大数据之Hadoop完全分布式集群搭建
1.准备阶段
1.1.新建三台虚拟机
Hadoop完全分市式集群是典型的主从架构(master-slave),一般需要使用多台服务器来组建。我们准备3台服务器(关闭防火墙、静态IP、主机名称)。如果没有这样的环境,可以在一台电脑上安装VMWare Workstation。在VM上安装三台Linux,分别是1个主节点,2个从节点,如下图所示。
|
节点类型 |
IP地址 |
主机名 |
|
NameNode |
192.168.86.150 |
master |
|
DataNode |
192.168.86.160 |
slave1 |
|
DataNode |
192.168.86.170 |
slave2 |
注意:这3个节点的IP地址在实际搭建时会有所不同。
1.2.配置静态IP
在Linx系统命令终端,执行命令 vim ifcfg-eth0,并修改文件的内容,按“键入编辑内容编译完成后按Esc键退出编译状态,之后执行命令wq,保存并退出。IPADDR、 NETMASK、 GATEWAY、DNS1的值可以根据自己的本机进行修改,如下所示。
DEVICE="eth0" #设备名字
BOOTPROTO="static" #静态ip
HWADDR="00:0C:29:ED:83:F7" #mac地址
IPV6INIT="yes"
NM_CONTROLLED="yes"
ONBOOT="yes" #开启自启动
TYPE="Ethernet" #网络类型
UUID="28354862-67a7-4a5b-9f9a-54561401f614"
IPADDR=192.168.11.10 #IP地址
NETMASK=255.255.255.0 #子网掩码
GATEWAY=192.168.11.2 #网关
DNS1=192.168.11.2 # dns
1.3.修改主机名和域名映射
(1)启动命令终端,在任何目录下执行命令cd/ etc/sysconfig,切换到该目录并查看目录下的文件,可以发现存在文件 network,如图所示。
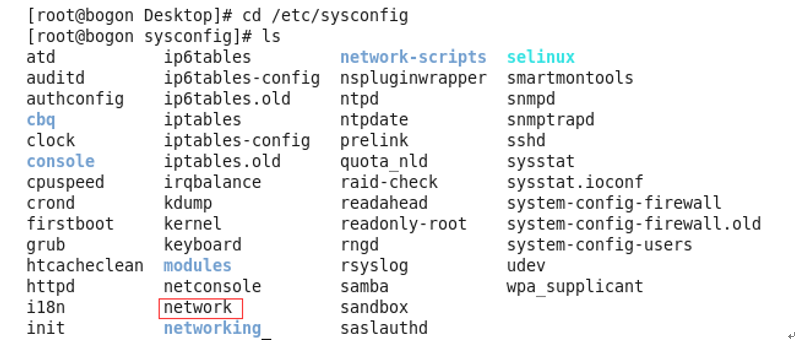
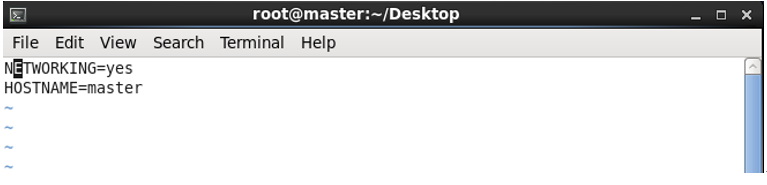
(2)在/etc/sysconfig目录下找到文件 network,然后执行命令 vim network,按“i”进入编辑内容,编译完成后按Esc退出编译状态,之后执行命令wq保存并退出,后面两台也都这样,如下图所示。
(3)修改主机名和iP地址具有映射关系,执行命令vim/ etc/hosts,按“i”进入编辑内容,编译完成后按Esc退出编译状态,之后执行命令wq保存并退出,把三台的ip和主机名都编辑,如图所示。

(4)scp命令传送文件
scp /etc/hosts root@slave1:/etc/hosts
scp /etc/hosts root@slave2:/etc/hosts
把修改好的发送给slave1,再用相同的方法,发送给slave2。
下面我们详细介绍一下scp命令,scp是secure copy的缩写,是用于Linux之间复制文件和目录的。scp是Linux系统下基于ssh登陆进行安全的远程文件拷贝命令。
scp数据传输可以使用ssh1或ssh2。scp命令可以使用IPv4寻址或IPv6寻址。
l 复制文件语法:
scp /源文件完整路径 远程用户名@IP地址: /目标文件完整路径
或者
scp /源文件完整路径 远程用户名@机器名: /目标文件完整路径
scp /home/space/music/1.mp3 root@slave1:/home/root/others/music
scp /home/space/music/1.mp3 root@192.168.86.153:/home/root/others/music/001.mp3
l 复制目录语法:
scp -r /源目录完整路径 远程用户名@IP地址: /目标目录所在路径
或者
scp -r /源目录完整路径 远程用户名@机器名: /目标目录所在路径
scp -r /home/space/music/ root@slave3:/home/root/others/
scp -r /home/space/music/ root@192.168.86.153:/home/root/others/
l 从远程复制到本地
从远程复制到本地,只要将从本地复制到远程的命令的后2个参数调换顺序即可。
scp root@slave3:/home/root/others/music/1.mp3 /home/space/music
参数:
|
-r |
递归复制整个目录。 |
|
-v |
和大多数linux命令中的-v意思一样,用来显示进度。可以用来查看连接、认证、或是配置错误。 |
|
-C |
允许压缩。(将-C标志传递给ssh,从而打开压缩功能)。 |
|
-1 |
强制scp命令使用协议ssh1。 |
|
-2 |
强制scp命令使用协议ssh2。 |
|
-4 |
强行使用IPV4地址。 |
|
-6 |
强行使用IPV6地址。 |
|
-q |
不显示传输进度条。 |
1.4.安装Java
(1)启动 Linux命令终端,分别在三台虚拟机上创建目录,执行命令mkdir /usr/java,切换到该目录下执行命令cd/usr/java,
[root@hadoop ~] mkdir/usr/java
[root@hadoop ~]cd /usr/java
(2)把JDK文件jdk-8u181-linux-x64.tar.gz上传到该目录下
(3)然后对/usr/java目录下的JDK压缩文件jdk-8u181-linux-x64.tar.gz,执行命令
对jdk-8u181-linux-x64.tar.gz进行解压
[root@hadoop java]#tar -xzvf jdk-8u181-linux-x64.tar.gz
(4)解压之后,执行命令 Il,可以看到该目录下多了一个解压后的Jdk文件,如图2-43所示。
(5)把jdk文件上传到其他两台,通过命令上传到其他两台虚拟机上,指定命令
scp –r /usr/java root@主机名:/usr
[root@master ~]scp –r /usr/java root@slave1:/usr
[root@master ~] scp –r /usr/java root@slave2:/usr
(6)然后到slave1和slave2的/usr目录下看,是否有java这个目录
(7)完成上一步之后,可以执行cd jdk.1.7.0_80,进入JDK安装目录
(8)确定解压无误之后,此时需要配置JDK环境变量,执行命令 vim /etc/profile单击”i“进入编辑内容,编译完成后按Esc退出编译状态,之后执行命令wq保存并退出。如图
(9)编辑完后进行配置文件刷新,执行命令 source /etc/profile,刷新配置,配置的信息才会生效.
[root@hadoop jdk1.7.0_80]# source /etc/profile
(10)完成以上步骤之后,需要测试环境变量是否配置成功,只需要在任何目录下执行Java –version ,如图,出现下图情况就是配置成功。

1.5.关闭防火墙
关闭Linux防火墙有以下3个步骤:
1.查看防火墙状态
service iptables status
2. 关闭防火墙
service iptables stop
3. 永久性关闭防火墙
chkconfig iptables off
1.6.SSH免密登陆
(1)在Linux系统的终端的任何目录下通过切换cd ~/.ssh,进入到.ssh目录下。
~表示当前用户的home目录,通过cd ~可以进入到你的home目录。.开头的文件表示隐藏文件,这里.ssh就是隐藏目录文件。
(2)在Linux系统命令框的.ssh目录下
[root@root .ssh]# ssh-keygen -t rsa
(连续按四次回车)执行完上面命令后,会生成两个id_rsa(私钥)、id_rsa.pub(公钥)两个文件,如图所示

(3)授权SSH免密码
[root@master .ssh]# ssh-copy-id master
[root@master .ssh]# ssh-copy-id slave1
[root@master .ssh]# ssh-copy-id slave2
给当前主机和其他两台都设置免密码登录,这样三台可以互通。(根据提示输入yes并输入访问主机所需要的密码。)
(4)在master主机上执行下面的3条命令。
[root@master .ssh]# ssh master
[root@master .ssh]# ssh slave1
[root@slave1 ~]# exit
[root@master .ssh]# ssh slave2
发现不需要密码就能连接任意一台虚拟机。
注意:当执行ssh slave1命令后,就以SSH免密方式登录到slave1。必须使用exit命令退出登录slave1,再尝试执行ssh slave2。
1.7.配置时间同步服务
(1)安装NTP服务。
在各节点执行命令 yum install -y ntp即可。若是最终出现了“Complete”信息,就说明安装NTP服务成功。
(2)设置 master节点为NTP服务主节点,那么其配置如下。
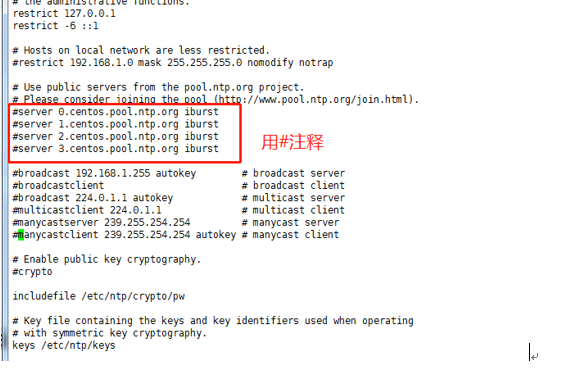
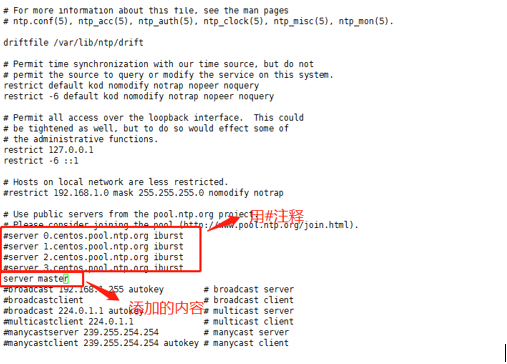
使用命令“ vim /etc/ntp.conf”来打开/etc/ntp.conf文件,注释掉以 server开头的行,并添加代码所示的内容。
restrict 192.168.0.0 mask 255.255.255.0 nomodify notrap
server 127.127.1.0
fudge 127.127.1.0 stratum 10
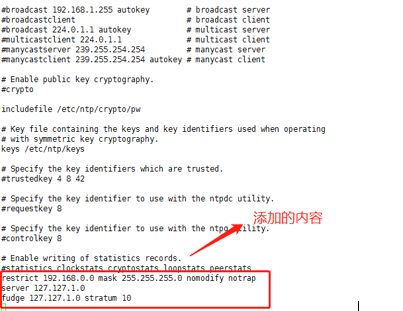
(3)分别在slave1,slave2中配置NTP,同样修改/etc/ntp.conf文件,注释掉server开头的行,并添加下面代码所示的内容。
server master
(4)永久性关闭防火墙,主节点和从节点都要关闭。执行命令
service iptables stop
chkconfig iptables off
(5)启动NTP服务
①在 master节点执行命令“ service ntpd start& chkconfig ntpd on”,如下图所示,说明NTP服务启动成功。

②在slave1、slave2上同步时间。执行命令
ntpdate master
③在 slave1、slave2上分别执行“ service ntpd start& chkconfig ntpd on”,即永久启动NTP服务。
④分别在master、slave1、slave2上分别输入date,看时间是否一致。
2.配置阶段
2.1.文件的配置
master主机上
(1)创建目录mkdir /usr/hadoop,执行命令cd/usr/hadoop,切换到该目录下,把Hadoop文件上传到该目录下
(2)然后对/usr/hadoop目录下的Hadoop压缩文件hadoop-2.6.5.tar.gz,执行命令
tar -zxvf hadoop-2.6.5.tar.gz -C /usr/hadoop
-C是指解压压缩包到指定位置
(3)修改配置文件
切换到$HADOOP_NAME/etc/hadoop 目录下并查看该目录下的包,如图
下面我们需要修改以下的7个文件。
|
文件名 |
文件路径 |
|
hadoop-env.sh |
$HADOOP_NAME/etc/hadoop |
|
core-site.xml |
$HADOOP_NAME/etc/hadoop |
|
hdfs-site.xml |
$HADOOP_NAME/etc/hadoop |
|
mapred-site.xml |
$HADOOP_NAME/etc/hadoop |
|
yarn-site.xml |
$HADOOP_NAME/etc/hadoop |
|
yarn-env.sh |
$HADOOP_NAME/etc/hadoop |
|
profile |
/etc/ profile |
|
slaves |
$HADOOP_NAME/etc/hadoop |
(4)在$HADOOP_NAME/etc/hadoop目录下执行命令
vim hadoop-env.sh
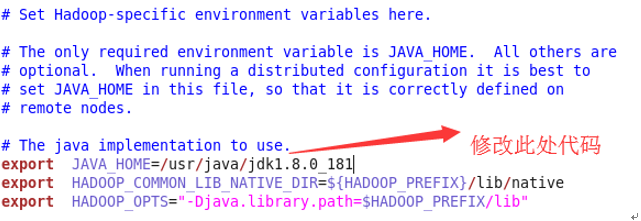
按“i”键进入编辑内容,在文件中添加如下内容:
export JAVA_HOME=/usr/java/ jdk1.8.0_181
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_PREFIX}/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_PREFIX/lib"
编译完成后,按ESC退出编辑状态,之后执行命令wq保存并退出
(5)在$HADOOP_NAME/etc/hadoop目录下执行命令
vim core-site.xml
并修改配置文件core-site.xml ,内容如下:
<configuration>
<!—指定HDFS的(Namenode)的缺省路径地址:master是计算机名,也可以是ip地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!—指定Hadoop运行时产生文件的存储目录,需要创建/usr/hadoop/tmp目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
</property>
</configuration>
(6)$HADOOP_NAME/etc/hadoop目录下执行命令vim hdfs-site.xml,并修改配置文件hdfs-site.xml ,内容如下
<configuration>
<!--指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--namenode上存储hdfs名字空间元数据,/home/hadoop/dfs/name需要自建 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/dfs/name</value>
</property>
<!--datanode上数据块的物理存储位置,/home/hadoop/dfs/data需要自建 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
</configuration>
(7)在$HADOOP_NAME/etc/hadoop目录下查看是否有配置文件mapred-site.xml。目录下默认情况下没有该文件,可通过执行命令
mv mapred-site.xml.template mapred-site.xml,修改一个文件的命名。
然后执行命令
vim mapred-site.xml
并修改配置文件mapred-site.xml,内容如下:
<configuration>
<!—指定mr运行在yarn上->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!—查看历史日志-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
(8)在$HADOOP_NAME/etc/hadoop目录下执行命令vim yarn-site.xml,并修改配置文件yarn-site.xml ,内容如下
<configuration>
<!—指定resourcemanager的地址,主机是master-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!—获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
(9)在$HADOOP_NAME/etc/hadoop目录下执行命令
vim yarn-env.sh
修改配置文件yarn-env.sh ,增加如下内容
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_PREFIX}/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_PREFIX/lib"
(10)执行命令vim /etc/profile,把Hadoop的安装目录配置到环境变量中
#hadoop
HADOOP_HOME=/usr/hadoop/hadoop-2.6.5
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
(11)然后让配置文件生效,执行命令
source /etc/profile
(12)在$HADOOP_NAME/etc/hadoop目录下执行命令vim slaves,并修改配置文件slaves,内容如下。
slave1 slave2s
注意:删除localhost
2.2.分发Hadoop
在master上执行命令,将配置好的hadoop分发到两个从节点slave1,slave2上。
scp -r /usr/hadoop/hadoop-2.6.5 root@slave1:/usr/hadoop/
scp -r /usr/hadoop/hadoop-2.6.5 root@slave2:/usr/hadoop/
注:在slave1和slave2上提前先创建好/usr/hadoop目录
在从节点slave1,slave2上修改/etc/profile
2.3.格式化NameNode
master主机是NameNode,必须格式化之后才能使用,格式化命令只需要执行一次。在任意目录下,执行命令
hdfs namenode -format
或者
hadoop namenode -format
注意:以上命令必须在配置Hadoop环境变量的情况下才能执行。所以必须修改/etc/profile文件并且执行下面的命令启动修改。
source /etc/profile
2.4.启动集群
(1)首先启动HDFS系统,master上$HADOOP_HOME/sbin目录下执行命令start-dfs.sh(注意slave1和slave2不需要执行命令),然后在master、slave1、slave2主机上用jps查看进程,如图所示。
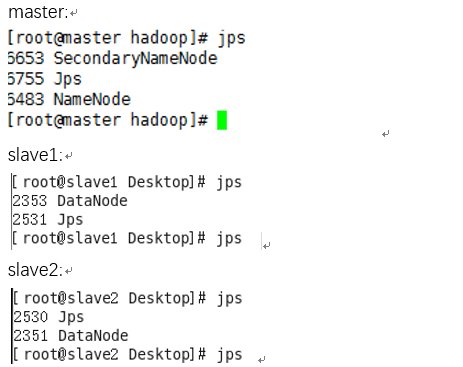
如上图可以看出master主机是NameNode同时还是SecondNameNode。slave1和slave2主机是DataNode。
注意:在slave1和slave2上修改/etc/profile,执行12.2.11中的步骤10和步骤11。
(2)首先启动yarn系统,master上执行命令start-yarn.sh(注意slave1和slave2不需要执行命令),然后在master、slave1、slave2主机上用jps查看进程,如图所示。
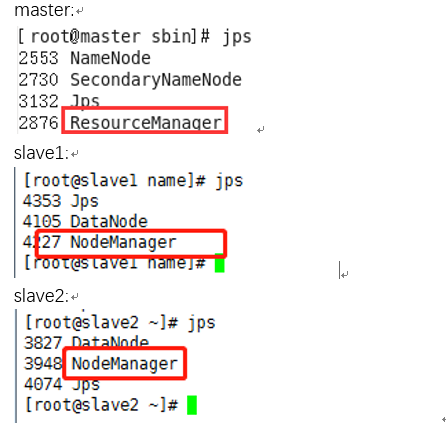
如上图可以看出master主机上有ResourceManager。slave1和slave2主机上有NodeManager。
至此,我们的Hadoop的完全分布式集群搭建已经大功告成了。
大数据之Hadoop完全分布式集群搭建的更多相关文章
- hadoop伪分布式集群搭建与安装(ubuntu系统)
1:Vmware虚拟软件里面安装好Ubuntu操作系统之后使用ifconfig命令查看一下ip; 2:使用Xsheel软件远程链接自己的虚拟机,方便操作.输入自己ubuntu操作系统的账号密码之后就链 ...
- Hadoop完全分布式集群搭建
Hadoop的运行模式 Hadoop一般有三种运行模式,分别是: 单机模式(Standalone Mode),默认情况下,Hadoop即处于该模式,使用本地文件系统,而不是分布式文件系统.,用于开发和 ...
- 基于Hadoop伪分布式集群搭建Spark
一.前置安装 1)JDK 2)Hadoop伪分布式集群 二.Scala安装 1)解压Scala安装包 2)环境变量 SCALA_HOME = C:\ProgramData\scala-2.10.6 P ...
- Hadoop学习笔记(一):ubuntu虚拟机下的hadoop伪分布式集群搭建
hadoop百度百科:https://baike.baidu.com/item/Hadoop/3526507?fr=aladdin hadoop官网:http://hadoop.apache.org/ ...
- Hadoop伪分布式集群搭建
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 1.下载Hadoop压缩包 wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop- ...
- hadoop 完全分布式集群搭建
1.在伪分布式基础上搭建,伪分布式搭建参见VM上Hadoop3.1伪分布式模式搭建 2.虚拟机准备,本次集群采用2.8.3版本与3.X版本差别不大,端口号所有差别 192.168.44.10 vmho ...
- linux运维、架构之路-Hadoop完全分布式集群搭建
一.介绍 Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS.HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件 ...
- hadoop HA分布式集群搭建
概述 hadoop2中NameNode可以有多个(目前只支持2个).每一个都有相同的职能.一个是active状态的,一个是standby状态的.当集群运行时,只有active状态的NameNode是正 ...
- centos7+hadoop完全分布式集群搭建
Hadoop集群部署,就是以Cluster mode方式进行部署.本文是基于JDK1.7.0_79,hadoop2.7.5. 1.Hadoop的节点构成如下: HDFS daemon: NameN ...
随机推荐
- hihocoder 1251 Today is a rainy day ( 15年北京 C、暴力 )
题目链接 题意 : 一串数字变成另一串数字,可以单个数字转变,或者一类数字转变,问最少操作次数 分析 : 15年北京赛区的银牌题 首先有一个点需要想明白.或者猜得到 即最优的做法肯定是先做完 2 操作 ...
- flask框架(十一): 蓝图
蓝图用于为应用提供目录划分: 一:上目录结构 二:上代码 <!DOCTYPE html> <html lang="en"> <head> < ...
- C#获取实体类属性名和值
遍历获得一个实体类的所有属性名,以及该类的所有属性的值 //先定义一个类: public class User { public string name { get; set; } public st ...
- OpenCV学习笔记(13)——轮廓特征
查找轮廓的不同特征,例如面积,周长,重心,边界等 1.矩 图像的矩可以帮助我们计算图像的质心,面积等. 函数cv2.momen()会将计算得到的矩以一个字典的形式返回, 我们的测试图像如下: 例程如下 ...
- Json文件删除元素
方法1:delete 注意,该方法删除之后的元素会变为null,并非真正的删除!!! 举例: 原json: { "front" : { "image" : [ ...
- Java快排
package quickSort; /** * 快速排序 * @author root * */ public class QuickSort { static int[] data = {0,2, ...
- np.repeat()
np.repeat()用于将numpy数组重复. numpy.repeat(a, repeats, axis=None); 参数: axis=0,沿着y轴复制,实际上增加了行数axis=1,沿着x轴复 ...
- sql中对查询出的某个字段转换查询
<select id="queryCmonByLanId" parameterType="java.util.Map" resultType=" ...
- stringstream 类型转换
stringstream可以吞下不同的类型,然后吐出不同的类型. 这样可以实现int,string,double等类型的转换 #include<sstream> using namespa ...
- padding的计算方法
转自https://blog.csdn.net/qq_34599526/article/details/83755275 VALID:如果卷积核超出特征层,就不再就计算,即卷积核右边界不超出Featu ...