python实现PCA算法原理
PCA主成分分析法的数据主成分分析过程及python原理实现
1、对于主成分分析法,在求得第一主成分之后,如果需要求取下一个主成分,则需要将原来数据把第一主成分去掉以后再求取新的数据X’的第一主成分,即为原来数据X的第二主成分,循环往复即可。
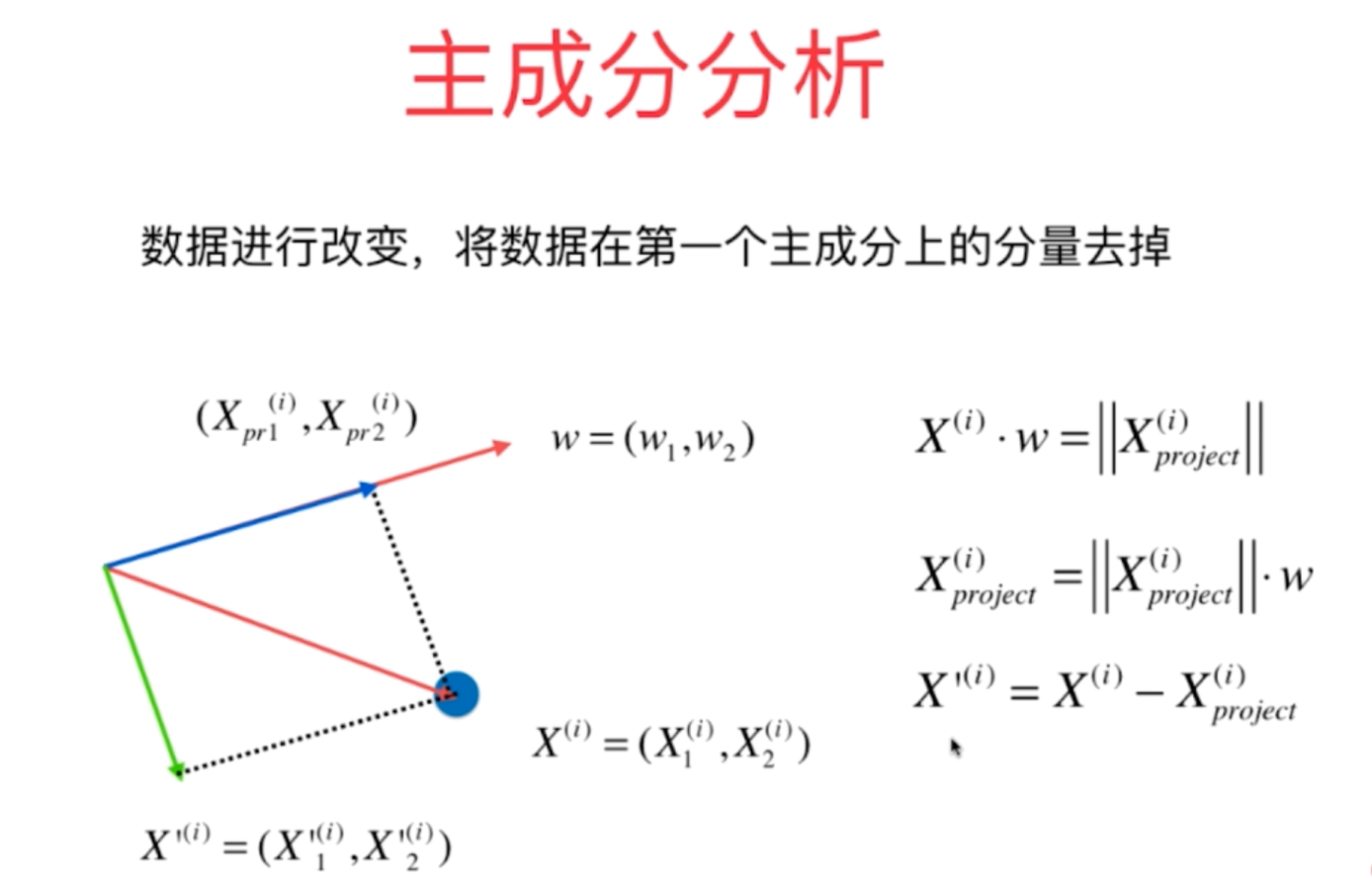
2、利用PCA算法的原理进行数据的降维,其计算过程的数学原理如下所示,其降维的过程会丢失一定的信息,因此采用恢复过程恢复原来的高维数据后,它会恢复为原来数据在新的主成分上的映射点,而不再是原来的坐标点。
(1)高维数据的降维(从n维降到k维数据)

(2)从降维得到k维数据恢复到原来的n维数据集
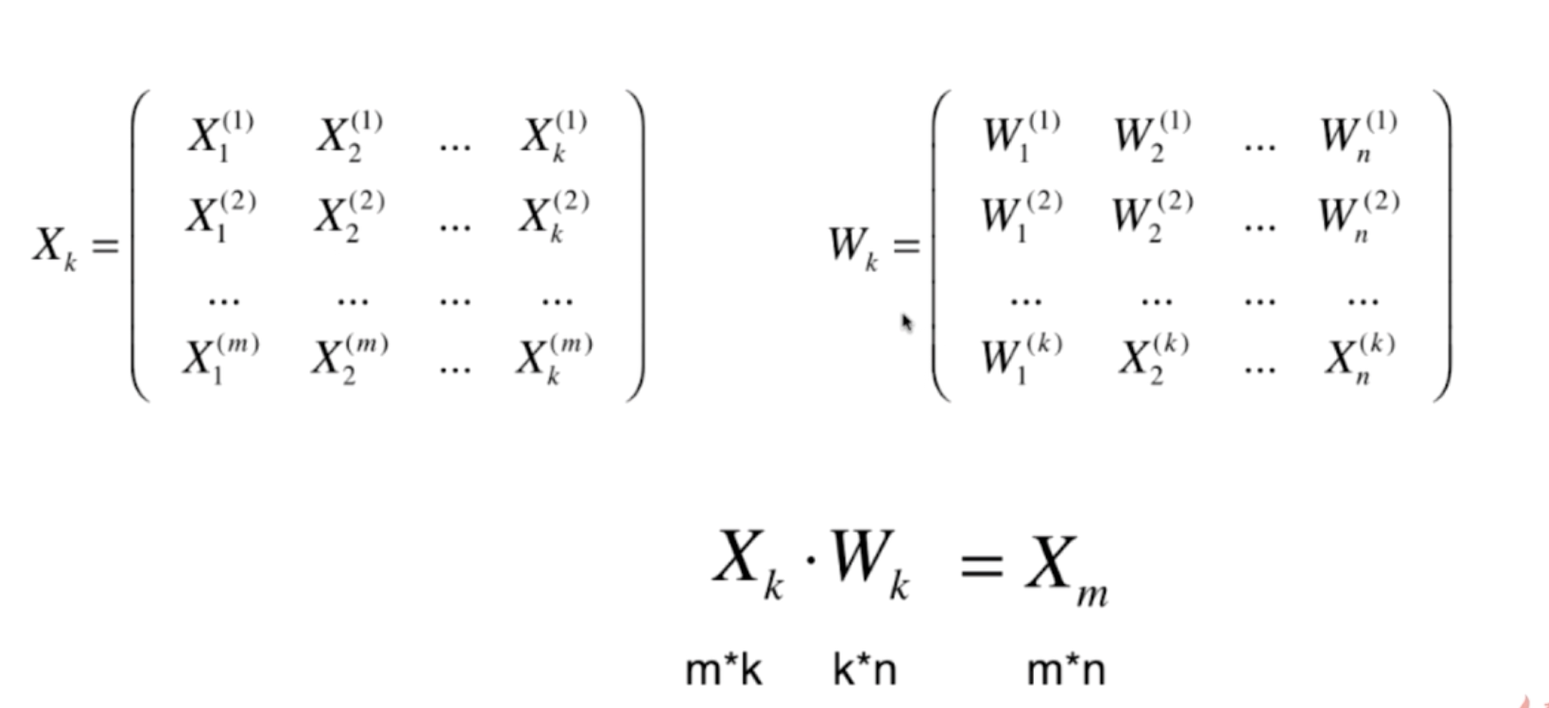
3、具体的数据降维实现原理代码如下所示:
import numpy as np
import matplotlib.pyplot as plt
x=np.empty((100,2))
x[:,0]=np.random.uniform(0.0,100.0,size=100)
x[:,1]=0.75*x[:,0]+3.0*np.random.normal(0,3,size=100)
plt.figure()
plt.scatter(x[:,0],x[:,1])
plt.show() #demean操作函数定义
def demean(x):
return x-np.mean(x,axis=0)
print(x)
print(np.mean(x,axis=0))
print(demean(x))
print(np.mean(demean(x),axis=0))
x_demean=demean(x) #梯度上升法的函数定义
def f(w,x):
return np.sum((x.dot(w))**2)/len(x)
def df_math(w,x):
return x.T.dot(x.dot(w))*2/len(x)
def df_debug(w,x,epsilon=0.00001):
res=np.empty(len(x))
for i in range(len(x)):
w1=w.copy()
w1[i]=w1[i]+epsilon
w2= w.copy()
w2[i] =w2[i]-epsilon
res[i]=(f(w1,x)-f(w2,x))/(2*epsilon)
return res
def derection(w):
return w/np.linalg.norm(w)
def gradient_ascent1(x,eta,w_initial,erro=1e-8, n=1e6):
w=w_initial
w=derection(w)
i=0
while i<n:
gradient =df_math(w,x)
last_w = w
w = w + gradient * eta
w = derection(w) #注意1:每次都需要将w规定为单位向量
if (abs(f(w,x) - f(last_w,x))) < erro:
break
i+=1
return w
w0=np.random.random(x.shape[1]) #注意2:不能从0向量开始
print(w0)
eta=0.001 #注意3:不能将数据进行标准化,即不可以使用standardscaler进行数据标准化
w1=gradient_ascent1(x_demean,eta,w0)
print(w1)
q=np.linspace(-40,40)
Q=q*w1[1]/w1[0]
plt.figure(1)
plt.scatter(x[:,0],x[:,1])
plt.plot(q,Q,"r")
print(w1[1]/w1[0]) #求取数据的前n个的主成分,循环往复即可
x2=np.empty(x.shape)
for i in range(len(x)):
x2[i]=x_demean[i]-x_demean[i].dot(w1)*w1
plt.figure()
plt.scatter(x2[:,0],x2[:,1],color="g")
plt.show()
w00=np.random.random(x.shape[1])
print(w00)
w2=gradient_ascent1(x2,eta,w00)
print(w2) #求取n维数据的前n个主成分的封装函数
def first_n_compnent(n,x,eta=0.001,erro=1e-8, m=1e6):
x_pca=x.copy()
x_pca=demean(x_pca)
res=[]
for i in range(n):
w0=np.random.random(x.shape[1])
w=gradient_ascent1(x_pca,eta,w0)
res.append(w)
x_pca=x_pca-x_pca.dot(w).reshape(-1,1)*w
return res
print(first_n_compnent(2,x))
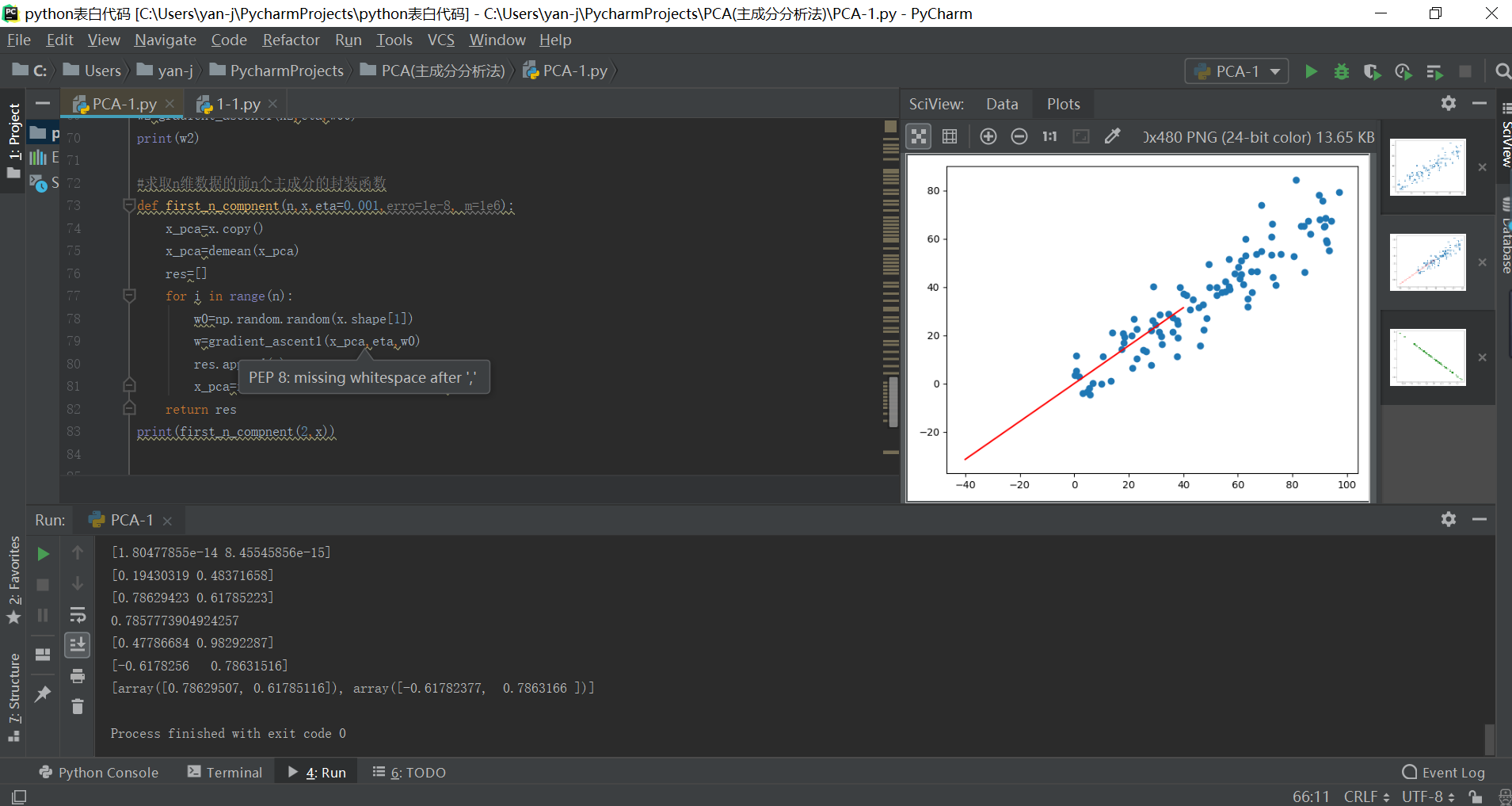
实际的运行效果如下所示:
python实现PCA算法原理的更多相关文章
- 主成分分析 PCA算法原理
对同一个体进行多项观察时,必定涉及多个随机变量X1,X2,…,Xp,它们都是的相关性, 一时难以综合.这时就需要借助主成分分析 (principal component analysis)来概括诸多信 ...
- 深入学习主成分分析(PCA)算法原理(Python实现)
一:引入问题 首先看一个表格,下表是某些学生的语文,数学,物理,化学成绩统计: 首先,假设这些科目成绩不相关,也就是说某一科目考多少分与其他科目没有关系,那么如何判断三个学生的优秀程度呢?首先我们一眼 ...
- 三种方法实现PCA算法(Python)
主成分分析,即Principal Component Analysis(PCA),是多元统计中的重要内容,也广泛应用于机器学习和其它领域.它的主要作用是对高维数据进行降维.PCA把原先的n个特征用数目 ...
- 梯度迭代树(GBDT)算法原理及Spark MLlib调用实例(Scala/Java/python)
梯度迭代树(GBDT)算法原理及Spark MLlib调用实例(Scala/Java/python) http://blog.csdn.net/liulingyuan6/article/details ...
- 手指静脉细化算法过程原理解析 以及python实现细化算法
原文作者:aircraft 原文地址:https://www.cnblogs.com/DOMLX/p/8672489.html 文中的一些图片以及思想很多都是参考https://www.cnblogs ...
- Python使用三种方法实现PCA算法[转]
主成分分析(PCA) vs 多元判别式分析(MDA) PCA和MDA都是线性变换的方法,二者关系密切.在PCA中,我们寻找数据集中最大化方差的成分,在MDA中,我们对类间最大散布的方向更感兴趣. 一句 ...
- Python的主成分分析PCA算法
这篇文章很不错:https://blog.csdn.net/u013082989/article/details/53792010 为什么数据处理之前要进行归一化???(这个一直不明白) 这个也很不错 ...
- 机器学习--主成分分析(PCA)算法的原理及优缺点
一.PCA算法的原理 PCA(principle component analysis),即主成分分析法,是一个非监督的机器学习算法,是一种用于探索高维数据结构的技术,主要用于对数据的降维,通过降维可 ...
- Python实现的选择排序算法原理与用法实例分析
Python实现的选择排序算法原理与用法实例分析 这篇文章主要介绍了Python实现的选择排序算法,简单描述了选择排序的原理,并结合实例形式分析了Python实现与应用选择排序的具体操作技巧,需要的朋 ...
随机推荐
- java怎么调用子类中父类被覆盖的方法
public class b { { void show() { System.out.println("b"); } } public class c extends b { v ...
- FileUpload之FileItem类的常用方法
http://blog.csdn.net/chinaliuyan/article/details/7002014
- 【原】Django数据Model层总结
vlaues - 单条记录 - <class 'dict'> 多条记录 - <class 'django.db.models.query.QuerySet'> vlaues_l ...
- docker运行安装mysql postgres
安装mysql [root@host1 ~]# docker images -a REPOSITORY TAG IMAGE ID CREATED SIZE docker.io/mysql 5.7 4d ...
- Pako.js压缩解压,vue压缩解压,前后端之间高效数据传输
项目开发中常常会遇到前后端之间有大量数据传输占用带宽导致页面响应慢的问题,这时候我们可以考虑使用Pako.js对信息进行压缩之后传输. 我在前端使用的是vue-element-admin前端框架.框架 ...
- jquery 分页 Ajax异步
//使用Ajax异步查询数据 <div class="table-responsive"> <table class="table table-bord ...
- Update(Stage5):Kudu_javaApi使用_Spark整合
Table of Contents: 2.3. 安装 Zookeeper 2.4. 安装 Hadoop 2.4. 安装 MySQL 2.5. 安装 Hive 2.6. 安装 Kudu 2.7. 安装 ...
- Update(Stage4):Spark Streaming原理_运行过程_高级特性
Spark Streaming 导读 介绍 入门 原理 操作 Table of Contents 1. Spark Streaming 介绍 2. Spark Streaming 入门 2. 原理 3 ...
- CSS三列自适应布局(两边宽度固定,中间自适应)
https://blog.csdn.net/cinderella_hou/article/details/52156333 https://blog.csdn.net/wangchengiii/art ...
- Windows 安装python虚拟环境
windows 安装pytho虚拟环境 方法一:virtualenv (1)使用pip安装virtualenv工具 pip install virtualenv (2)使用virtualenv创建虚拟 ...