聚类算法——DBSCAN算法原理及公式
聚类的定义
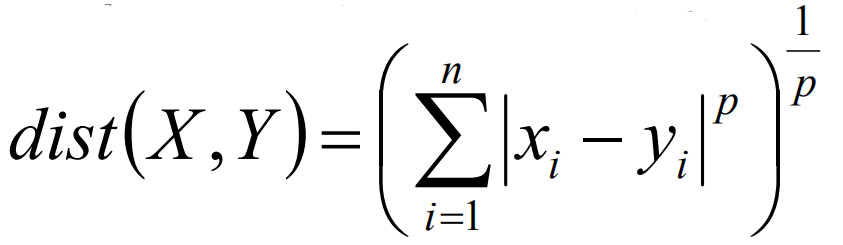
在上述的计算中,当p=1时,则是计算绝对值距离,通常叫做曼哈顿距离,当p=2时,表述的是欧式距离。
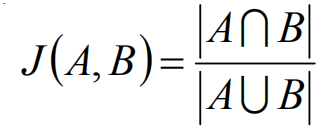
杰卡德相关系数主要用于描述集合之间的相似度,在目标检测中,iou的计算就和此公式相类似
余弦相似度
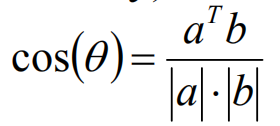
余弦相似度通过夹角的余弦来描述相似性
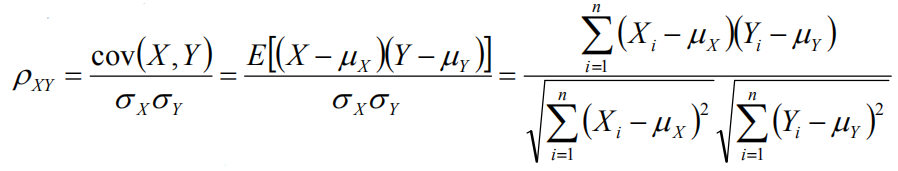
相对熵(K-L距离)
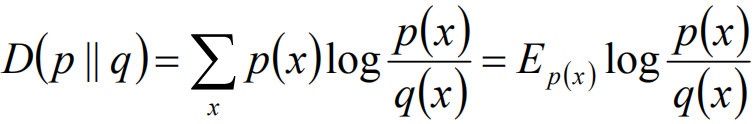
相对熵的相似度是不对称的相似度,D(p||q)不一定等于D(q||p)。
聚类的基本思想
给定一个有N个对象的数据集,划分聚类的技术将构造数据的K个划分,每个划分代表一个簇,K<=n。也就是说,聚类将数据划分为k个簇,而且这k个划分满足下列条件:
每个簇至少包含一个对象,每一个对象属于且仅属于一个簇。
具体的步骤为,对于给定的k,算法首先给出一个初始的划分方法。以后通过反复迭代的方法改变划分,使得每一次改进之后的划分方案都较前一次更好。
密度聚类
密度聚类方法的指导思想是,只要一个区域中的点的密度大于某个阈值,就把它加到与之相近的聚类中去。这类算法能够克服基于距离的算法只能发现“类圆形”的聚类的缺点,可以发现任意形状的聚类,且对噪声数据不敏感。但计算密度单元的计算复杂度大,需要建立空间索引来降低计算量。
DBSCAN算法
DBSCAN是一个比较有代表性的基于密度聚类的聚类算法,它对簇的定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在有噪声的数据中发现任意形状的聚类。
DBSCAN相关定义
对象的ε-邻域:给定对象在半径ε内的区域。
核心对象:对于给定的数据m,如果一个对象的ε-邻域至少包含有m个对象,则成为该对象的核心对象。
直接密度可达:给定一个对象集合D,如果p是在q的ε-邻域内,而q是一个核心对象,则对象p从对象q出发是直接密度可达的。
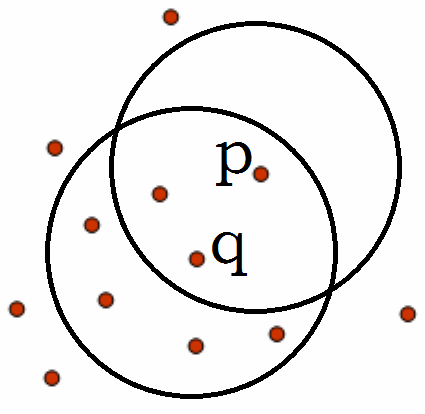
密度可达:如果存在一个对象链p1p2···pn,p1=q,pn=p,对pi属于D,pi+1是从pi关于ε和m直接密度可达的,则对象p是从对象q关于ε和m密度可达的。
密度相连:如果对象集合D中存在一个对象o,使得对象p和q是从o关于ε和m密度可达的,那么对象p和q是关于ε和m密度相连的。
簇:一个基于密度的簇是最大的密度相连对象的集合。
噪声:不包含在任何簇中的对象称为噪声。
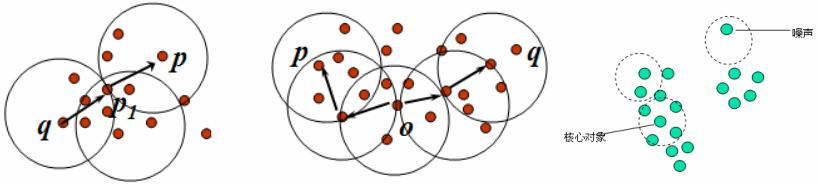
DBSCAN通过检查数据集中的每个对象的ε-邻域来寻找聚类,如果一个点p的ε-邻域包含对于m个对象,则创建一个p作为核心对象的新簇。然后,DBSCAN反复地寻找这些核心对象直接密度可达的对象,这个过程可能涉及密度可达簇的合并。当没有新的点可以被添加到任何簇时,该过程结束。算法的中ε和m是根据先验知识来给出的。
聚类算法——DBSCAN算法原理及公式的更多相关文章
- 基于密度的聚类之Dbscan算法
一.算法概述 DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法.与划分和层次 ...
- 机器学习--聚类系列--DBSCAN算法
DBSCAN算法 基本概念:(Density-Based Spatial Clustering of Applications with Noise) 核心对象:若某个点的密度达到算法设定的阈值则其为 ...
- 聚类之dbscan算法
简要的说明: dbscan为一个密度聚类算法,无需指定聚类个数. python的简单实例: # coding:utf-8 from sklearn.cluster import DBSCAN impo ...
- 【转】常用聚类算法(一) DBSCAN算法
原文链接:http://www.cnblogs.com/chaosimple/p/3164775.html#undefined 1.DBSCAN简介 DBSCAN(Density-Based Spat ...
- 常用聚类算法(一) DBSCAN算法
1.DBSCAN简介 DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度 ...
- 基于密度聚类的DBSCAN和kmeans算法比较
根据各行业特性,人们提出了多种聚类算法,简单分为:基于层次.划分.密度.图论.网格和模型的几大类. 其中,基于密度的聚类算法以DBSCAN最具有代表性. 场景 一 假设有如下图的一组数据, 生成数据 ...
- 【原创】大叔算法分享(5)聚类算法DBSCAN
一 简介 DBSCAN:Density-based spatial clustering of applications with noise is a data clustering algorit ...
- 简单易学的机器学习算法—基于密度的聚类算法DBSCAN
简单易学的机器学习算法-基于密度的聚类算法DBSCAN 一.基于密度的聚类算法的概述 我想了解下基于密度的聚类算法,熟悉下基于密度的聚类算法与基于距离的聚类算法,如K-Means算法之间的区别. ...
- 简单易学的机器学习算法——基于密度的聚类算法DBSCAN
一.基于密度的聚类算法的概述 最近在Science上的一篇基于密度的聚类算法<Clustering by fast search and find of density peaks> ...
随机推荐
- 用asp.net core结合fastdfs打造分布式文件存储系统
最近被安排开发文件存储微服务,要求是能够通过配置来无缝切换我们公司内部研发的文件存储系统,FastDFS,MongDb GridFS,阿里云OSS,腾讯云OSS等.根据任务紧急度暂时先完成了通过配置来 ...
- PE文件学习(1)DOS和NT
大致结构 DOS头和NT头之间通常还有个DOS Stub DOS头 DOS头的作用是兼容MS-DOS操作系统中的可执行文件 一般没啥用 记录着PE头的位置 DOS头定义部分 typedef struc ...
- 【Linux网络基础】上网原理流程
1. 局域网用户上网原理 上网过程说明: 确保物理设备和线路架构准备完毕,并且线路通讯状态良好 终端设备需要获取或配置上局域网(私有地址)地址,作为局域网网络标识 当终端设备想上网时,首先确认访问的地 ...
- 【Linux常见命令】ls命令
ls - list directory contents ls命令用于显示指定工作目录下之内容(列出目前工作目录所含之文件及子目录). 语法: ls [OPTION]... [FILE]... l ...
- optparse--强大的命令行参数处理包
optparse,它功能强大,而且易于使用,可以方便地生成标准的.符合Unix/Posix 规范的命令行说明. optparse的简单示例: from optparse import OptionPa ...
- Javascript中的string类型使用UTF-16编码
2019独角兽企业重金招聘Python工程师标准>>> 在JavaScript中,所有的string类型(或者被称为DOMString)都是使用UTF-16编码的. MDN DOMS ...
- google proto buf学习
2019独角兽企业重金招聘Python工程师标准>>> protobuf是Google开发的一个序列化框架,类似XML,JSON,基于二进制,比传统的XML表示同样一段内容要短小得多 ...
- Vs Code中炫酷写代码插件Power Mode的安装配置
扩展栏搜索 Power Mode 安装 安装后重启vs code 文件->首选项->设置 搜索setting.json,点击在setting.json中编辑 打开之后在右侧用户设置里添加以 ...
- 自定义View之Canvas使用
自定义View的绘制流程一般都是这样:提前创建好Paint对象,重写onDraw(),把绘制代码卸载ondraw()里面,大致如下: Paint paint = new Paint(); @Overr ...
- C# richtextbox 自动下拉到最后 方法 & RichTextBox读取txt中文后出现乱码
C# richtextbox 自动滚动到最后 光标到最后 自动显示最后一行 private void richTextBox1_TextChanged(object sender, EventArg ...