mongo的聚合操作

对图7-1所示的数据集exampledata1,使用聚合操作实现以下功能:
(1)不返回_id字段,只返回age和sex字段。
(2)所有age大于28的记录,只返回age和sex。
(3)在$match返回的字段中,添加一个新的字段“hello”,值为“world”。
(4)在$match返回的字段中,添加一个新的字段“hello”,值复制age的值。
(5)在$match返回的字段中,把age的值修改为一个固定字符串。
(6)把user.name和user.user_id变成普通的字段并返回。
(7)在返回的数据中,添加一个字段“hello”,值为“$normalstring”,再添加一个字段“abcd”,值为1。
“$match”可以筛选出需要的记录,那么如果想只返回部分字段,又应该怎么做呢?这时就需要使用关键字“$project”。
返回部分字段
首先用“$project”来实现一个已经有的功能——只返回部分字段。格式如下:
collection.aggregate([{'$project': {字段过滤语句}}])
这里的字段过滤语句与“find()”第2个参数完全相同,也是一个字典。字段名为Key,Value为1或者0(需要的字段Value为1,不需要的字段Value为0)。
例如,对于图7-1所示的数据集,不返回“_id”字段,只返回age和sex字段,则聚合语句如下:
db.getCollection('example_data_1').aggregate([{'$project': {'_id': 0, 'sex': 1, 'age': 1}}])
查询结果如图7-22所示。
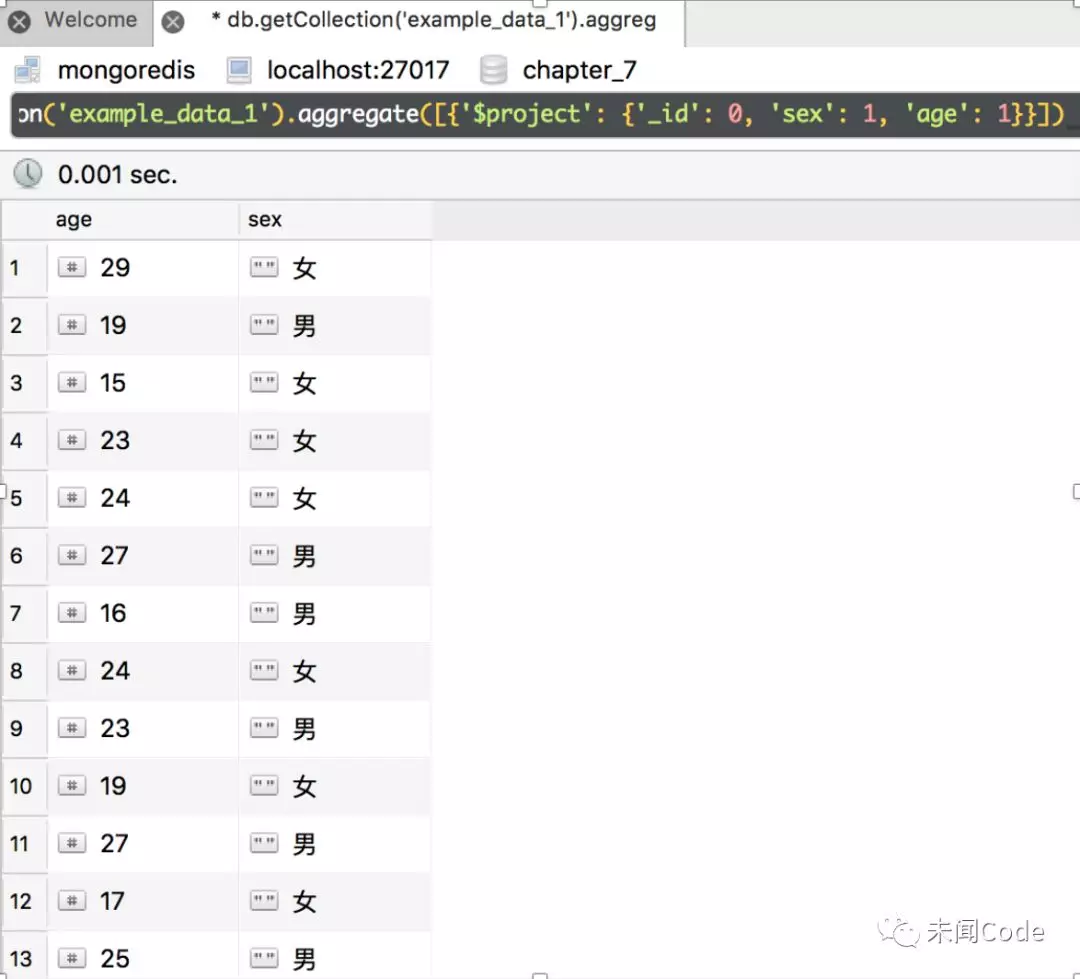
结合“$match”实现“先筛选记录,再过滤字段”。例如,选择所有age大于28的记录,只返回age和sex,则聚合语句写为:
db.getCollection('example_data_1').aggregate([{'$match': {'age': {'$gt': 28}}},{'$project': {'_id': 0, 'sex': 1, 'age': 1}}])
查询结果如图7-23所示。

到目前为止,使用“$match”加上“$project”,多敲了几十次键盘,终于实现了“find()”的功能。使用聚合操作复杂又繁琐,好处究竟是什么?
添加新字段
添加固定文本
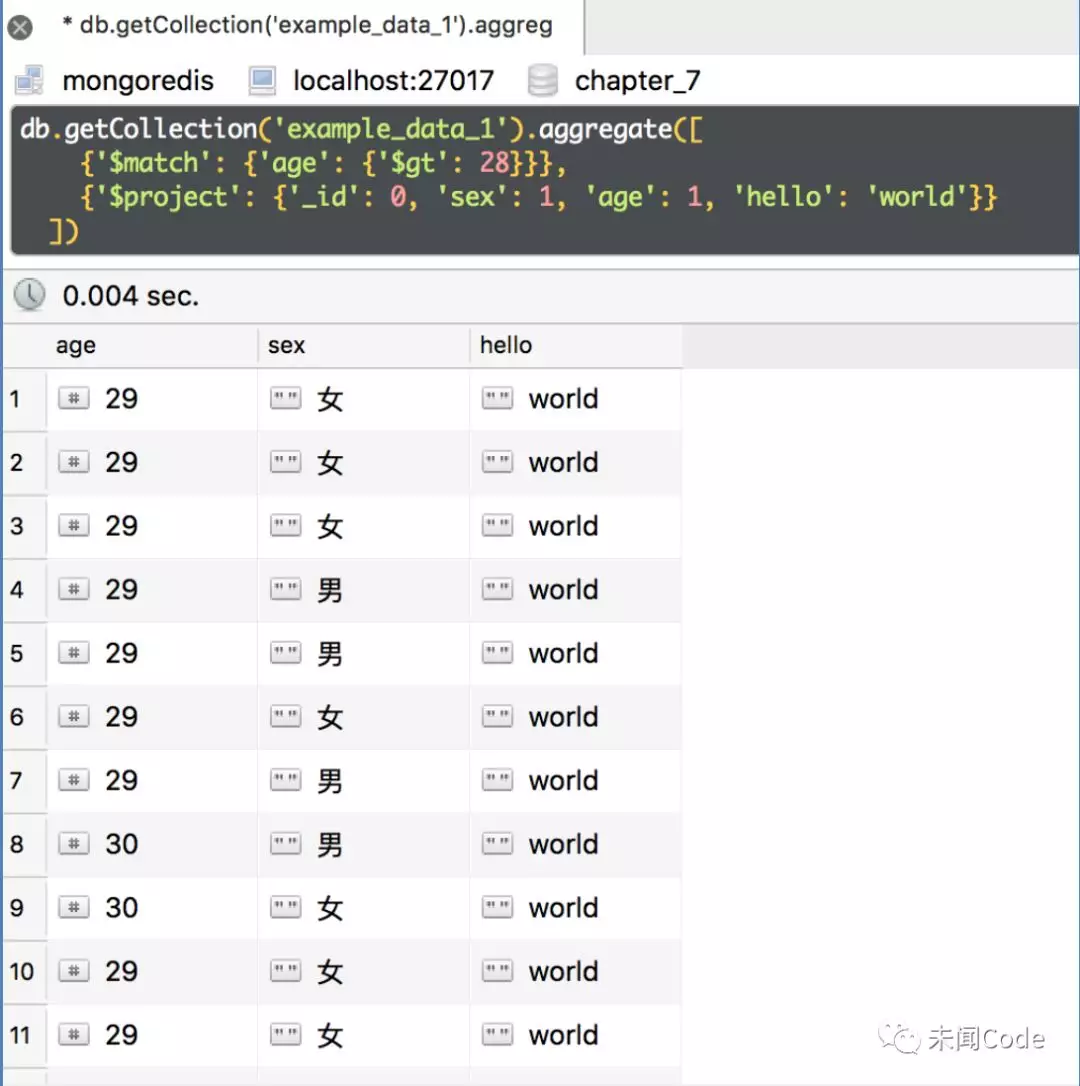
在“$project”的Value字典中添加一个不存在的字段,看看效果会怎么样。例如:
db.getCollection('example_data_1').aggregate([{'$match': {'age': {'$gt': 28}}},{'$project': {'_id': 0, 'sex': 1, 'age': 1, 'hello': 'world'}}])
注意这里的字段名“hello”,exampledata1数据集是没有这个字段的,而且它的值也不是“0”或者“1”,而是一个字符串。
查询结果如图7-24所示。在查询的结果中直接增加了一个新的字段。
复制现有字段。
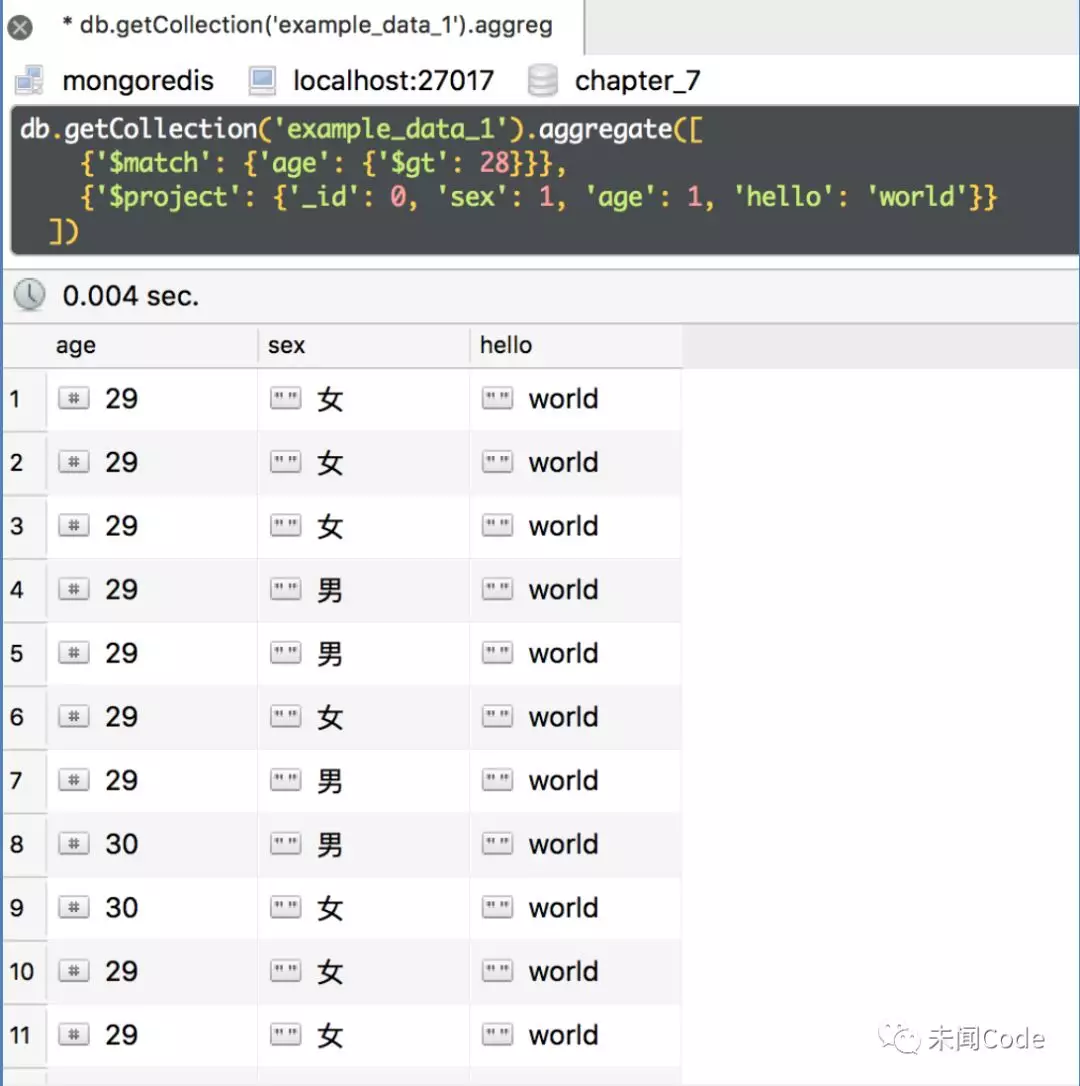
现在把上面代码中的“world”修改为“$age”,变为:
db.getCollection('example_data_1').aggregate([{'$match': {'age': {'$gt': 28}}},{'$project': {'_id': 0, 'sex': 1, 'age': 1, 'hello': '$age'}}])
查询结果如图7-25所示。
修改现有字段的数据
接下来,把原有的age的值“1”改为其他数据,代码变为:
db.getCollection('example_data_1').aggregate([{'$match': {'age': {'$gt': 28}}},{'$project': {'_id': 0, 'sex': 1, 'age': "this is age"}}])
查询结果如图7-26所示。
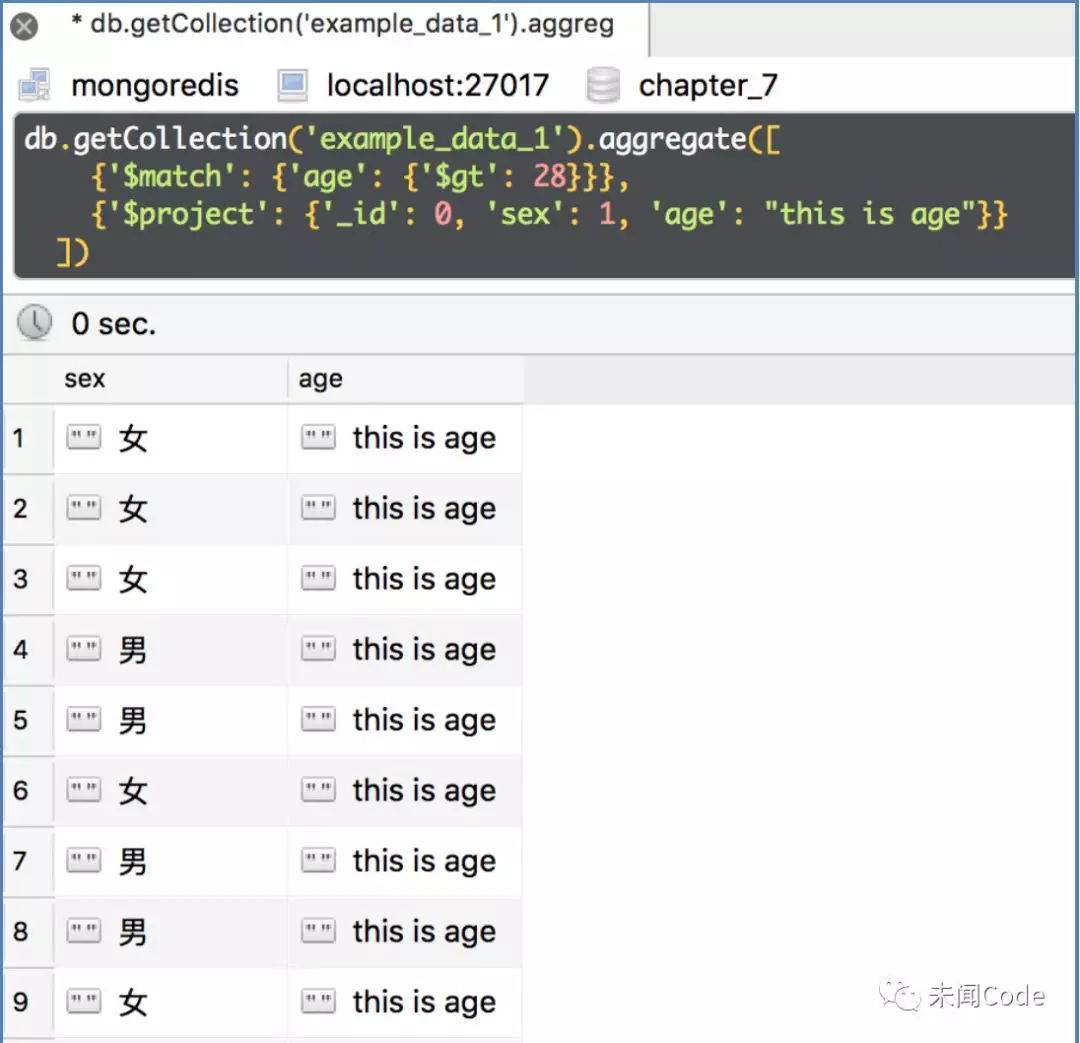
从图7-25和图7-26可以看出,在“$project”中,如果一个字段的值不是“0”或“1”,而是一个普通的字符串,那么最后的结果就是直接输出这个普通字符串,无论数据集中原本是否有这个字段。
从图7-26可以看出,如果一个字段后面的值是“$+一个已有字段的名字”(例如“$age”),那么这个字段就会把“$”标记的字段的内容逐行复制过来。这个复制功能初看起来似乎没有什么用,原样复制能干什么?那么现在来看看exampledata2的嵌套字段。
抽取嵌套字段
对于如下图所示的数据集 example_data_2:
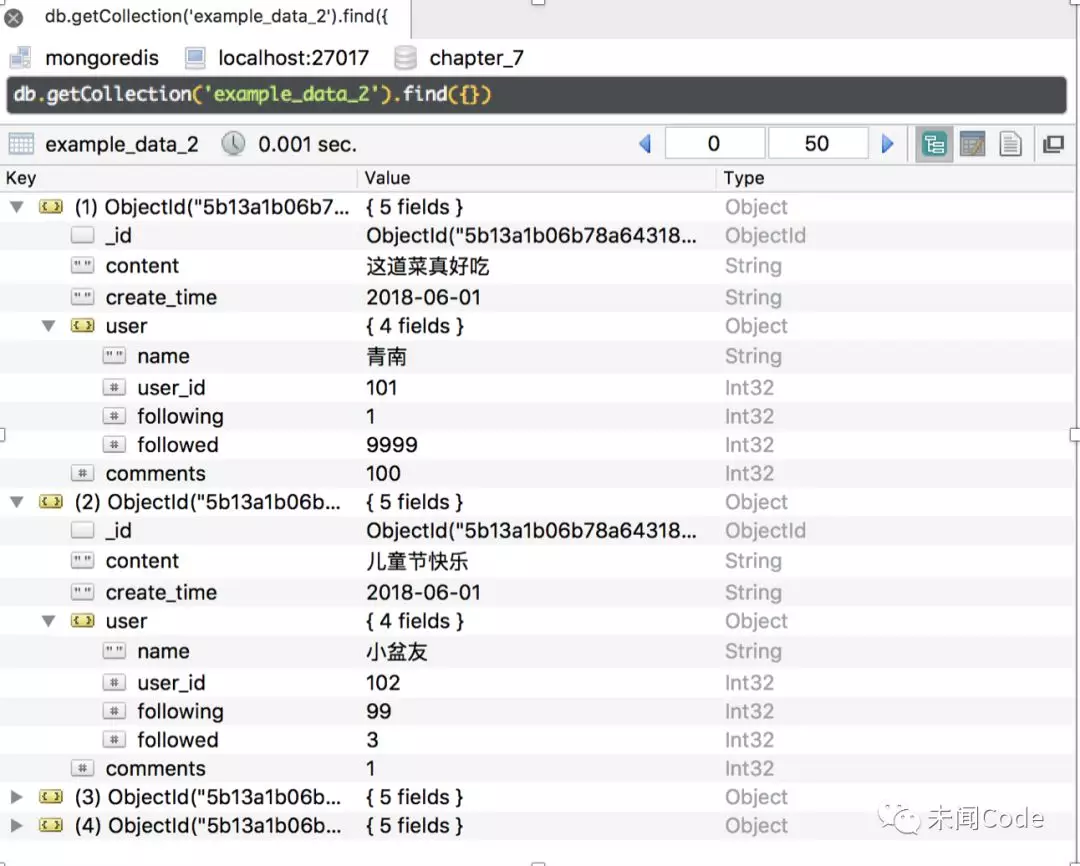
如果直接使用find(),想返回“user_id”和“name”,则查询语句为:
db.getCollection('example_data_2').find({}, {'user.name': 1, 'user.user_id': 1})
查询结果如图7-27所示。
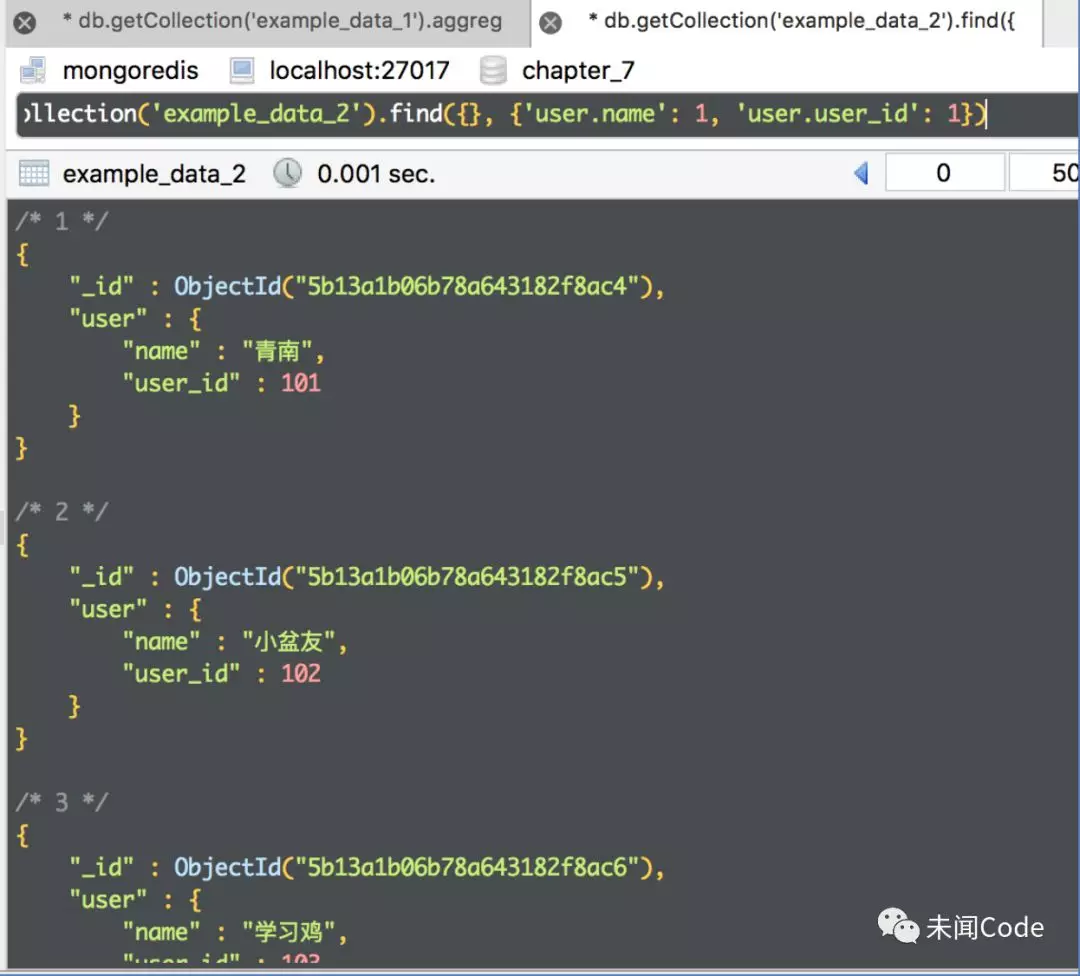
返回的结果仍然是嵌套字段,这样处理起来非常不方便。而如果使用“$project”,则可以把嵌套字段中的内容“抽取”出来,变成普通字段,具体代码如下:
db.getCollection('example_data_2').aggregate([{'$project': {'name': '$user.name', 'user_id': '$user.user_id'}}])
查询结果如图7-28所示。
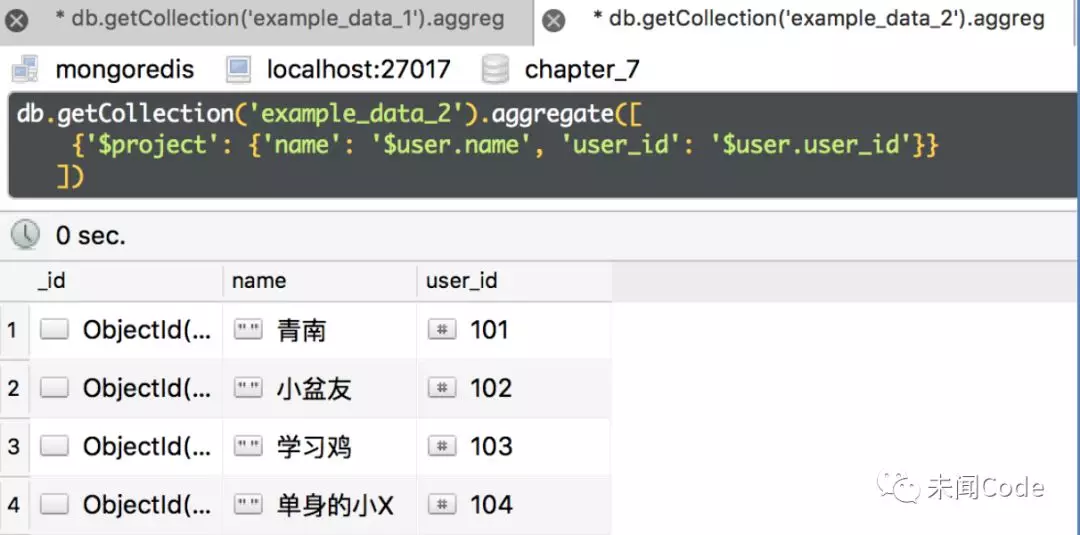
普通字段处理起来显然是要比嵌套字段方便不少,这就是“复制字段”的妙用。
处理字段特殊值
看到这里,可能有读者要问:
如果想添加一个字段,但是这个字段的值就是数字“1”会怎么样?
如果添加一个字段,这个字段的值就是一个普通的字符串,但不巧正好以“$”开头,又会怎么样呢?
下面这段代码是图7-1所示的数据集的查询结果。
db.getCollection('example_data_1').aggregate([{'$match': {'age': {'$gt': 28}}},{'$project': {'_id': 0, 'id': 1, 'hello': '$normalstring', 'abcd': 1}}])
查询结果如图7-29所示。
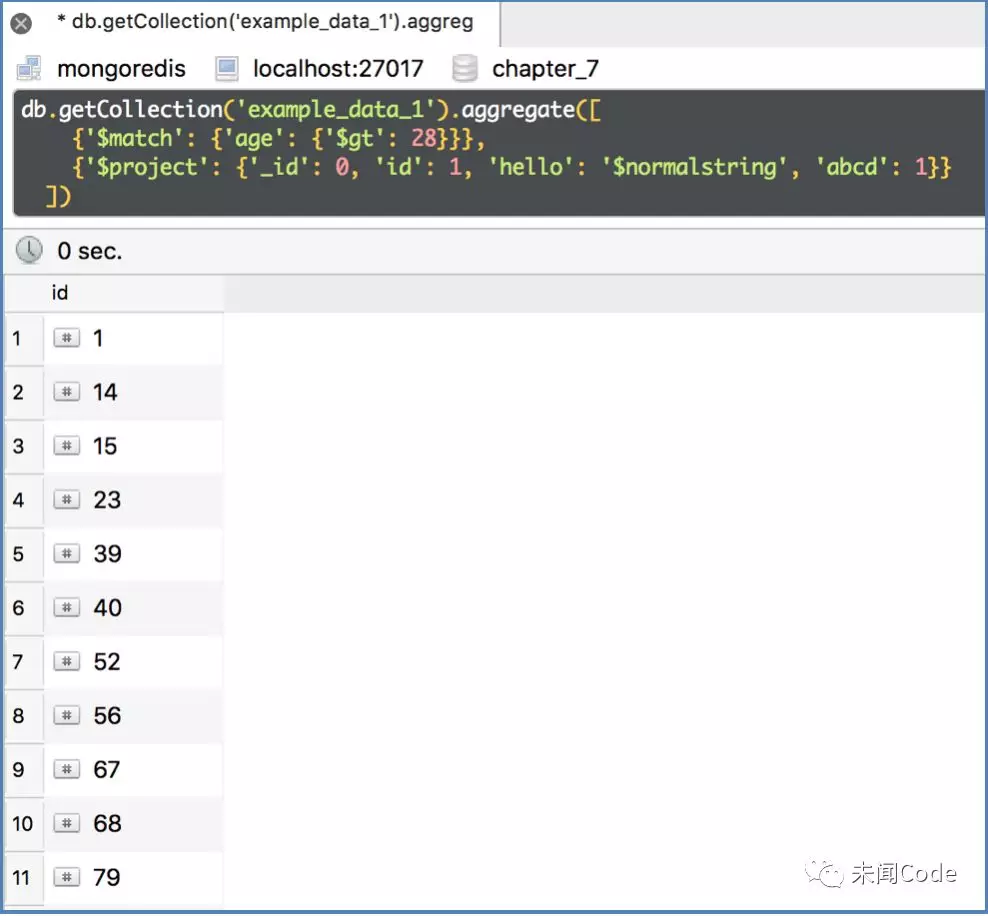
由于特殊字段的值和“$project”的自身语法冲突了,导致所有以“$”开头的普通字符串和数字都不能添加。要解决这个问题,就需要使用另一个关键字“$literal”,代码如下:
db.getCollection('example_data_1').aggregate([{'$match': {'age': {'$gt': 28}}},{'$project': {'_id': 0, 'id': 1, 'hello': {'$literal': '$normalstring'}, 'abcd': {'$literal': 1}}}])
查询结果如图7-30所示。

转自:公众号 kingname 未闻Code
mongo的聚合操作的更多相关文章
- MongoTemplate聚合操作
Aggregation简单来说,就是提供数据统计.分析.分类的方法,这与mapreduce有异曲同工之处,只不过mongodb做了更多的封装与优化,让数据操作更加便捷和易用.Aggregation操作 ...
- 《Entity Framework 6 Recipes》中文翻译系列 (27) ------ 第五章 加载实体和导航属性之关联实体过滤、排序、执行聚合操作
翻译的初衷以及为什么选择<Entity Framework 6 Recipes>来学习,请看本系列开篇 5-9 关联实体过滤和排序 问题 你有一实体的实例,你想加载应用了过滤和排序的相关 ...
- MongoDB 聚合操作
在MongoDB中,有两种方式计算聚合:Pipeline 和 MapReduce.Pipeline查询速度快于MapReduce,但是MapReduce的强大之处在于能够在多台Server上并行执行复 ...
- .NET LINQ 聚合操作
聚合操作 聚合运算从值集合计算单个值. 从一个月的日温度值计算日平均温度就是聚合运算的一个示例. 方法 方法名 说明 C# 查询表达式语法 Visual Basic 查询表达式语法 更多信息 ...
- Linq查询操作之聚合操作(count,max,min,sum,average,aggregate,longcount)
在Linq中有一些这样的操作,根据集合计算某一单一值,比如集合的最大值,最小值,平均值等等.Linq中包含7种操作,这7种操作被称作聚合操作. 1.Count操作,计算序列中元素的个数,或者计算满足一 ...
- OpenStack/Gnocchi简介——时间序列数据聚合操作提前计算并存储起来,先算后取的理念
先看下 http://www.cnblogs.com/bonelee/p/6236962.html 这里对于环形数据库的介绍,便于理解归档这个操作! 转自:http://blog.sina.com.c ...
- JDK1.8聚合操作
在java8 JDK包含许多聚合操作(如平均值,总和,最小,最大,和计数),返回一个计算流stream的聚合结果.这些聚合操作被称为聚合操作.JDK除返回单个值的聚合操作外,还有很多聚合操作返回一个c ...
- ElasticSearch 学习记录之ES几种常见的聚合操作
ES几种常见的聚合操作 普通聚合 POST /product/_search { "size": 0, "aggs": { "agg_city&quo ...
- MongoDB 基本操作和聚合操作
一 . MongoDB 基本操作 基本操作可以简单分为查询.插入.更新.删除. 1 文档查询 作用 MySQL SQL MongoDB 所有记录 SELECT * FROM users; db ...
随机推荐
- PHP--foreach的问题
<?php echo "<pre>"; $data = ['a', 'b', 'c']; foreach($data as $key => $val){ $ ...
- Python如何让字典保持有序
问题: Python如何让字典保持有序 ? 解决方案: 使用collections.OrderedDict代替Dict. 验证程序: from collections import OrderedDi ...
- 软件测试人必备的 Python 知识图
之前发过蛮多不少关于 Python 学习的文章,收到大家不少的好评,不过大家也有许多困惑: 现在测试不好做,是不是真的该重新去学一门热门的语言? 入门 Python 该学哪些知识点?该看哪些书? 可以 ...
- Java里观察者模式(订阅发布模式)
创建主题(Subject)接口 创建订阅者(Observer)接口 实现主题 实现观察者 测试 总结 在公司开发项目,如果碰到一些在特定条件下触发某些逻辑操作的功能的实现基本上都是用的定时器 比如用户 ...
- Animate.css动画库,简单的使用,以及源码剖析
animate.css是什么?能做些什么? animate.css是一个css动画库,使用它可以很方便的快捷的实现,我们想要的动画效果,而省去了操作js的麻烦.同时呢,它也是一个开源的库,在GitHu ...
- Python知识点汇总
*/ * Copyright (c) 2016,烟台大学计算机与控制工程学院 * All rights reserved. * 文件名:text.cpp * 作者:常轩 * 微信公众号:Worldhe ...
- 自动清理IIS log 日志脚本
系统环境:windows server 2012 r2 IIS 版本:IIS8 操作实现清理IIS log File 脚本如下: @echo off ::自动清理IIS Log file set lo ...
- TypeScript声明文件
为什么需要声明? 声明的本质是告知编译器一个标识符的类型信息.同时,在使用第三方库时,我们需要引用它的声明文件,才能获得对应的代码补全.接口提示等功能. 声明在TypeScript中至关重要,只有通过 ...
- django之初建项目
一.项目预览 1.在创建项目之前,必须先进入虚拟环境,因为我们的包安装在我们的虚拟环境中,不在我们的中环境中 >>> ./venv/Scripts/activate 2.创建一个项目 ...
- harbor自动清理镜像
harbor定时清理镜像 分享下最近写harbor仓库镜像自动清理脚本思路,很长时间不写shell脚本,这次的脚本也是匆匆写的,还有很多可优化点,感兴趣的可以参考自己优化下,写的不完善地方也希望指 ...