python(27) 抓取淘宝买家秀
selenium 是Web应用测试工具,可以利用selenium和python,以及chromedriver等工具实现一些动态加密网站的抓取。本文利用这些工具抓取淘宝内衣评价买家秀图片。
准备工作
下面先安装selenium,在命令行输入python,然后输入安装命令
1 |
pip install selenium |
安装chromedriver和chrome,二者版本需要对应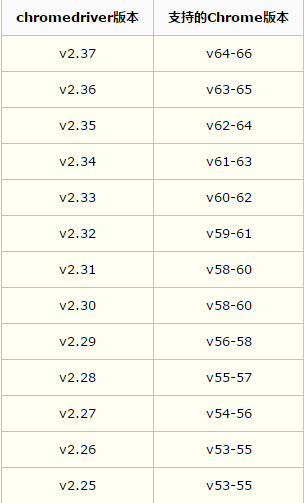
各版本下载地址
下载完成后解压,将exe放到你的python安装目录下的scripts目录下即可。
接下来分析网站,并且模拟登陆爬取数据,登陆淘宝,F12检测浏览器请求,F5刷新下,在network栏找到可以分析的几个网络请求,找到cookie
分析和编码
先根据cookie登陆淘宝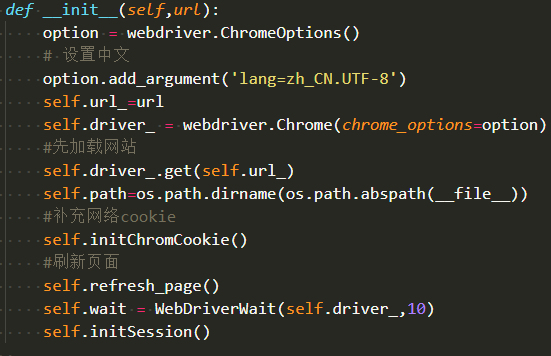
这段代码初始化了ChromeDriver的参数,然后根据cookie设置chrome选项,成功后刷新下页面,并且初始化reuests session,用于维持会话
初始化cookie代码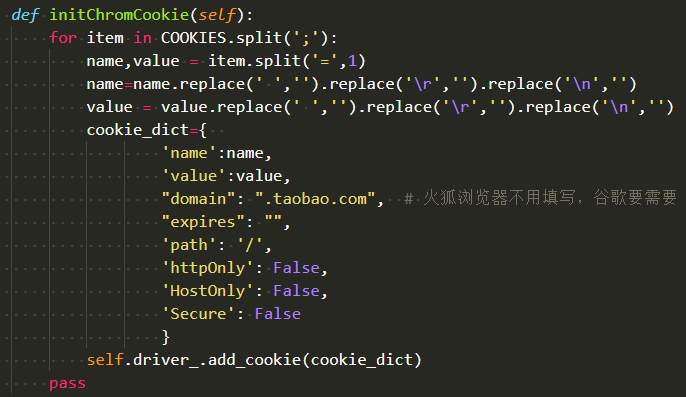
初始化session代码
这样利用cookie就能成功登陆淘宝了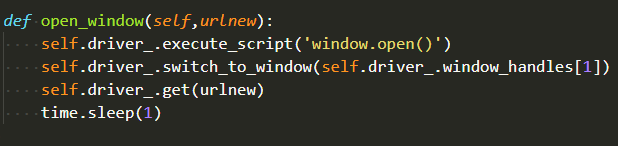
利用chromedriver打开了一个新窗口,然后访问指定的商品页面,接下来要做的都是点击累计评价,然后点击图片评价选择框。
累计评价的标签元素xpath在network中找到,可以通过find_element_by_xpath函数访问该标签,然后调用click函数就完成了点击,当然也可以通过presence_of_element_located超时等待查询,查不到指定标签就返回超时异常。相关接口调用比较简单,可以看看selenium基础查询和操作
python selenium api
代码功能是先点击评论,然后滚动1000像素位置,抓取找到评论区元素,根据评论区的图片元素找到资源地址,同时代码实现了自动点击下一页和判断末页功能。
代码找到了评论列表,然后将评论列表传给getPhoto函数,抓取每个评论图片,下面是抓取图片的核心代码。
def getPhoto(self,*comentlist):
try:
for comments in comentlist:
#print(len(comentlist))
#print(type(comments))
desc=comments.find_element_by_class_name('tm-rate-fulltxt').text
if len(desc) == 0:
desc='abcdef'
dirfix=desc[0:6]
dirname=os.path.join(self.path,dirfix)
if os.path.exists(dirname) == False:
os.makedirs(dirname)
txtname=os.path.join(dirname,desc[0:6]+'.txt')
if os.path.exists(txtname) == False:
with open (txtname,'w',encoding='utf-8') as file:
file.write(desc)
photos=comments.find_element_by_class_name('tm-m-photos')
photos=photos.find_element_by_class_name('tm-m-photos-thumb')
photos=photos.find_elements_by_tag_name('li')
for ph in photos:
phaddr=ph.get_attribute('data-src')
print(phaddr)
bigph=phaddr.split('_4')[0]
print(bigph)
imgname= os.path.join(dirname ,bigph.split('/')[-1])
if os.path.exists(imgname) :
continue
img=self.session_.get('http:'+bigph,headers=self.headers_,cookies=self.cookiejar_).content
print('正在爬取%s' %(bigph))
with open (imgname,'wb') as imgfile:
imgfile.write(img)
print('爬取成功%s' %(bigph))
time.sleep(2)
except NoSuchElementException:
print('No Element')
except TimeoutException :
print('TimeoutException')
except:
print('getPhoto exception')
pass
效果展示



源码下载地址
https://github.com/secondtonone1/python-
我的公众号
python(27) 抓取淘宝买家秀的更多相关文章
- 简单的抓取淘宝关键字信息、图片的Python爬虫|Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇)
Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇) 淘宝改字段,Bugfix,查看https://github.com/hunterhug/taobaoscrapy.git 由于Gith ...
- Python爬虫实战八之利用Selenium抓取淘宝匿名旺旺
更新 其实本文的初衷是为了获取淘宝的非匿名旺旺,在淘宝详情页的最下方有相关评论,含有非匿名旺旺号,快一年了淘宝都没有修复这个. 可就在今天,淘宝把所有的账号设置成了匿名显示,SO,获取非匿名旺旺号已经 ...
- Python爬虫实战四之抓取淘宝MM照片
原文:Python爬虫实战四之抓取淘宝MM照片其实还有好多,大家可以看 Python爬虫学习系列教程 福利啊福利,本次为大家带来的项目是抓取淘宝MM照片并保存起来,大家有没有很激动呢? 本篇目标 1. ...
- Python爬虫之一 PySpider 抓取淘宝MM的个人信息和图片
ySpider 是一个非常方便并且功能强大的爬虫框架,支持多线程爬取.JS动态解析,提供了可操作界面.出错重试.定时爬取等等的功能,使用非常人性化. 本篇通过做一个PySpider 项目,来理解 Py ...
- 一次Python爬虫的修改,抓取淘宝MM照片
这篇文章是2016-3-2写的,时隔一年了,淘宝的验证机制也有了改变.代码不一定有效,保留着作为一种代码学习. 崔大哥这有篇>>小白爬虫第一弹之抓取妹子图 不失为学python爬虫的绝佳教 ...
- Python爬虫学习==>第十二章:使用 Selenium 模拟浏览器抓取淘宝商品美食信息
学习目的: selenium目前版本已经到了3代目,你想加薪,就跟面试官扯这个,你赢了,工资就到位了,加上一个脚本的应用,结局你懂的 正式步骤 需求背景:抓取淘宝美食 Step1:流程分析 搜索关键字 ...
- 芝麻HTTP:Python爬虫实战之抓取淘宝MM照片
本篇目标 1.抓取淘宝MM的姓名,头像,年龄 2.抓取每一个MM的资料简介以及写真图片 3.把每一个MM的写真图片按照文件夹保存到本地 4.熟悉文件保存的过程 1.URL的格式 在这里我们用到的URL ...
- scrapy抓取淘宝女郎
scrapy抓取淘宝女郎 准备工作 首先在淘宝女郎的首页这里查看,当然想要爬取更多的话,当然这里要查看翻页的url,不过这操蛋的地方就是这里的翻页是使用javascript加载的,这个就有点尴尬了,找 ...
- 使用selenium模拟浏览器抓取淘宝信息
通过Selenium模拟浏览器抓取淘宝商品美食信息,并存储到MongoDB数据库中. from selenium import webdriver from selenium.common.excep ...
随机推荐
- Command and Query Responsibility分离模式
CQRS模式,就是命令和查询责任分离模式. CQRS模式通过使用不同的接口来分离读取数据和更新数据的操作.CQRS模式可以最大化性能,扩展性以及安全性,还会为系统的持续演化提供更多的弹性,防止Upda ...
- Hadoop日记Day5---HDFS介绍
一.HDFS介绍 1.1 背景 随着数据量越来越大,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式 ...
- [51Nod1238]最小公倍数之和 V3[杜教筛]
题意 给定 \(n\) ,求 \(\sum_{i=1}^n \sum_{j=1}^n lcm(i,j)\). \(n\leq 10^{10}\) 分析 推式子 \[\begin{aligned} an ...
- effective c++ 笔记 (1-3)
// // effective c++.cpp // 笔记 // // Created by fam on 15/3/23. // // //-------------------------- ...
- 一个Python开源项目-哈勃沙箱源码剖析(下)
前言 在上一篇中,我们讲解了哈勃沙箱的技术点,详细分析了静态检测和动态检测的流程.本篇接着对动态检测的关键技术点进行分析,包括strace,sysdig,volatility.volatility的介 ...
- 高精度加法--C++
高精度加法--C++ 仿照竖式加法,在第一步计算的时候将进位保留,第一步计算完再处理进位.(见代码注释) 和乘法是类似的. #include <iostream> #include < ...
- 记录:测试本机下使用 GPU 训练时不会导致内存溢出的最大参数数目
本机使用的 GPU 是 GeForce 840M,2G 显存,本机内存 8G. 试验时,使用 vgg 网络,调整 vgg 网络中的参数,使得使用对应的 batch_size 时不会提示内存溢出.使用的 ...
- 使用plumbing命令来深入理解git add和git commit的工作原理
前言: plumbing命令 和 porcelain命令 git中的命令分为plumbing命令和porcelain命令: porcelain命令就是我们常用的git add,git commit等命 ...
- 用 C 语言描述几种排序算法
排序算法是最基本且重要的一类算法,本文基于 VS2017,使用 C 语言来实现一些基本的排序算法. 一.选择排序 选择排序,先找到数组中最小的元素,然后将这个元素与数组的第一个元素位置互换(如果第一个 ...
- win10系统安装web3js的正确方法
在安装web3的时候 用npm install web3 –save-dev 在win10系统下会一直安装不成功.后来换用了 cnpm install web3 –save-dev 安装时候报出:C ...