关于 word2vec 如何工作的问题
2019-09-07 22:36:21
问题描述:word2vec是如何工作的?
问题求解:
谷歌在2013年提出的word2vec是目前最常用的词嵌入模型之一。word2vec实际是一种浅层的神经网络模型,它有两种网络结构,分别是cbow和skip gram。
cbow的目标是根据上下文来预测中心词的出现概率,skip-gram则是通过中心词来预测上下文中的单词的出现概率。

对于cbow而言,输入是上下文的one hot表示,它们共同过一个word embedding层/hidding layer层,可以得到上下文的w2v的加和,之后再过一个hidding layer + softmax layer就可以得到各个单词的出现概率,将之和truth进行交叉熵运算就可以得到它们之间的相似性,最后进行梯度回溯即可。
对于skip-gram来说,输入是中心词的one hot表示,它过一个word embedding层后得到其w2v,之后再过一个hidding layer + softmax layer就可以得到各个单词的出现概率,将之和truth进行交叉熵运算就可以得到它们之间的相似性,最后进行梯度回溯即可。
简单比较cbow 和 skip-gram,它们本质上都是语言模型,区别有两点,一个是cbow输入的是上下文的单词,输出的是中心词;skip-gram输入的是中心词,输出的是上下文的单词;第二个显著的不同是cbow的输入是批量输入的,也就是上下文的单词是整体进行输入的,但是skip-gram则是单词对进行输入,也就是一个中心词可以对应多个上下文单词,并且这多个pair是不同的训练集。
word2vec的优化策略:
- Subsampling Frequent Words 高频词汇下采样
对于高频词汇,诸如the,a等词汇,它会经常出现在各种pair对中:
1)<cat, the> 这个pair对事实上并不能提供很多的关于cat的有效信息;
2)<the, apple> 关于高频词的pair对的数目会远远多于我们实际需要的数目,这个地方产生了冗余;
为了解决这个问题,就提出了高频词汇下采样的策略。
高频词汇下采样的具体做法:对于一个window中的词汇我们以词频的概率对其中的单词进行舍弃,一旦我们舍弃了这个单词,那么这个单词就不会出现在以别的中心词为代表的上下文中(注意,自己作为中心词的时候依然会组pair)。
If we have a window size of 10, and we remove a specific instance of “the” from our text:
As we train on the remaining words, “the” will not appear in any of their context windows.
We’ll have 10 fewer training samples where “the” is the input word.
Trick:在编程实现高频词汇下采样的时候呢,还有一个trick,这里不是直接使用的词频,而是对词频进行了一定的修改,以如下的概率对某个单词进行保留,可以通过函数图像看出这个函数在词频很高的时候保留概率较低,在词频很低的时候保留概率较高。
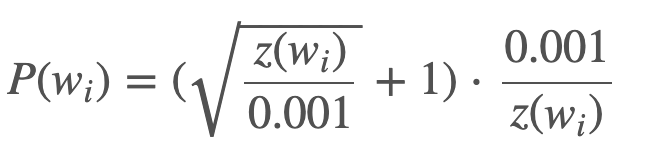
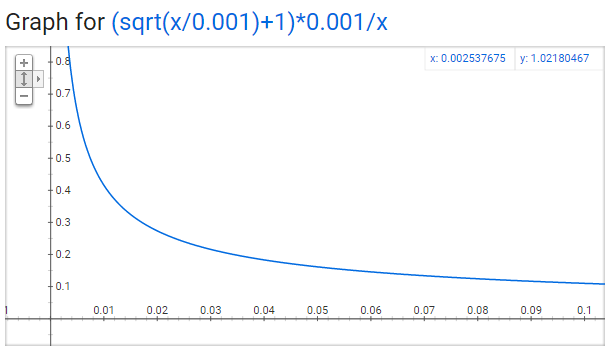
这个函数中的0.001是一个参数,名叫sample,有了这个参数我们就可以手动的去设置保留的sample的数量,如果数值取的小的话,那么实际得到的sample的数目就会少。
There is also a parameter in the code named ‘sample’ which controls how much subsampling occurs, and the default value is 0.001. Smaller values of ‘sample’ mean words are less likely to be kept.
- Negative Sampling 负采样
负采样主要解决的问题就是参数量过大,模型很难训练的。我们知道最后的输出是各个单词的概率,那么最后一个hidding layer的参数量就是 vec_size * vocab_size,而vocab_size是有可能达到10w的,如果vec_size = 400的话,那么最后的这个matrix的参数量就是4kw,这个是一个非常庞大的参数量,如何减小对这么巨大的参数量的运算呢?可以使用负采样的机制进行有效的参数控制。
采样负采样其实是真正以pair对的形式来看数据,如果说之间是一个多分类的话,那么采用负采样后就是一个二分类的问题。
<a, b1> 1
<a, b2> 1
<a, b3> 1
<a, c1> 0
<a, c2> 0
每次只对pair对进行判断,如果是正例,那么输出为1, 如果是负例,那么输出是0。采用这种方式之后,每次的参数迭代量其实就是两个w2v的大小,这样就可以大大减少参数的更新数目,起到加速模型训练的效果。
一般来说我们是进行随机采样的,采样的数目多少论文中提到如果是小的数据集,那么一般负采样的数目是5 - 20个,如果是大数据集,那么负采样的数据数目是2 - 5。这个我理解是因为如果是大数据集,那么正采样的数据量已经足够将模型学习的非常好了,所以对于负采样的要求没有那么的高。
Trick:一般来说在随机进行负采样的时候概率是以词频的概率进行抽取的,但是在实际的实现中,加上了一个幂次,实际的挑选概率的计算如下,使用这种方式进行选择可以打压高频被反复挑选到的次数,提高低频词汇被挑选到的次数。
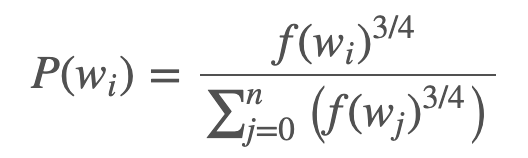
- Hierarchical Softmax 层次softmax
对于训练的参数过多的问题,使用负采样的思路是解决问题的一条途径,还有一条道路是使用层次softmax的技巧来对需要训练的参数的数目进行降低。
所谓层次softmax实际上是在构建一个哈夫曼树,这里的哈夫曼树具体来说就是对于词频较高的词汇,它的树的深度就较浅,对于词频较低的单词的它的树深度就较大,实际的样子如下图所示。
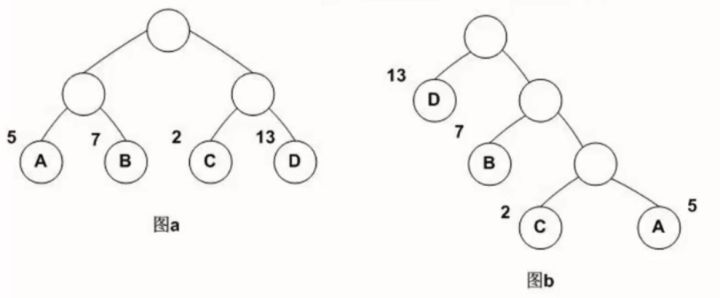
在实际训练的过程中,这里的每个节点就是一个神经元,实际上将也是将之前的多分类转成了多个二分类降低了算法回溯的时候需要更新的神经元的数目。
关于 word2vec 如何工作的问题的更多相关文章
- word2vec——高效word特征提取
继上次分享了经典统计语言模型,最近公众号中有很多做NLP朋友问到了关于word2vec的相关内容, 本文就在这里整理一下做以分享. 本文分为 概括word2vec 相关工作 模型结构 Count-ba ...
- (转)深度学习word2vec笔记之基础篇
深度学习word2vec笔记之基础篇 声明: 1)该博文是多位博主以及多位文档资料的主人所无私奉献的论文资料整理的.具体引用的资料请看参考文献.具体的版本声明也参考原文献 2)本文仅供学术交流,非商用 ...
- 重磅︱文本挖掘深度学习之word2vec的R语言实现
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:2013年末,Google发布的 w ...
- 深度学习word2vec笔记之基础篇
作者为falao_beiliu. 作者:杨超链接:http://www.zhihu.com/question/21661274/answer/19331979来源:知乎著作权归作者所有.商业转载请联系 ...
- word2vec词向量训练及中文文本类似度计算
本文是讲述怎样使用word2vec的基础教程.文章比較基础,希望对你有所帮助! 官网C语言下载地址:http://word2vec.googlecode.com/svn/trunk/ 官网Python ...
- 深度学习-语言处理特征提取 Word2Vec笔记
Word2Vec的主要目的适用于词的特征提取,然后我们就可以用LSTM等神经网络对这些特征进行训练. 由于机器学习无法直接对文本信息进行有效的处理,机器学习只对数字,向量,多维数组敏感,所以在进行文本 ...
- 利用 TensorFlow 入门 Word2Vec
利用 TensorFlow 入门 Word2Vec 原创 2017-10-14 chen_h coderpai 博客地址:http://www.jianshu.com/p/4e16ae0aad25 或 ...
- 从锅炉工到AI专家(10)
RNN循环神经网络(Recurrent Neural Network) 如同word2vec中提到的,很多数据的原型,前后之间是存在关联性的.关联性的打破必然造成关键指征的丢失,从而在后续的训练和预测 ...
- word2vec是如何工作的?
如何有效的将文本向量化是自然语言处理(Natural Language Processing: NLP)领域非常重要的一个研究方向.传统的文本向量化可以用独热编码(one-hot encoding). ...
随机推荐
- hexo创建新文章的正确方法
起因 之前我一直是通过复制以前的文章的形式来创建一个新的文档,但是这一次似乎遇到了一些问题.我将文章写完之后,准备进行预览,输入hexo s命令.在预览页面却没有显示出新的文章,还是和之前的页面是一样 ...
- iOS 客户端与服务端做时间同步
需求 我们做客户端的时候,有时会需要对客户端与服务器的时间进行同步,比如抢购活动.倒计时等.这时我们要考虑如何准备地与服务器的时间进行同步,同时防止用户本地的时间有误差时导致的问题. 分析 描述 为了 ...
- Mac 常见命令行
1. unrar解压rar文件 1.1 安装命令:brew install unrar 1.2 解压文件:unrar x test.rar 2. 创建文件夹:mkdir 文件夹名 3. 删除文件夹: ...
- 奉上简单的.Net后端开发模板
假定一个场景,开始做开发的你,领导走到你的面前说道:"小伙子,看了简历和最近的工作表现,很不错,现在交给一个任务,开发一个简单的CMS后端接口吧,前端有人配合你",当时你内心读白: ...
- 前端开发--vue开发部分报错指南
前期开发过程中 [Vue warn]: Error in render: "TypeError: Cannot read property '0' of undefined". 解 ...
- 【一统江湖的大前端(8)】matter.js 经典物理
目录 [一统江湖的大前端(8)]matter.js 经典物理 一.经典力学回顾 二. 仿真的实现原理 2.1 基本动力学模拟 2.2 碰撞模拟 三. 物理引擎matter.js 3.1 <愤怒的 ...
- 必备技能二、es6
一.ES6模块 ES6 引入了模块化,其设计思想是在编译时就能确定模块的依赖关系,以及输入和输出的变量. ES6 的模块化分为导出(export) @与导入(import)两个模块. 特点 ES6 的 ...
- PHP中elseif与else if的区别
在PHP中,正常情况下elseif和else if的用法及效果是一样的,但在使用带冒号的if语句时(也就是php替代)情况会有点不一样,比如: <?php /*正确的写法*/ $a = 1; ...
- lesson01
题目: Action3: 统计全班的成绩 班里有5名同学,现在需要你用numpy来统计下这些人在语文.英语.数学中的平均成绩.最小成绩.最大成绩.方差.标准差.然后把这些人的总成绩排序,得出名次进行 ...
- 【python】提取sql语句中的表名
前言 最近刚学python,写一个小工具时需要提取sql语句中表名,查询一番后找到一篇文章挺不错的,mark一下 PS.那篇文章是转载的,且没有标注转载自哪里 正文 import ply.lex as ...