感知器基础原理及python实现
简单版本,按照李航的《统计学习方法》的思路编写

数据采用了著名的sklearn自带的iries数据,最优化求解采用了SGD算法。
预处理增加了标准化操作。
'''
perceptron classifier created on 2019.9.14
author: vince
'''
import pandas
import numpy
import logging
import matplotlib.pyplot as plt from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score '''
perceptron classifier Attributes
w: ld-array = weights after training
l: list = number of misclassification during each iteration
'''
class Perceptron:
def __init__(self, eta = 0.01, iter_num = 50, batch_size = 1):
'''
eta: float = learning rate (between 0.0 and 1.0).
iter_num: int = iteration over the training dataset.
batch_size: int = gradient descent batch number,
if batch_size == 1, used SGD;
if batch_size == 0, use BGD;
else MBGD;
''' self.eta = eta;
self.iter_num = iter_num;
self.batch_size = batch_size; def train(self, X, Y):
'''
train training data.
X:{array-like}, shape=[n_samples, n_features] = Training vectors,
where n_samples is the number of training samples and
n_features is the number of features.
Y:{array-like}, share=[n_samples] = traget values.
'''
self.w = numpy.zeros(1 + X.shape[1]);
self.l = numpy.zeros(self.iter_num);
for iter_index in range(self.iter_num):
for sample_index in range(X.shape[0]):
if (self.activation(X[sample_index]) != Y[sample_index]):
logging.debug("%s: pred(%s), label(%s), %s, %s" % (sample_index,
self.net_input(X[sample_index]) , Y[sample_index],
X[sample_index, 0], X[sample_index, 1]));
self.l[iter_index] += 1;
for sample_index in range(X.shape[0]):
if (self.activation(X[sample_index]) != Y[sample_index]):
self.w[0] += self.eta * Y[sample_index];
self.w[1:] += self.eta * numpy.dot(X[sample_index], Y[sample_index]);
break;
logging.info("iter %s: %s, %s, %s, %s" %
(iter_index, self.w[0], self.w[1], self.w[2], self.l[iter_index])); def activation(self, x):
return numpy.where(self.net_input(x) >= 0.0 , 1 , -1); def net_input(self, x):
return numpy.dot(x, self.w[1:]) + self.w[0]; def predict(self, x):
return self.activation(x); def main():
logging.basicConfig(level = logging.INFO,
format = '%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt = '%a, %d %b %Y %H:%M:%S'); iris = load_iris(); features = iris.data[:99, [0, 2]];
# normalization
features_std = numpy.copy(features);
for i in range(features.shape[1]):
features_std[:, i] = (features_std[:, i] - features[:, i].mean()) / features[:, i].std(); labels = numpy.where(iris.target[:99] == 0, -1, 1); # 2/3 data from training, 1/3 data for testing
train_features, test_features, train_labels, test_labels = train_test_split(
features_std, labels, test_size = 0.33, random_state = 23323); logging.info("train set shape:%s" % (str(train_features.shape))); p = Perceptron(); p.train(train_features, train_labels); test_predict = numpy.array([]);
for feature in test_features:
predict_label = p.predict(feature);
test_predict = numpy.append(test_predict, predict_label); score = accuracy_score(test_labels, test_predict);
logging.info("The accruacy score is: %s "% (str(score))); #plot
x_min, x_max = train_features[:, 0].min() - 1, train_features[:, 0].max() + 1;
y_min, y_max = train_features[:, 1].min() - 1, train_features[:, 1].max() + 1;
plt.xlim(x_min, x_max);
plt.ylim(y_min, y_max);
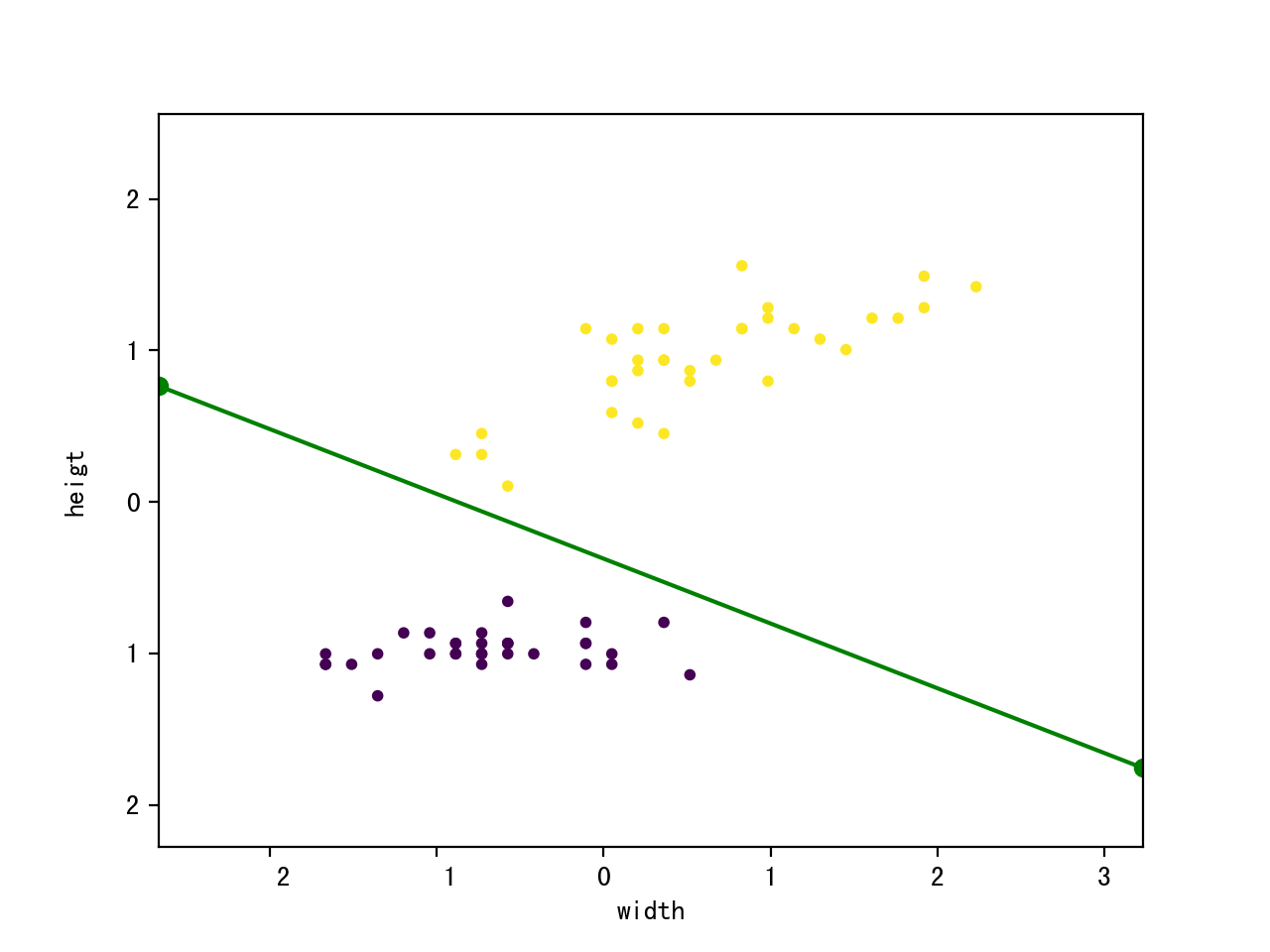
plt.xlabel("width");
plt.ylabel("heigt"); plt.scatter(train_features[:, 0], train_features[:, 1], c = train_labels, marker = 'o', s = 10); k = - p.w[1] / p.w[2];
d = - p.w[0] / p.w[2]; plt.plot([x_min, x_max], [k * x_min + d, k * x_max + d], "go-"); plt.show(); if __name__ == "__main__":
main();
感知器基础原理及python实现的更多相关文章
- 机器学习之感知器算法原理和Python实现
(1)感知器模型 感知器模型包含多个输入节点:X0-Xn,权重矩阵W0-Wn(其中X0和W0代表的偏置因子,一般X0=1,图中X0处应该是Xn)一个输出节点O,激活函数是sign函数. (2)感知器学 ...
- 机器学习:Python实现单层Rosenblatt感知器
如果对Rosenblatt感知器不了解,可以先查看下相关定义,然后对照下面的代码来理解. 代码中详细解释了各步骤的含义,有些涉及到了数学公式的解释. 这篇文章是以理解Rosenblatt感知器的原理为 ...
- RBF神经网络学习算法及与多层感知器的比较
对于RBF神经网络的原理已经在我的博文<机器学习之径向基神经网络(RBF NN)>中介绍过,这里不再重复.今天要介绍的是常用的RBF神经网络学习算法及RBF神经网络与多层感知器网络的对比. ...
- 感知器做二分类的原理及python实现
本文目录: 1. 感知器 2. 感知器的训练法则 3. 梯度下降和delta法则 4. python实现 1. 感知器[1] 人工神经网络以感知器(perceptron)为基础.感知器以一个实数值向量 ...
- python之感知器-从零开始学深度学习
感知器-从零开始学深度学习 未来将是人工智能和大数据的时代,是各行各业使用人工智能在云上处理大数据的时代,深度学习将是新时代的一大利器,在此我将从零开始记录深度学习的学习历程. 我希望在学习过程中做到 ...
- 【转】【python】装饰器的原理
写在前面: 在开发OpenStack过程中,经常可以看到代码中的各种注解,自己也去查阅了资料,了解了这是python中的装饰器,因为弱类型的语言可以将函数当成返回值返回,这就是装饰器的原理. 虽然说知 ...
- 机器学习 —— 基础整理(六)线性判别函数:感知器、松弛算法、Ho-Kashyap算法
这篇总结继续复习分类问题.本文简单整理了以下内容: (一)线性判别函数与广义线性判别函数 (二)感知器 (三)松弛算法 (四)Ho-Kashyap算法 闲话:本篇是本系列[机器学习基础整理]在time ...
- 感知器算法--python实现
写在前面: 参考: 1 <统计学习方法>第二章感知机[感知机的概念.误分类的判断] http://pan.baidu.com/s/1hrTscza 2 点到面的距离 3 梯度 ...
- Python开发基础-Day7-闭包函数和装饰器基础
补充:全局变量声明及局部变量引用 python引用变量的顺序: 当前作用域局部变量->外层作用域变量->当前模块中的全局变量->python内置变量 global关键字用来在函数或其 ...
随机推荐
- 关于css 的垂直居中
对于元素的水平居中,我根据我自己之前的一些学习来进行一些总结,如果有不对的地方,欢迎指正~ 一.让大小不固定的元素垂直居中 因为:表格的单元格的特别属性:垂直居中等: `div.parent { di ...
- 前端每日实战:26# 视频演示如何用不到 50 行 CSS 代码,创作按钮被从纸上掀起的立体效果
效果预览 按下右侧的"点击预览"按钮可以在当前页面预览,点击链接可以全屏预览. https://codepen.io/comehope/pen/KRbXGe 可交互视频教程 此视频 ...
- Ubuntu16.04下安装python3.6.4详细步骤
记录一下: Ubuntu16.04自带的python版本为python2.7和python3.5,现在想要安装python3.6.4,注意:系统自带的python版本别删除 步骤: # 官网下载安装包 ...
- aosp Pixel 修改 SIM 卡支持及解决网络带x问题
去除网络X的方法 adb shell settings put global captive_portal_https_url http://g.cn/generate_204 自己用 php 做一个 ...
- Excel之在单元格中生成随机密码
公式 =CHAR(INT(RAND()*26+97))&INT(RAND()*10)&CHAR(INT(RAND()*26+97))&INT(RAND()*10) 分析 CHA ...
- node打开本地应用程序
1.打开浏览器 最简单的方法: const cp = require('child_process') cp.exec('start http://127.0.0.1:8889/'); // 自动打开 ...
- Vue2.0 【第一季】第6节 v-model指令
目录 Vue2.0 [第一季] 第6节 v-model指令 第6节 v-model指令 一.一个最简单的双向数据绑定代码: 二.修饰符 三.文本区域加入数据绑定 四.多选按钮绑定一个值 五.多选绑定一 ...
- Redis集群搭建及选举原理
redis集群简述 哨兵模式中如果主从中master宕机了,是通过哨兵来选举出新的master,在这个选举切换主从的过程,整个redis服务是不可用的.而且哨兵模式中只有一个主节点对外提供服务,因此没 ...
- element中的树形组件,如何获取父级菜单的id
一般多选的树形组件,使用getCheckedNodes()方法只能获取到本级的菜单id,只有在子菜单全部选中的情况下才会选中上级.但我们想要不全选中子级的情况下也要获取它的上级,甚至上上级等,怎么办呢 ...
- tkinter学习1
GUI 用户交互界面 tkinter 介绍 tkinter是 python自带的gui库,对图像处理库tk的封装 #导入tkinter库 import tkinter #创建主窗口对象 root = ...