip网络,linux运维,DNS,ipv6 web前端: javascript, es6, 组件化开发, vuejs, angularjs, react html5, css3, ...