且谈 Apache Spark 的 API 三剑客:RDD、DataFrame 和 Dataset
作者:Jules S. Damji 译者:足下
本文翻译自 A Tale of Three Apache Spark APIs: RDDs, DataFrames, and Datasets ,翻译已获得原作者 Jules S. Damji 的授权。
最令开发者们高兴的事莫过于有一组 API,可以大大提高开发者们的工作效率,容易使用、非常直观并且富有表现力。Apache Spark 广受开发者们欢迎的一个重要原因也在于它那些非常容易使用的 API,可以方便地通过多种语言,如 Scala、Java、Python 和 R 等来操作大数据集。
在本文中,我将深入讲讲 Apache Spark 2.2 以及以上版本提供的三种 API——RDD、DataFrame 和 Dataset,在什么情况下你该选用哪一种以及为什么,并概述它们的性能和优化点,列举那些应该使用 DataFrame 和 Dataset 而不是 RDD 的场景。我会更多地关注 DataFrame 和 Dataset,因为在 Apache Spark 2.0 中这两种 API 被整合起来了。
这次整合背后的动机在于我们希望可以让使用 Spark 变得更简单,方法就是减少你需要掌握的概念的数量,以及提供处理结构化数据的办法。在处理结构化数据时,Spark 可以像针对特定领域的语言所提供的能力一样,提供高级抽象和 API。
弹性分布式数据集(Resilient Distributed Dataset,RDD)
从一开始 RDD 就是 Spark 提供的面向用户的主要 API。从根本上来说,一个 RDD 就是你的数据的一个不可变的分布式元素集合,在集群中跨节点分布,可以通过若干提供了转换和处理的底层 API 进行并行处理。
在什么情况下使用 RDD?
下面是使用 RDD 的场景和常见案例:
你希望可以对你的数据集进行最基本的转换、处理和控制;
你的数据是非结构化的,比如流媒体或者字符流;
你想通过函数式编程而不是特定领域内的表达来处理你的数据;
你不希望像进行列式处理一样定义一个模式,通过名字或字段来处理或访问数据属性;
你并不在意通过 DataFrame 和 Dataset 进行结构化和半结构化数据处理所能获得的一些优化和性能上的好处;
Apache Spark 2.0 中的 RDD 有哪些改变?
可能你会问:RDD 是不是快要降级成二等公民了?是不是快要退出历史舞台了?
答案是非常坚决的:不!
而且,接下来你还将了解到,你可以通过简单的 API 方法调用在 DataFrame 或 Dataset 与 RDD 之间进行无缝切换,事实上 DataFrame 和 Dataset 也正是基于 RDD 提供的。
DataFrame
与 RDD 相似, DataFrame 也是数据的一个不可变分布式集合。但与 RDD 不同的是,数据都被组织到有名字的列中,就像关系型数据库中的表一样。设计 DataFrame 的目的就是要让对大型数据集的处理变得更简单,它让开发者可以为分布式的数据集指定一个模式,进行更高层次的抽象。它提供了特定领域内专用的 API 来处理你的分布式数据,并让更多的人可以更方便地使用 Spark,而不仅限于专业的数据工程师。
在我们的 Apache Spark 2.0 网络研讨会以及后续的博客中,我们提到在Spark 2.0 中,DataFrame 和 Dataset 的 API 将融合到一起,完成跨函数库的数据处理能力的整合。在整合完成之后,开发者们就不必再去学习或者记忆那么多的概念了,可以通过一套名为 Dataset 的高级并且类型安全的 API 完成工作。
(点击放大图像)

Dataset
如下面的表格所示,从 Spark 2.0 开始,Dataset 开始具有两种不同类型的 API 特征:有明确类型的 API 和无类型的 API。从概念上来说,你可以把 DataFrame 当作一些通用对象 Dataset[Row] 的集合的一个别名,而一行就是一个通用的无类型的 JVM 对象。与之形成对比,Dataset 就是一些有明确类型定义的 JVM 对象的集合,通过你在 Scala 中定义的 Case Class 或者 Java 中的 Class 来指定。
有类型和无类型的 API
语言
主要抽象
Scala
Dataset[T] & DataFrame (Dataset[Row] 的别名)
Java
Dataset[T]
Python
DataFrame
R
DataFrame
注意:因为 Python 和 R 没有编译时类型安全,所以我们只有称之为 DataFrame 的无类型 API。
Dataset API 的优点
在 Spark 2.0 里,DataFrame 和 Dataset 的统一 API 会为 Spark 开发者们带来许多方面的好处。
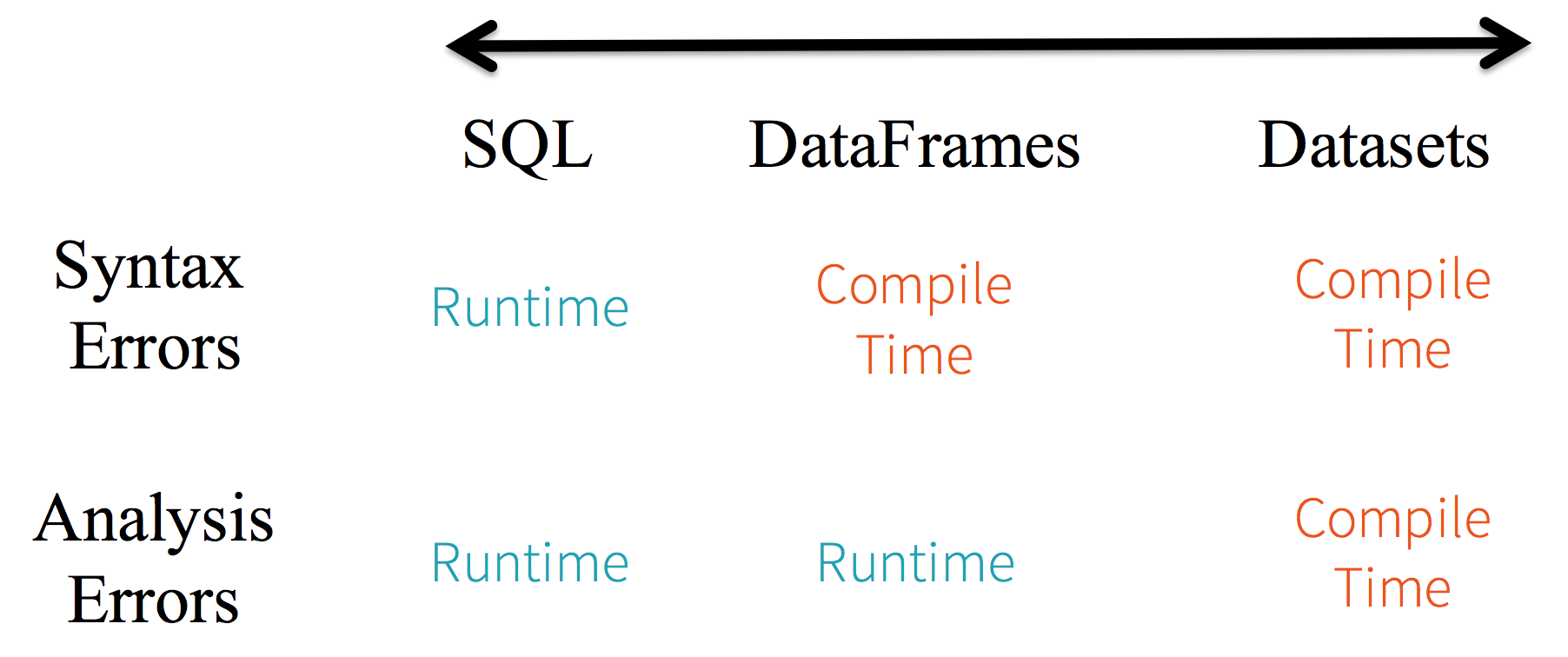
1、静态类型与运行时类型安全
从 SQL 的最小约束到 Dataset 的最严格约束,把静态类型和运行时安全想像成一个图谱。比如,如果你用的是 Spark SQL 的查询语句,要直到运行时你才会发现有语法错误(这样做代价很大),而如果你用的是 DataFrame 和 Dataset,你在编译时就可以捕获错误(这样就节省了开发者的时间和整体代价)。也就是说,当你在 DataFrame 中调用了 API 之外的函数时,编译器就可以发现这个错。不过,如果你使用了一个不存在的字段名字,那就要到运行时才能发现错误了。
图谱的另一端是最严格的 Dataset。因为 Dataset API 都是用 lambda 函数和 JVM 类型对象表示的,所有不匹配的类型参数都可以在编译时发现。而且在使用 Dataset 时,你的分析错误也会在编译时被发现,这样就节省了开发者的时间和代价。
所有这些最终都被解释成关于类型安全的图谱,内容就是你的 Spark 代码里的语法和分析错误。在图谱中,Dataset 是最严格的一端,但对于开发者来说也是效率最高的。
(点击放大图像)
2、关于结构化和半结构化数据的高级抽象和定制视图
把 DataFrame 当成 Dataset[Row] 的集合,就可以对你的半结构化数据有了一个结构化的定制视图。比如,假如你有个非常大量的用 JSON 格式表示的物联网设备事件数据集。因为 JSON 是半结构化的格式,那它就非常适合采用 Dataset 来作为强类型化的 Dataset[DeviceIoTData] 的集合。
{"device_id": 198164, "device_name": "sensor-pad-198164owomcJZ", "ip": "80.55.20.25", "cca2": "PL", "cca3": "POL", "cn": "Poland", "latitude": 53.080000, "longitude": 18.620000, "scale": "Celsius", "temp": 21, "humidity": 65, "battery_level": 8, "c02_level": 1408, "lcd": "red", "timestamp" :1458081226051}
你可以用一个 Scala Case Class 来把每条 JSON 记录都表示为一条 DeviceIoTData,一个定制化的对象。
case class DeviceIoTData (battery_level: Long, c02_level: Long, cca2:
String, cca3: String, cn: String, device_id: Long, device_name: String, humidity:
Long, ip: String, latitude: Double, lcd: String, longitude: Double, scale:String, temp: Long, timestamp: Long)
接下来,我们就可以从一个 JSON 文件中读入数据。
// read the json file and create the dataset from the
// case class DeviceIoTData
// ds is now a collection of JVM Scala objects DeviceIoTData
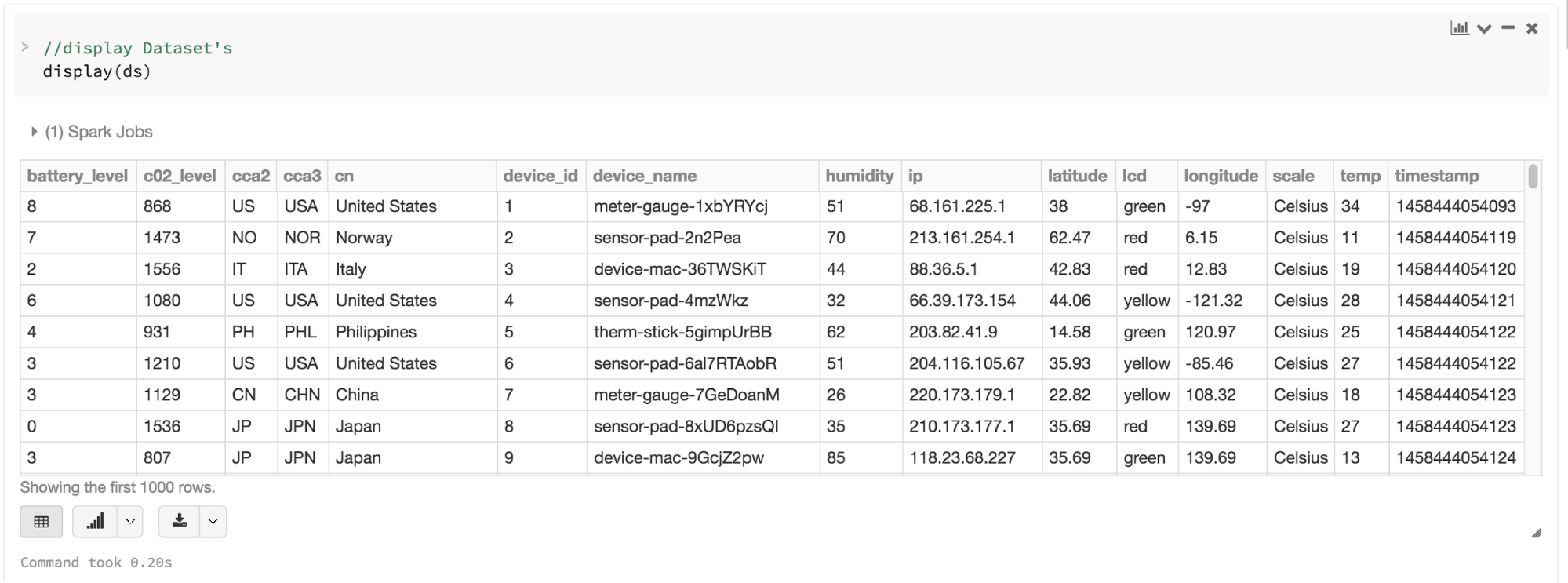
val ds = spark.read.json(“/databricks-public-datasets/data/iot/iot_devices.json”).as[DeviceIoTData]
上面的代码其实可以细分为三步:
Spark 读入 JSON,根据模式创建出一个 DataFrame 的集合;
在这时候,Spark 把你的数据用“DataFrame = Dataset[Row]”进行转换,变成一种通用行对象的集合,因为这时候它还不知道具体的类型;
然后,Spark 就可以按照类 DeviceIoTData 的定义,转换出“Dataset[Row] -> Dataset[DeviceIoTData]”这样特定类型的 Scala JVM 对象了。
许多和结构化数据打过交道的人都习惯于用列的模式查看和处理数据,或者访问对象中的某个特定属性。将 Dataset 作为一个有类型的 Dataset[ElementType] 对象的集合,你就可以非常自然地又得到编译时安全的特性,又为强类型的 JVM 对象获得定制的视图。而且你用上面的代码获得的强类型的 Dataset[T] 也可以非常容易地用高级方法展示或处理。
(点击放大图像)
3、方便易用的结构化 API
虽然结构化可能会限制你的 Spark 程序对数据的控制,但它却提供了丰富的语义,和方便易用的特定领域内的操作,后者可以被表示为高级结构。事实上,用 Dataset 的高级 API 可以完成大多数的计算。比如,它比用 RDD 数据行的数据字段进行 agg、select、sum、avg、map、filter 或 groupBy 等操作简单得多,只需要处理 Dataset 类型的 DeviceIoTData 对象即可。
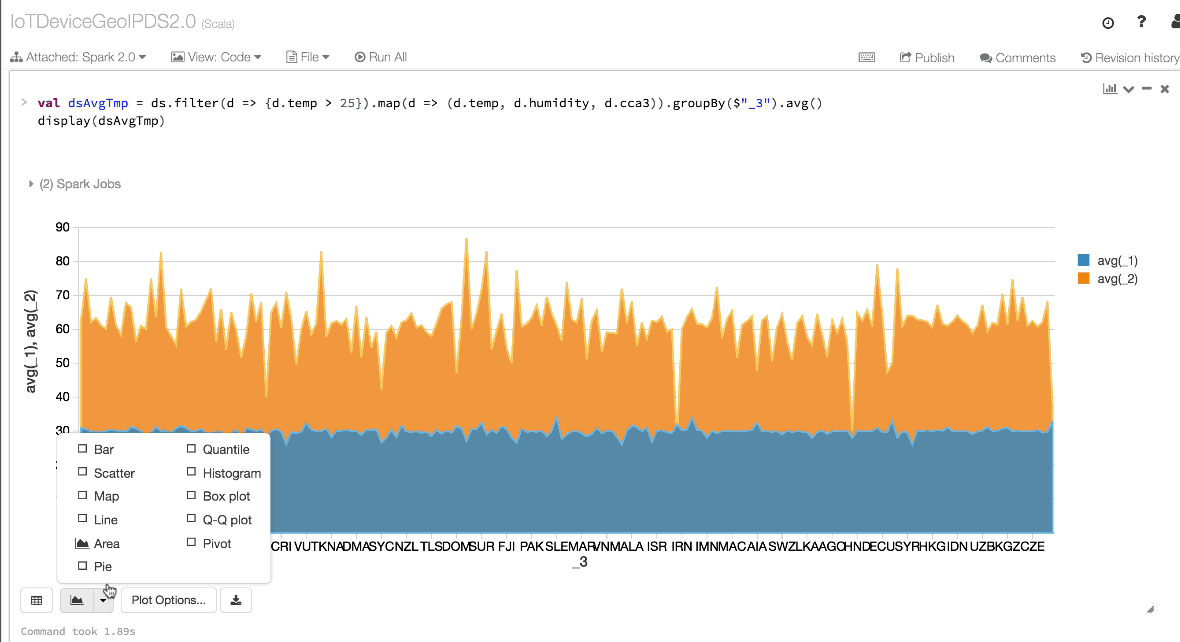
用一套特定领域内的 API 来表达你的算法,比用 RDD 来进行关系代数运算简单得多。比如,下面的代码将用 filter() 和 map() 来创建另一个不可变 Dataset。
// Use filter(), map(), groupBy() country, and compute avg()
// for temperatures and humidity. This operation results in
// another immutable Dataset. The query is simpler to read,
// and expressive
val dsAvgTmp = ds.filter(d => {d.temp > 25}).map(d => (d.temp, d.humidity, d.cca3)).groupBy($"_3").avg()
//display the resulting dataset
display(dsAvgTmp)
(点击放大图像)
4、性能与优化
除了上述优点之外,你还要看到使用 DataFrame 和 Dataset API 带来的空间效率和性能提升。原因有如下两点:
首先,因为 DataFrame 和 Dataset API 都是基于 Spark SQL 引擎构建的,它使用 Catalyst 来生成优化后的逻辑和物理查询计划。所有 R、Java、Scala 或 Python 的 DataFrame/Dataset API,所有的关系型查询的底层使用的都是相同的代码优化器,因而会获得空间和速度上的效率。尽管有类型的 Dataset[T] API 是对数据处理任务优化过的,无类型的 Dataset[Row](别名 DataFrame)却运行得更快,适合交互式分析。
(点击放大图像)

其次, Spark 作为一个编译器,它可以理解 Dataset 类型的 JVM 对象,它会使用编码器来把特定类型的JVM 对象映射成Tungsten 的内部内存表示。结果,Tungsten 的编码器就可以非常高效地将JVM 对象序列化或反序列化,同时生成压缩字节码,这样执行效率就非常高了。
该什么时候使用 DataFrame 或 Dataset 呢?
如果你需要丰富的语义、高级抽象和特定领域专用的 API,那就使用 DataFrame 或 Dataset;
如果你的处理需要对半结构化数据进行高级处理,如 filter、map、aggregation、average、sum、SQL 查询、列式访问或使用 lambda 函数,那就使用 DataFrame 或 Dataset;
如果你想在编译时就有高度的类型安全,想要有类型的 JVM 对象,用上 Catalyst 优化,并得益于 Tungsten 生成的高效代码,那就使用 Dataset;
如果你想在不同的 Spark 库之间使用一致和简化的 API,那就使用 DataFrame 或 Dataset;
如果你是 R 语言使用者,就用 DataFrame;
如果你是 Python 语言使用者,就用 DataFrame,在需要更细致的控制时就退回去使用 RDD;
注意只需要简单地调用一下.rdd,就可以无缝地将 DataFrame 或 Dataset 转换成 RDD。例子如下:
// select specific fields from the Dataset, apply a predicate
// using the where() method, convert to an RDD, and show first 10
// RDD rows
val deviceEventsDS = ds.select($"device_name", $"cca3", $"c02_level").where($"c02_level" > 1300)
// convert to RDDs and take the first 10 rows
val eventsRDD = deviceEventsDS.rdd.take(10)
(点击放大图像)

总结
总之,在什么时候该选用 RDD、DataFrame 或 Dataset 看起来好像挺明显。前者可以提供底层的功能和控制,后者支持定制的视图和结构,可以提供高级和特定领域的操作,节约空间并快速运行。
当我们回顾从早期版本的 Spark 中获得的经验教训时,我们问自己该如何为开发者简化 Spark 呢?该如何优化它,让它性能更高呢?我们决定把底层的 RDD API 进行高级抽象,成为 DataFrame 和 Dataset,用它们在 Catalyst 优化器和 Tungsten 之上构建跨库的一致数据抽象。
DataFrame 和 Dataset,或 RDD API,按你的实际需要和场景选一个来用吧,当你像大多数开发者一样对数据进行结构化或半结构化的处理时,我不会有丝毫惊讶。
作者介绍
Jules S. Damji 是 Databricks 在 Apache Spark 社区的布道者。他也是位一线的开发者,在业界领先的公司里有超过 15 年的大型分布式系统开发经验。在加入 Databricks 之前,他在 Hortonworks 公司做 Developer Advocate。
译文链接:https://www.infoq.cn/article/three-apache-spark-apis-rdds-dataframes-and-datasets/
且谈 Apache Spark 的 API 三剑客:RDD、DataFrame 和 Dataset的更多相关文章
- RDD, DataFrame or Dataset
总结: 1.RDD是一个Java对象的集合.RDD的优点是更面向对象,代码更容易理解.但在需要在集群中传输数据时需要为每个对象保留数据及结构信息,这会导致数据的冗余,同时这会导致大量的GC. 2.Da ...
- APACHE SPARK 2.0 API IMPROVEMENTS: RDD, DATAFRAME, DATASET AND SQL
What’s New, What’s Changed and How to get Started. Are you ready for Apache Spark 2.0? If you are ju ...
- 浅谈Apache Spark的6个发光点(CSDN)
Spark是一个基于内存计算的开源集群计算系统,目的是更快速的进行数据分析.Spark由加州伯克利大学AMP实验室Matei为主的小团队使用Scala开发开发,其核心部分的代码只有63个Scala文件 ...
- A Tale of Three Apache Spark APIs: RDDs, DataFrames, and Datasets(中英双语)
文章标题 A Tale of Three Apache Spark APIs: RDDs, DataFrames, and Datasets 且谈Apache Spark的API三剑客:RDD.Dat ...
- Spark学习之路(八)—— Spark SQL 之 DataFrame和Dataset
一.Spark SQL简介 Spark SQL是Spark中的一个子模块,主要用于操作结构化数据.它具有以下特点: 能够将SQL查询与Spark程序无缝混合,允许您使用SQL或DataFrame AP ...
- Spark 系列(八)—— Spark SQL 之 DataFrame 和 Dataset
一.Spark SQL简介 Spark SQL 是 Spark 中的一个子模块,主要用于操作结构化数据.它具有以下特点: 能够将 SQL 查询与 Spark 程序无缝混合,允许您使用 SQL 或 Da ...
- Apache Spark 2.0三种API的传说:RDD、DataFrame和Dataset
Apache Spark吸引广大社区开发者的一个重要原因是:Apache Spark提供极其简单.易用的APIs,支持跨多种语言(比如:Scala.Java.Python和R)来操作大数据. 本文主要 ...
- There Are Now 3 Apache Spark APIs. Here’s How to Choose the Right One
See Apache Spark 2.0 API Improvements: RDD, DataFrame, DataSet and SQL here. Apache Spark is evolvin ...
- Spark RDD、DataFrame和DataSet的区别
版权声明:本文为博主原创文章,未经博主允许不得转载. 目录(?)[+] 转载请标明出处:小帆的帆的专栏 RDD 优点: 编译时类型安全 编译时就能检查出类型错误 面向对象的编程风格 直接通过类 ...
随机推荐
- vnc安装 VNC的安装以及使用[转]
VNC (Virtual Network Console)是虚拟网络控制台的缩写.它 是一款优秀的远程控制工具软件,由著名的 AT&T 的欧洲研究实验室开发的.VNC 是在基于 UNIX 和 ...
- Beta冲刺 —— 5.30
这个作业属于哪个课程 软件工程 这个作业要求在哪里 Beta冲刺 这个作业的目标 Beta冲刺 作业正文 正文 github链接 项目地址 其他参考文献 无 一.会议内容 1.讨论并解决每个人存在的问 ...
- Rocket - tilelink - RegionReplicator
https://mp.weixin.qq.com/s/XZVCdt50tM6lavchGm9GRg 简单介绍RegionReplicator的实现. 1. 基本介绍 根据mask ...
- 蒲公英 · JELLY技术周刊 Vol.09 StackOverflow - 2020 开发者年度报告
登高远眺 沧海拾遗,积跬步以至千里 基础技术 StackOverFlow 2020 年开发者报告 技术问答社区 StackOverFlow 的年度报告,本次报告统计了来自于全球各地共 65000 名开 ...
- 高性能可扩展mysql 笔记(二)用户模型设计、用户实体表结构设计、设计范式
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 一.用户模型设计 电商羡慕中用户模型的设计涉及以下几个部分: 以电商平台京东的登录.注册页面作为例: ...
- Java实现 蓝桥杯VIP 算法训练 矩阵加法
时间限制:1.0s 内存限制:512.0MB 问题描述 给定两个N×M的矩阵,计算其和.其中: N和M大于等于1且小于等于100,矩阵元素的绝对值不超过1000. 输入格式 输入数据的第一行包含两个整 ...
- Java实现 LeetCode 232 用栈实现队列
232. 用栈实现队列 使用栈实现队列的下列操作: push(x) – 将一个元素放入队列的尾部. pop() – 从队列首部移除元素. peek() – 返回队列首部的元素. empty() – 返 ...
- Java实现 洛谷 P1909 买铅笔
import java.util.Arrays; import java.util.Scanner; public class Main { public static void main(Strin ...
- 类似-Xms、-Xmn这些参数的含义:
类似-Xms.-Xmn这些参数的含义: 答: 堆内存分配: JVM初始分配的内存由-Xms指定,默认是物理内存的1/64 JVM最大分配的内存由-Xmx指定,默认是物理内存的1/4 默认空余堆内存小于 ...
- 带你学够浪:Go语言基础系列 - 8分钟学控制流语句
★ 文章每周持续更新,原创不易,「三连」让更多人看到是对我最大的肯定.可以微信搜索公众号「 后端技术学堂 」第一时间阅读(一般比博客早更新一到两篇) " 对于一般的语言使用者来说 ,20% ...