【原创】大叔算法分享(5)聚类算法DBSCAN
一 简介
DBSCAN:Density-based spatial clustering of applications with noise
is a data clustering algorithm proposed by Martin Ester, Hans-Peter Kriegel, Jörg Sander and Xiaowei Xu in 1996.It is a density-based clustering algorithm: given a set of points in some space, it groups together points that are closely packed together (points with many nearby neighbors), marking as outliers points that lie alone in low-density regions (whose nearest neighbors are too far away). DBSCAN is one of the most common clustering algorithms and also most cited in scientific literature.
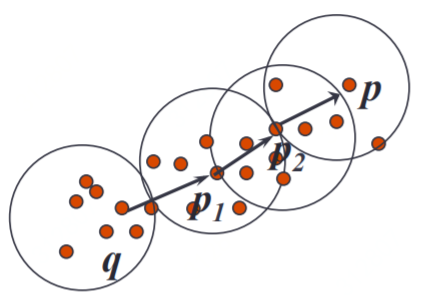
二 原理
DBSCAN是一种基于密度的聚类算法,算法过程比较简单,即将相距较近的点(中心点和它的邻居点)聚成一个cluster,然后不断找邻居点的邻居点并加到这个cluster中,直到cluster无法再扩大,然后再处理其他未访问的点;
三 算法伪代码
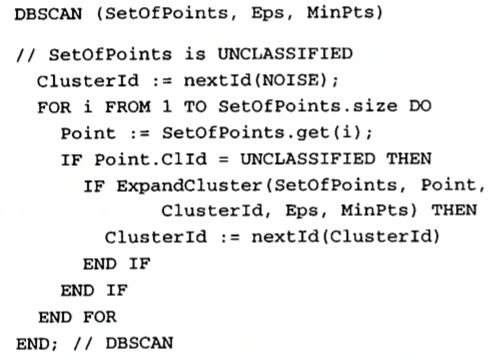
子方法伪代码

DBSCAN requires two parameters: ε (eps) and the minimum number of points required to form a dense region (minPts).
DBSCAN算法主要有两个参数,一个是距离Eps,一个是最小邻居的数量MinPts,即在中心点半径Eps之内的邻居点数量超过MinPts时,中心点和邻居点才可以组成一个cluster;
四 应用代码实现
python
示例代码
def main_fun():
loc_data = [(40.8379295833, -73.70228875), (40.750613794,-73.993434906), (40.6927066969, -73.8085984165), (40.7489736586, -73.9859616017), (40.8379525833, -73.70209875), (40.6997066969, -73.8085234165), (40.7484436586, -73.9857316017)]
epsilon = 10
db = DBSCAN(eps=epsilon, min_samples=1, algorithm='ball_tree', metric='haversine').fit(np.radians(loc_data))
labels = db.labels_
print(labels)
print(db.core_sample_indices_)
print(db.components_)
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
for i in range(0, n_clusters_):
print(i)
indexs = np.where(labels == i)
for j in indexs:
print(loc_data[j]) if __name__ == '__main__':
main_fun()
主要结果说明
|
详见官方文档:https://scikit-learn.org/stable/modules/generated/sklearn.cluster.DBSCAN.html
scala
依赖
<dependency>
<groupId>org.scalanlp</groupId>
<artifactId>nak_2.11</artifactId>
<version>1.3</version>
</dependency><dependency>
<groupId>org.scalanlp</groupId>
<artifactId>breeze_2.11</artifactId>
<version>0.13</version>
</dependency>
示例代码
import breeze.linalg.DenseMatrix
import nak.cluster.{DBSCAN, GDBSCAN, Kmeans} val matrix = DenseMatrix(
(40.8379295833, -73.70228875),
(40.6927066969, -73.8085984165),
(40.7489736586, -73.9859616017),
(40.8379525833, -73.70209875),
(40.6997066969, -73.8085234165),
(40.7484436586, -73.9857316017),
(40.750613794,-73.993434906)) val gdbscan = new GDBSCAN(
DBSCAN.getNeighbours(epsilon = 1000.0, distance = Kmeans.euclideanDistance),
DBSCAN.isCorePoint(minPoints = 1)
)
val clusters = gdbscan cluster matrix
clusters.foreach(cluster => {
println(cluster.id + ", " + cluster.points.length)
cluster.points.foreach(p => p.value.data.foreach(println))
})
详见官方文档:https://github.com/scalanlp/nak
算法细节详见参考
参考:A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise
其他:
http://www.cs.fsu.edu/~ackerman/CIS5930/notes/DBSCAN.pdf
https://www.oreilly.com/ideas/clustering-geolocated-data-using-spark-and-dbscan
【原创】大叔算法分享(5)聚类算法DBSCAN的更多相关文章
- 机器学习算法总结(五)——聚类算法(K-means,密度聚类,层次聚类)
本文介绍无监督学习算法,无监督学习是在样本的标签未知的情况下,根据样本的内在规律对样本进行分类,常见的无监督学习就是聚类算法. 在监督学习中我们常根据模型的误差来衡量模型的好坏,通过优化损失函数来改善 ...
- 数据挖掘十大算法--K-均值聚类算法
一.相异度计算 在正式讨论聚类前,我们要先弄清楚一个问题:怎样定量计算两个可比較元素间的相异度.用通俗的话说.相异度就是两个东西区别有多大.比如人类与章鱼的相异度明显大于人类与黑猩猩的相异度,这是能 ...
- 【算法】K-Means聚类算法(k-平均或k-均值)
1.聚类算法和分类算法的区别 a)分类 分类(Categorization or Classification)就是按照某种标准给对象贴标签(label),再根据标签来区分归类. 举例: 假如你有一堆 ...
- 关于k-means聚类算法的matlab实现
在数据挖掘中聚类和分类的原理被广泛的应用. 聚类即无监督的学习. 分类即有监督的学习. 通俗一点的讲就是:聚类之前是未知样本的分类.而是根据样本本身的相似性进行划分为相似的类簇.而分类 是已知样本分类 ...
- 一步步教你轻松学K-means聚类算法
一步步教你轻松学K-means聚类算法(白宁超 2018年9月13日09:10:33) 导读:k-均值算法(英文:k-means clustering),属于比较常用的算法之一,文本首先介绍聚类的理 ...
- python聚类算法实战详细笔记 (python3.6+(win10、Linux))
python聚类算法实战详细笔记 (python3.6+(win10.Linux)) 一.基本概念: 1.计算TF-DIF TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库 ...
- 模糊聚类算法(FCM)
伴随着模糊集理论的形成.发展和深化,RusPini率先提出模糊划分的概念.以此为起点和基础,模糊聚类理论和方法迅速蓬勃发展起来.针对不同的应用,人们提出了很多模糊聚类算法,比较典型的有基于相似性关系和 ...
- ML.NET技术研究系列-2聚类算法KMeans
上一篇博文我们介绍了ML.NET 的入门: ML.NET技术研究系列1-入门篇 本文我们继续,研究分享一下聚类算法k-means. 一.k-means算法简介 k-means算法是一种聚类算法,所谓聚 ...
- SIGAI机器学习第二十四集 聚类算法1
讲授聚类算法的基本概念,算法的分类,层次聚类,K均值算法,EM算法,DBSCAN算法,OPTICS算法,mean shift算法,谱聚类算法,实际应用. 大纲: 聚类问题简介聚类算法的分类层次聚类算法 ...
- 【Python机器学习实战】聚类算法(1)——K-Means聚类
实战部分主要针对某一具体算法对其原理进行较为详细的介绍,然后进行简单地实现(可能对算法性能考虑欠缺),这一部分主要介绍一些常见的一些聚类算法. K-means聚类算法 0.聚类算法算法简介 聚类算法算 ...
随机推荐
- 分享Winform datagridview 动态生成中文HeaderText
缘起 很久以前给datagridview绑定列的时候都是手动的,记得以前用Display自定义属性来动态给datagridview绑定列.后来发现不行,于是还在博问发了问题: 后来热心网友帮我回答了这 ...
- Binary Search(Java)(非递归)
public static int rank(int[] array, int k) { int front = 0, rear = array.length - 1; while(front < ...
- #Leetcode# 997. Find the Town Judge
https://leetcode.com/problems/find-the-town-judge/ In a town, there are N people labelled from 1 to ...
- MySQL 字符串 分割 多列
mysql如何进行以,分割的字符串的拆分 - 我有一个梦想 - CSDN博客https://blog.csdn.net/u012009613/article/details/52770567 mysq ...
- Mac之日常操作
1.创建root用户使用最高权限 sudo passwd root 一般情况下,使用临时获取最高权限 sudo vim /etc/shells 2. apache操作 #启动Apache sudo a ...
- DAY15、模块
一.函数的补充 1.函数回调: 提前在另一个函数中写出函数的调用,再根据实际的需求去考虑函数体的实现 def download(fn=None): print('开始下载') my_sleep(1) ...
- python json数据的转换
1 Python数据转json字符串 import json json_str = json.dumps(py_data) 参数解析: json_str = json.dumps(py_data,s ...
- SpringCloud实践引入注册中心+配置中心
随着服务数量的增多,尤其是多数项目涉及jni本地方法的调用,所需参数配置较多,同时内存溢出等维护问题时常发生.鉴于此,原tomcat集群的使用已难满足需求,而微服务的思想契合当前项目实践,特在服务端构 ...
- [BZOJ 3745] [COCI 2015] Norma
Description 给定一个正整数序列 \(a_1,a_2,\cdots,a_n\),求 \[ \sum_{i=1}^n\sum_{j=i}^n(j-i+1)\min(a_i,a_{i+1},\c ...
- dubbo接口demo开发
接口需求 客户端输入uncleyong(当然,也可以输入其它字符串),服务端返回hello uncleyong 开发环境 jdk + idea + maven + zookeeper jdk安装 id ...