Hadoop(二) HADOOP集群搭建
一、HADOOP集群搭建
1、集群简介
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起
HDFS集群:
负责海量数据的存储,集群中的角色主要有 NameNode / DataNode
YARN集群:
负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
(那mapreduce是什么呢?它其实是一个应用程序开发包)
本集群搭建案例,以5节点为例进行搭建,角色分配如下:
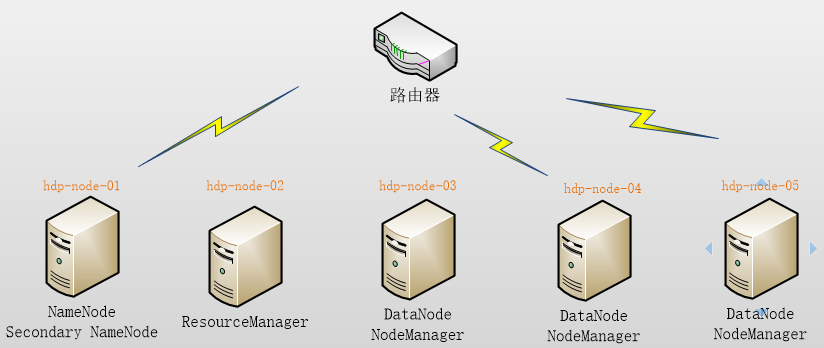
2、服务器准备
本案例使用虚拟机服务器来搭建HADOOP集群,所用软件及版本:
A.Vmware 11.0
B.Centos 6.5 64bit
3、网络环境准备
A 、采用NAT方式联网
B、网关地址:192.168.137.1
C、3个服务器节点IP地址:192.168.137.31、192.168.137.32、192.168.137.33
D 、子网掩码:255.255.255.0
4、服务器系统设置
A. 添加HADOOP用户
B. 为HADOOP用户分配sudoer权限
C. 同步时间
D. 设置主机名
hdp-node-01
hdp-node-02
hdp-node-03
E. 配置内网域名映射:
192.168.137.31 hdp-node-01
192.168.137.32 hdp-node-02
192.168.137.33 hdp-node-03
F. 配置ssh免密登陆
G. 配置防火墙
5、Jdk环境安装
上传jdk安装包
规划安装目录 /home/hadoop/apps/jdk_1.7.65
解压安装包
配置环境变量 /etc/profile
6、HADOOP安装部署
ü 上传HADOOP安装包
ü 规划安装目录 /home/hadoop/apps/hadoop-2.6.1
ü 解压安装包
ü 修改配置文件 $HADOOP_HOME/etc/hadoop/
最简化配置如下:(默认是后面有.template文件。)
vi hadoop-env.sh
|
# The java implementation to use. export JAVA_HOME=/home/hadoop/apps/jdk1.7.0_51 |
vi core-site.xml
|
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hdp-node-01:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/HADOOP/apps/hadoop-2.6.1/tmp</value> </property> </configuration> |
vi hdfs-site.xml
|
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>/home/hadoop/data/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hadoop/data/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.secondary.http.address</name> <value>hdp-node-01:50090</value> </property> </configuration> |
vi mapred-site.xml
|
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> |
vi yarn-site.xml
|
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop01</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration> |
vi salves
|
hdp-node-01 hdp-node-02 hdp-node-03 |
7、启动集群
初始化HDFS
bin/hadoop namenode -format
启动HDFS
sbin/start-dfs.sh
启动YARN
sbin/start-yarn.sh
单个启动
hadoop-de
8、测试
A、上传文件到HDFS
从本地上传一个文本文件到hdfs的/wordcount/input目录下
[HADOOP@hdp-node-01 ~]$ HADOOP fs -mkdir -p /wordcount/input
[HADOOP@hdp-node-01 ~]$ HADOOP fs -put /home/HADOOP/somewords.txt /wordcount/input
B、运行一个mapreduce程序
在HADOOP安装目录下,运行一个示例mr程序
cd $HADOOP_HOME/share/hadoop/mapreduce/
hadoop jar mapredcue-example-2.6.1.jar wordcount /wordcount/input /wordcount/output
Hadoop(二) HADOOP集群搭建的更多相关文章
- hadoop高可用集群搭建小结
hadoop高可用集群搭建小结1.Zookeeper集群搭建2.格式化Zookeeper集群 (注:在Zookeeper集群建立hadoop-ha,amenode的元数据)3.开启Journalmno ...
- 从零自学Hadoop(06):集群搭建
阅读目录 序 集群搭建 监控 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 序 上一 ...
- 基于Hadoop伪分布式集群搭建Spark
一.前置安装 1)JDK 2)Hadoop伪分布式集群 二.Scala安装 1)解压Scala安装包 2)环境变量 SCALA_HOME = C:\ProgramData\scala-2.10.6 P ...
- hadoop伪分布式集群搭建与安装(ubuntu系统)
1:Vmware虚拟软件里面安装好Ubuntu操作系统之后使用ifconfig命令查看一下ip; 2:使用Xsheel软件远程链接自己的虚拟机,方便操作.输入自己ubuntu操作系统的账号密码之后就链 ...
- hadoop namenode HA集群搭建
hadoop集群搭建(namenode是单点的) http://www.cnblogs.com/kisf/p/7456290.html HA集群需要zk, zk搭建:http://www.cnblo ...
- Hadoop介绍及集群搭建
简介 Hadoop 是 Apache 旗下的一个用 java 语言实现开源软件框架,是一个开发和运行处理大规模数据的软件平台.允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理.它的核 ...
- Hadoop完全分布式集群搭建
Hadoop的运行模式 Hadoop一般有三种运行模式,分别是: 单机模式(Standalone Mode),默认情况下,Hadoop即处于该模式,使用本地文件系统,而不是分布式文件系统.,用于开发和 ...
- 大数据之Hadoop完全分布式集群搭建
1.准备阶段 1.1.新建三台虚拟机 Hadoop完全分市式集群是典型的主从架构(master-slave),一般需要使用多台服务器来组建.我们准备3台服务器(关闭防火墙.静态IP.主机名称).如果没 ...
- Zookeeper(二) zookeeper集群搭建 与使用
一.zookeeper集群搭建 鉴于 zookeeper 本身的特点,服务器集群的节点数推荐设置为奇数台.我这里我规划为三台, 为别为 hadoop01,hadoop02,hadoop03 1. ...
- kafka学习(二)-zookeeper集群搭建
zookeeper概念 ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名 服务等.Zookeeper是h ...
随机推荐
- spring中的IOC/DI的知识点
IOC(Inverse of control):控制反转;其实就是一个装对象的容器,以前我们在controller中调用service中的方法,都要先new 一个service对象,这样不符合模式设计 ...
- Cascade Classifier Training 没有基础也会目标检测啦
Cascade Classifier Training 具体自己看: http://docs.opencv.org/2.4.13.2/doc/user_guide/ug_traincascade.ht ...
- mysql查找某连续字段中断的编号
查询dj_pxlb表中zwh 空缺的值 select model2.zwh-1 as kqzwh from (select model1.zwh from dj_pxlb as model1 wher ...
- Makefile编写参考
http://www.ruanyifeng.com/blog/2015/02/make.html
- html----h1-6标签
Html的标题标签h1-h6种选择,从大到小:默认上下margin一样,靠左,不好改变:能用定位改变. 1.<h1></h1> display:block; font-size ...
- redis编译安装
centos7 redis-4.0.6 make 报错 jemalloc.h: No such file or directory make MALLOC=libc MALLOC默认值是jemallo ...
- C++ STL--queue 的使用方法
2.queuequeue 模板类的定义在<queue>头文件中.与stack 模板类很相似,queue 模板类也需要两个模板参数,一个是元素类型,一个容器类型,元素类型是必要的,容器类型是 ...
- 论Ubuntu下的docker多难搭建
慷慨一下: 上周四开始打算在Ubuntu系统下面熟悉操作一下docker,所以深知在本地的虚拟机上搭建一个docker非常的easy. 但是,要下载一个镜像,真是太难了.基本可以说是下载不了的.于是乎 ...
- StringBuild类
每次拼接都会产生新的字符串对象,从而产生很多废弃的垃圾,拼的越多,垃圾越多,而利用StringBuilder来拼接字符串自始至终用的都是同一个StringBuilder容器 StringBuilder ...
- SSM的例子-参考
ssm的例子:http://blog.csdn.net/double030/article/details/63683613