感知器做二分类的原理及python实现
本文目录:
1. 感知器
2. 感知器的训练法则
3. 梯度下降和delta法则
4. python实现
1. 感知器[1]
人工神经网络以感知器(perceptron)为基础。感知器以一个实数值向量作为输入,计算这些输入的线性组合,然后如果结果大于某个阈值,就输出1,否则输出-1(或0)。更精确地,如果输入为$x_1$到$x_n$,那么感知器计算的输出为:

其中,$w_i$是实数常量,叫做权值,用来决定输入$x_i$对感知器输出的贡献率。因为仅以一个阈值来决定输出,我们有时也把这种感知器叫做硬限幅感知器,当输出为1和-1时,也叫做sgn感知器(符号感知器)。
2. 感知器的训练法则[1]
感知器的学习任务是决定一个权向量,它可以是感知器对于给定的训练样例输出正确的1或-1。为得到可接受的权向量,一种办法是从随机的权值开始,然后反复应用这个感知器到每一个训练样例,只要它误分类样例就修改感知器的权值。重复这个过程,直到感知器正确分类所有的训练样例。每一步根据感知器训练法则(perceptron Iraining rule) 来修改权值:${w_{i + 1}} \leftarrow {w_i} + \Delta {w_i}$,其中$\Delta {w_i} = \eta (t - o){x_i}$,$\eta$是学习速率,用来缓和或者加速每一步调整权值的程度。

3. 梯度下降和delta法则[1]








4. python实现[2]
训练数据:总共500个训练样本,链接https://pan.baidu.com/s/1qWugzIzdN9qZUnEw4kWcww,提取码:ncuj
损失函数:均方误差(MSE)
代码如下:
import numpy as np
import matplotlib.pyplot as plt class hardlim():
def __init__(self, path):
self.path = path def file2matrix(self, delimiter):
fp = open(self.path, 'r')
content = fp.read() # content现在是一行字符串,该字符串包含文件所有内容
fp.close()
rowlist = content.splitlines() # 按行转换为一维表
# 逐行遍历
# 结果按分隔符分割为行向量
recordlist = [list(map(float, row.split(delimiter))) for row in rowlist if row.strip()]
return np.mat(recordlist) def drawScatterbyLabel(self, dataSet):
m, n = dataSet.shape
target = np.array(dataSet[:, -1])
target = target.squeeze() # 把二维数据变为一维数据
for i in range(m):
if target[i] == 0:
plt.scatter(dataSet[i, 0], dataSet[i, 1], c='blue', marker='o')
if target[i] == 1:
plt.scatter(dataSet[i, 0], dataSet[i, 1], c='red', marker='o') def buildMat(self, dataSet):
m, n = dataSet.shape
dataMat = np.zeros((m, n))
dataMat[:, 0] = 1
dataMat[:, 1:] = dataSet[:, :-1]
return dataMat def classfier(self, x):
x[x >= 0.5] = 1
x[x < 0.5] = 0
return x if __name__ == '__main__':
hardlimit = hardlim('testSet.txt') print('1. 导入数据')
inputData = hardlimit.file2matrix('\t')
target = inputData[:, -1]
m, n = inputData.shape
print('size of input data: {} * {}'.format(m, n)) print('2. 按分类绘制散点图')
hardlimit.drawScatterbyLabel(inputData) print('3. 构建系数矩阵')
dataMat = hardlimit.buildMat(inputData) alpha = 0.1 # learning rate
steps = 600 # total iterations
weights = np.ones((n, 1)) # initialize weights
weightlist = [] print('4. 训练模型')
for k in range(steps):
output = hardlimit.classfier(dataMat * np.mat(weights))
errors = target - output
print('iteration: {} error_norm: {}'.format(k, np.linalg.norm(errors)))
weights = weights + alpha*dataMat.T*errors # 梯度下降
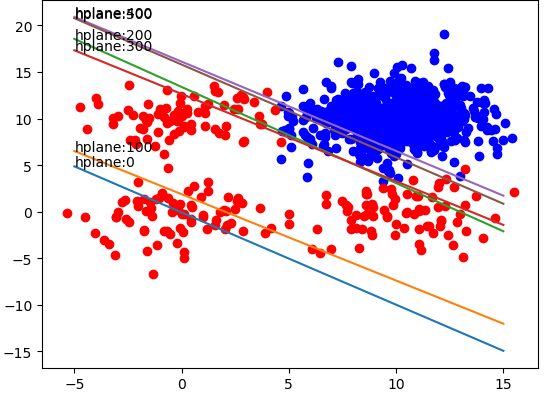
weightlist.append(weights) print('5. 画出训练过程')
X = np.linspace(-5, 15, 301)
weights = np.array(weights)
length = len(weightlist)
for idx in range(length):
if idx % 100 == 0:
weight = np.array(weightlist[idx])
Y = -(weight[0] + X * weight[1]) / weight[2]
plt.plot(X, Y)
plt.annotate('hplane:' + str(idx), xy=(X[0], Y[0]))
plt.show() print('6. 应用模型到测试数据中')
testdata = np.mat([-0.147324, 2.874846]) # 测试数据
m, n = testdata.shape
testmat = np.zeros((m, n+1))
testmat[:, 0] = 1
testmat[:, 1:] = testdata
result = sum(testmat * (np.mat(weights)))
if result < 0.5:
print(0)
else:
print(1)
训练结果如下:
【参考文献】
《机器学习》Mitshell,第四章
《机器学习算法原理与编程实践》郑捷,第五章5.2.2
感知器做二分类的原理及python实现的更多相关文章
- softmax分类算法原理(用python实现)
逻辑回归神经网络实现手写数字识别 如果更习惯看Jupyter的形式,请戳Gitthub_逻辑回归softmax神经网络实现手写数字识别.ipynb 1 - 导入模块 import numpy as n ...
- 逻辑回归(Logistic Regression)二分类原理及python实现
本文目录: 1. sigmoid function (logistic function) 2. 逻辑回归二分类模型 3. 神经网络做二分类问题 4. python实现神经网络做二分类问题 1. si ...
- Python_sklearn机器学习库学习笔记(七)the perceptron(感知器)
一.感知器 感知器是Frank Rosenblatt在1957年就职于Cornell航空实验室时发明的,其灵感来自于对人脑的仿真,大脑是处理信息的神经元(neurons)细胞和链接神经元细胞进行信息传 ...
- 二、单层感知器和BP神经网络算法
一.单层感知器 1958年[仅仅60年前]美国心理学家FrankRosenblant剔除一种具有单层计算单元的神经网络,称为Perceptron,即感知器.感知器研究中首次提出了自组织.自学习的思想, ...
- 【2008nmj】Logistic回归二元分类感知器算法.docx
给你一堆样本数据(xi,yi),并标上标签[0,1],让你建立模型(分类感知器二元),对于新给的测试数据进行分类. 要将两种数据分开,这是一个分类问题,建立数学模型,(x,y,z),z指示[0,1], ...
- 人工神经网络(从原理到代码) Step 01 感知器 梯度下降
版权声明: 本文由SimonLiang所有,发布于http://www.cnblogs.com/idignew/.如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任. 感知器 ...
- tensorflow学习笔记——自编码器及多层感知器
1,自编码器简介 传统机器学习任务很大程度上依赖于好的特征工程,比如对数值型,日期时间型,种类型等特征的提取.特征工程往往是非常耗时耗力的,在图像,语音和视频中提取到有效的特征就更难了,工程师必须在这 ...
- python之感知器-从零开始学深度学习
感知器-从零开始学深度学习 未来将是人工智能和大数据的时代,是各行各业使用人工智能在云上处理大数据的时代,深度学习将是新时代的一大利器,在此我将从零开始记录深度学习的学习历程. 我希望在学习过程中做到 ...
- 深度学习炼丹术 —— Taoye不讲码德,又水文了,居然写感知器这么简单的内容
手撕机器学习系列文章就暂时更新到此吧,目前已经完成了支持向量机SVM.决策树.KNN.贝叶斯.线性回归.Logistic回归,其他算法还请允许Taoye在这里先赊个账,后期有机会有时间再给大家补上. ...
随机推荐
- mysql_config_editor设置
[root@node01 etc]# mysql_config_editor set -G mysql3307 -S /tmp/mysql3307.sock -uroot -pEnter passwo ...
- 调用WebService接口返回字符串
Service service = new Service(); Call call = (Call) service.createCall(); call.setTargetEndpointAddr ...
- HDU 5527 Too Rich ( 15长春区域赛 A 、可贪心的凑硬币问题 )
题目链接 题意 : 给出一些固定面值的硬币的数量.再给你一个总金额.问你最多能用多少硬币来刚好凑够这个金额.硬币数量和总金额都很大 分析 : 长春赛区的金牌题目 一开始认为除了做类似背包DP那样子 ...
- IntelliJ 如何显示代码的代码 docs
希望能够在 IntelliJ 代码上面显示方法的 docs. 如何进行显示? 你可以使用 Ctrl + Q 这个快捷键来查看方法的 Docs. https://blog.ossez.com/archi ...
- Java基础语法n
BK 分段函数(SDUT 2257) import java.util.*; public class Main{ public static void main(String[] args ...
- openstack导入镜像
本文以制作CentOS7.2镜像为例,详细介绍手动制作OpenStack镜像详细步骤,解释每一步这么做的原因.镜像上传到OpenStack glance,支持以下几个功能: 支持密码注入功能(nova ...
- Jquery 2.0+版本不支持IE8,如何解决?
用了JQuery2.0+以后,在IE8下会报错,下面是我的方法. 先看代码: <!--[if !IE]> --> <script src="/Scrip ...
- Jmeter工具做接口测试
一.安装Jmeter 1.安装JDK ①下载jdk,到官网下载jdk,地址:http://jmeter.apache.org/download_jmeter.cgi ② 安装jdk(Oracle官网下 ...
- Namenode服务挂
BUG修复:HDFS-13112 这两天排查了小集群Crash的问题,这里先总结下这两天排查的结果 一.查看日志 首先查看了Namenode Crash的时候的日志 (一)以下是patch hdfs- ...
- 教你快速写一个EventBus框架
前言EventBus相信大多数人都用过,其具有方便灵活.解耦性强.体积小.简单易用等优点,虽然现在也有很多优秀的替代方案如RxBus.LiveDataBus等,但不可否认EventBus开创了消息总线 ...