ELK日志平台
1、ELK平台能够完美的解决我们上述的问题,ELK由ElasticSearch、Logstash和Kibana三个开源工具组成,不过现在还新增了一个Beats,它是一个轻量级的日志收集处理工具(Agent),Beats占用资源少。
1)Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等
2)Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。工作方式为C/S架构,Client端安装在需要收集日志的主机上,Server端负责将收到的各节点日志进行过滤、修改等操作在一并发往Elasticsearch服务器。
3) Kibana也是一个开源和免费的工具,它Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志;
4)FileBeat是一个轻量级日志采集器,Filebeat属于Beats家族的6个成员之一,早期的ELK架构中使用Logstash收集、解析日志并且过滤日志,但是Logstash对CPU、内存、IO等资源消耗比较高,相比Logstash,Beats所占系统的CPU和内存几乎可以忽略不计
5) Logstash和Elasticsearch是用Java语言编写,而Kibana使用node.js框架,在配置ELK环境要保证系统有JAVA JDK开发库;
2、ELK工作原理
1)客户端安装Logstash日志收集工具,通过logstash收集客户端APP的日志数据,将所有的日志过滤出来,存入Elasticsearch 搜索引擎里,然后通过Kibana GUI在WEB前端展示给用户,用户需要可以进行查看指定的日志内容。同时也可以加入redis通信队列:

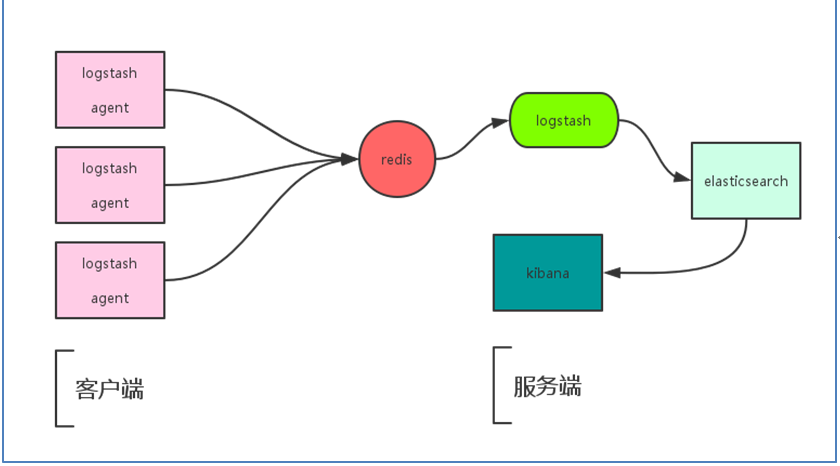
2)加入Redis队列后工作流程;
Logstash包含Index和Agent(shipper) ,Agent负责客户端监控和过滤日志,而Index负责收集日志并将日志交给ElasticSearch,ElasticSearch将日志存储本地,建立索引、提供搜索,kibana可以从ES集群中获取想要的日志信息。
3)ELFK工作流程
使用FileBeat获取Linux服务器上的日志。当启动Filebeat时,它将启动一个或多个Prospectors (检测者),查找服务器上指定的日志文件,作为日志的源头等待输出到Logstash。
Logstash从FileBeat获取日志文件。Filebeat作为Logstash的输入input将获取到的日志进行处理,Logstash将处理好的日志文件输出到Elasticsearch进行处理。
Elasticsearch得到Logstash的数据之后进行相应的搜索存储操作。将写入的数据可以被检索和聚合等以便于搜索操作,最后Kibana通过Elasticsearch提供的API将日志信息可视化的操作
ELK日志平台的更多相关文章
- elk日志平台搭建小记
最近抽出点时间,搭建了新版本的elk日志平台 elastaicsearch 和logstash,kibana和filebeat都是5.6版本的 中间使用redis做缓存,版本为3.2 使用的系统为ce ...
- Springboot项目使用aop切面保存详细日志到ELK日志平台
上一篇讲过了将Springboot项目中logback日志插入到ELK日志平台,它只是个示例.这一篇来看一下实际使用中,我们应该怎样通过aop切面,拦截所有请求日志插入到ELK日志系统.同时,由于往往 ...
- Springboot项目搭配ELK日志平台
上一篇讲过了elasticsearch和kibana的可视化组合查询,这一篇就来看看大名鼎鼎的ELK日志平台是如何搞定的. elasticsearch负责数据的存储和检索,kibana提供图形界面便于 ...
- ELK 日志平台构建
elastic中文社区 https://elasticsearch.cn/ 完整参考 ELK实时日志分析平台环境部署--完整记录 https://www.cnblogs.com/kevingrace/ ...
- 亿级 ELK 日志平台构建部署实践
本篇主要讲工作中的真实经历,我们怎么打造亿级日志平台,同时手把手教大家建立起这样一套亿级 ELK 系统.日志平台具体发展历程可以参考上篇 「从 ELK 到 EFK 演进」 废话不多说,老司机们座好了, ...
- 学习ELK日志平台(四)
一:需求及基础: 场景: 1.开发人员不能登录线上服务器查看详细日志 2.各个系统都有日志,日志数据分散难以查找 3.日志数据量大,查询速度慢,或者数据不够实时 4.一个调用会涉及到多个系统,难以在这 ...
- 学习ELK日志平台(二)
一.ELK介绍 1.1 elasticsearch 1.1.1 elasticsearch介绍 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索 ...
- 基于Docker的ELK日志平台搭建
1.安装Docker Docker可简单理解为一个轻量级的虚拟机.Docker对进程进行封装隔离,隔离的进程独立于宿主和其它的隔离的进程,因此也称其为容器.Docker和传统虚拟化方式的不同.传统虚拟 ...
- ELK日志平台搭建
功能: 1. 查看当天的服务器日志信息(要求:在出现警告甚至警告级别以上的都要查询)2. 能够查看服务器的所有用户的操作日志3. 能够查询nginx服务器采集的日志(kibana作图)4. 查看tom ...
随机推荐
- 用vlan实现同一网段的的各部门之间有的可以通信有的不可以通信
日前老师上课演示一个项目:实现公司同一网段的各个部门之间有的可以通信有的无法通信.我们用的是思科测试软件模拟操作,个人觉得很好用. 在刚开始做这个项目的时候我以为端口是对应的,如图,交换机 ...
- 使用Nginx+Lua实现自定义WAF
使用Nginx+Lua实现自定义WAF 版权声明:全部抄自赵班长的GitHub上waf项目 功能列表: 支持IP白名单和黑名单功能,直接将黑名单的IP访问拒绝. 支持URL白名单,将不需要过滤的URL ...
- linux设置服务器时间同步
yum install -y rdate 服务器请设置 */5 * * * * /usr/bin/rdate -s time-b.nist.gov ubuntu 设定时区:dpkg-reconfigu ...
- LRU简单实现
用LinkedHashMap来实现 package com.yin.purchase.dao; import java.util.ArrayList; import java.util.Collect ...
- Win/Lin 双系统时间错误的调整 (转)
Win/Lin 双系统时间错误的调整 http://jingyan.baidu.com/article/154b46317b25ca28ca8f41e8.html | 浏览:1070 | 更新:201 ...
- MySQL Developer
1.The mysql Client Program 2.Data Types 3.Joins 4.Subqueries 5.Views 6.StoredRoutine . 1.Client/Serv ...
- 学习笔记: js插件 —— fullPage.js (页面全屏滚动)
fullPage.js (页面全屏滚动) 必须依赖 jquery-ui.min.js, 233K 14760个星. 以后有时间再看. API挺全 https://github.com/alvaro ...
- 49.纯 CSS 创作一支诱人的冰棍
原文地址:https://segmentfault.com/a/1190000015257561 感想:重点在让色彩滚动起来->background-position: 0 1000vh; HT ...
- tensorflow 入门
1. tensorflow 官方文档中文版(下载) 2. tensorflow mac安装参考 http://www.tuicool.com/articles/Fni2Yr 3. 源码例子目录 l ...
- userdel 用户名 出现“用户**目前已登录”
userdel 用户名 出现“用户**目前已登录” 今天在删除用户账号的时候,发现一个奇怪现象,即: userdel: user newname is currently logged in 相关命令 ...