Python的主成分分析PCA算法
这篇文章很不错:https://blog.csdn.net/u013082989/article/details/53792010
为什么数据处理之前要进行归一化???(这个一直不明白)
这个也很不错:https://blog.csdn.net/u013082989/article/details/53792010#commentsedit
下面是复现一个例子:
# -*- coding: utf-8 -*-
#来源:https://blog.csdn.net/u013082989/article/details/53792010
#来源:https://blog.csdn.net/hustqb/article/details/78394058 (这里有个例子)关于降维之后的坐标系问题,???结合里面的例子
#用库函数实现的过程:
#导入需要的包:
import numpy as np
from matplotlib import pyplot as plt
from scipy import io as spio
from sklearn.decomposition import pca
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
#归一化数据,并作图
def scaler(X):
"""
注:这里的归一化是按照列进行的。也就是把每个特征都标准化,就是去除了单位的影响。
"""
scaler=StandardScaler()
scaler.fit(X)
x_train=scaler.transform(X)
return x_train
#使用pca模型拟合数据并降维n_components对应要降的维度
def jiangwei_pca(x_train,K): #传入的是X的矩阵和主成分的个数K
model=pca.PCA(n_components=K).fit(x_train)
Z=model.transform(x_train) #transform就会执行降维操作
#数据恢复,model.components_会得到降维使用的U矩阵
Ureduce=model.components_
x_rec=np.dot(Z,Ureduce) #数据恢复
return Z,x_rec #这里Z是将为之后的数据,x_rec是恢复之后的数据。
if __name__ == '__main__':
X=np.array([[1,1],[1,3],[2,3],[4,4],[2,4]])
x_train=scaler(X)
print('x_train:',x_train)
Z,x_rec=jiangwei_pca(x_train,2)
print("Z:",Z)
print("x_rec:",x_rec) #如果有时候,这里不能够重新恢复x_train,一个原因可能是主成分太少。
print("x_train:",x_train)
## 这里的主成分为什么不是原来的两个。
## 还有一个问题是,如何用图像表现出来。
## 还有一个问题就是如何得到系数,这个系数是每个特征在主成分中的贡献,要做这个就需要看矩阵,弄明白原理:
或许和这个程序有关:pca.explained_variance_ratio_
摘自:https://blog.csdn.net/qq_36523839/article/details/82558636
这里提一点:pca的方法explained_variance_ratio_计算了每个特征方差贡献率,所有总和为1,explained_variance_为方差值,通过合理使用这两个参数可以画出方差贡献率图或者方差值图,便于观察PCA降维最佳值。
在提醒一点:pca中的参数选项可以对数据做SVD与归一化处理很方便,但是需要先考虑是否需要这样做。
关于pca的一个推导例子:

、、
根据最后的图形显示来看,一共有五个样本点。而从下面的矩阵看,似乎不是这样???
有点纠结。
从对矩阵X的求均值过程可以知道,是对行求均值的。然后每行减掉均值。
(这样的话,也就是说:每一行是一个特征???,就不太明白了。)
应该写成这样比较清楚:(每一列是一个特性)
[
[1,1]
[1,3]
[2,3]
[4,4]
[2,4]
]
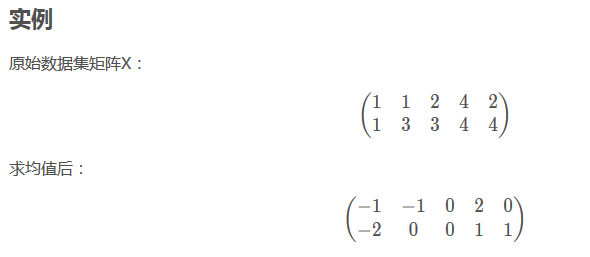
、、
从下面看出这里除的是5,也就是说5是m,也就是行数。???
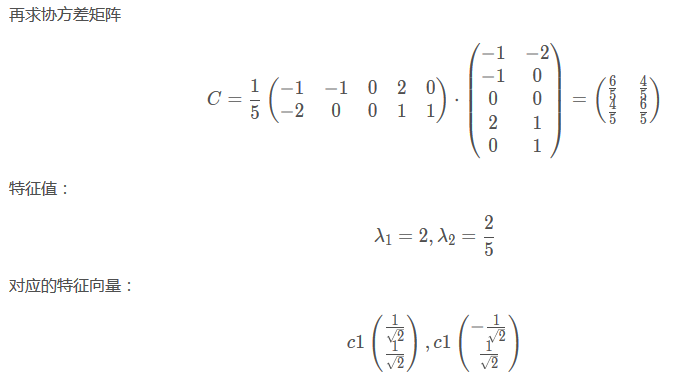
、、
最后降维到一个特征::
下面图片中P的部分,是两个数,也就是两个特征的系数。代表着特征的系数。。。
关键是用的别人的库,但是怎么弄???

、、
上面
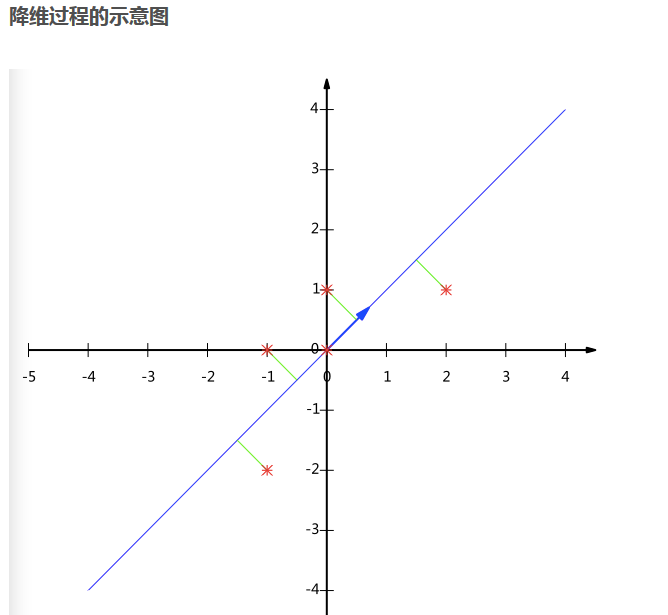
#、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、
下面我们来分析另一个例子:这个例子是官方给出的:
程序如下:
# -*- coding: utf-8 -*-
"""
测试
这里是Python的pca主成分分析的一个测试程序
"""
import numpy as np
from sklearn.decomposition import PCA
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
pca = PCA(n_components='mle') #这里是让机器决定主成分的个数,我们也可以自行设置。
pca = PCA(n_components=2) #这里设置主成分为,这里不能设置成3,因为这里的特征本身只有两个。
pca.fit(X)
print("这里是X:")
print(X)
Z=pca.transform(X) #transform就会执行降维操作
print('这里是Z:')
print(Z)
# Z = np.dot(X, self.components_.T)
# PCA(copy=True, n_components=2, whiten=False)
print(pca.explained_variance_ratio_)
然后运行程序输出的结果:
这里是X:
[[-1 -1]
[-2 -1]
[-3 -2]
[ 1 1]
[ 2 1]
[ 3 2]]
可能是系数的东西: 这里有可能是没个主成分中包含各个特征的权重系数。
你有没有感觉到这个矩阵有一定的特性,有点对角线对称的样子。
[[-0.83849224 0.54491354]
[-0.54491354 -0.83849224]]
这里是Z: 这里的Z实际上主成分的意思。主成分也就是综合特征
[[ 1.38340578 0.2935787 ]
[ 2.22189802 -0.25133484]
[ 3.6053038 0.04224385]
[-1.38340578 -0.2935787 ]
[-2.22189802 0.25133484]
[-3.6053038 -0.04224385]]
[0.99244289 0.00755711]
要捋清一个问题,我们想要得到的是什么?
我们想要得到的是每个主成分前面包含特征的系数。
主成分1=权重11*特征1+权重12*特征2+权重13*特征3···
主成分2=权重21*特征1+权重22*特征2+权重23*特征3···
[[-0.83849224 0.54491354]
[-0.54491354 -0.83849224]]
主成分1=(-0.83849224) *特征1+(-0.54491354)*特征2···
主成分2=(0.54491354) *特征1+(-0.83849224)*特征2···
就是上面这种系数,
我还是有一点疑问?为什么?这个系数矩阵是对称的,这样有点不是很科学??
Python的主成分分析PCA算法的更多相关文章
- 机器学习--主成分分析(PCA)算法的原理及优缺点
一.PCA算法的原理 PCA(principle component analysis),即主成分分析法,是一个非监督的机器学习算法,是一种用于探索高维数据结构的技术,主要用于对数据的降维,通过降维可 ...
- 主成分分析 PCA算法原理
对同一个体进行多项观察时,必定涉及多个随机变量X1,X2,…,Xp,它们都是的相关性, 一时难以综合.这时就需要借助主成分分析 (principal component analysis)来概括诸多信 ...
- 三种方法实现PCA算法(Python)
主成分分析,即Principal Component Analysis(PCA),是多元统计中的重要内容,也广泛应用于机器学习和其它领域.它的主要作用是对高维数据进行降维.PCA把原先的n个特征用数目 ...
- Python使用三种方法实现PCA算法[转]
主成分分析(PCA) vs 多元判别式分析(MDA) PCA和MDA都是线性变换的方法,二者关系密切.在PCA中,我们寻找数据集中最大化方差的成分,在MDA中,我们对类间最大散布的方向更感兴趣. 一句 ...
- python实现PCA算法原理
PCA主成分分析法的数据主成分分析过程及python原理实现 1.对于主成分分析法,在求得第一主成分之后,如果需要求取下一个主成分,则需要将原来数据把第一主成分去掉以后再求取新的数据X’的第一主成分, ...
- 一步步教你轻松学主成分分析PCA降维算法
一步步教你轻松学主成分分析PCA降维算法 (白宁超 2018年10月22日10:14:18) 摘要:主成分分析(英语:Principal components analysis,PCA)是一种分析.简 ...
- 主成分分析PCA数据降维原理及python应用(葡萄酒案例分析)
目录 主成分分析(PCA)——以葡萄酒数据集分类为例 1.认识PCA (1)简介 (2)方法步骤 2.提取主成分 3.主成分方差可视化 4.特征变换 5.数据分类结果 6.完整代码 总结: 1.认识P ...
- 主成分分析 —PCA
一.定义 主成分分析(principal components analysis)是一种无监督的降维算法,一般在应用其他算法前使用,广泛应用于数据预处理中.其在保证损失少量信息的前提下,把多个指标转化 ...
- 如何用Python实现常见机器学习算法-1
最近在GitHub上学习了有关python实现常见机器学习算法 目录 一.线性回归 1.代价函数 2.梯度下降算法 3.均值归一化 4.最终运行结果 5.使用scikit-learn库中的线性模型实现 ...
随机推荐
- POJ Euro Efficiency 1252
Euro Efficiency Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 4109 Accepted: 1754 D ...
- 联想 U410 超极本启用加速硬盘方法
安装步骤: 方法一: 使用raid1方法 (此方法未安装过) 方法二: 普通安装后,使用RST加速 1.改BIOS , 为AHCI启动 , 2.安装好系统后,下载RST软件并安装 3.改BIO ...
- 在Ubuntu14.04中安装Py3和切换Py2和Py3环境
前几天小编给大家分享了如何安装Ubuntu14.04系统,感兴趣的小伙伴可以戳这篇文章:手把手教你在VMware虚拟机中安装Ubuntu14.04系统.今天小编给大家分享一下在Ubuntu14.04系 ...
- How Javascript works (Javascript工作原理) (十一) 渲染引擎及性能优化小技巧
个人总结:读完这篇文章需要20分钟,这篇文章主要讲解了浏览器中引擎的渲染机制. DOMtree ----| |----> RenderTree CSSOMtree ----| ...
- Tensorflow 函数学习笔记
A: A:## tf.argmax(A, axis).eval() 输出axis维度上最大的数的索引 axis=0:列,axis=1:行 A:## tf.add(a,b) 创建a+b的计算图 A:# ...
- 紫书 例题 9-9 UVa 10003 (区间dp+递推顺序)
区间dp,可以以一个区间为状态,f[i][j]是第i个切点到第j个切点的木棍的最小费用 那么对于当前这一个区间,枚举切点k, 可以得出f[i][j] = min{dp(i, k) + dp(k, j) ...
- WPF通用框架ZFS《项目结构介绍01》_模块介绍
首页介绍: 下图为项目运行首页图片, 大的结构分为三块: 1.Header首部模块(存放通知组件[全局通知.消息管理 ].扩展模块[皮肤.系统设置.关于作者.退出系统]) 2.Left左侧菜单模块(存 ...
- [ Javascript ] JavaScript中的定时器(Timer) 是怎样工作的!
作为入门者来说.了解JavaScript中timer的工作方式是非常重要的.通常它们的表现行为并非那么地直观,而这是由于它们都处在一个单一线程中.让我们先来看一看三个用来创建以及操作timer的函数. ...
- NYOJ 203 三国志(Dijkstra+贪心)
三国志 时间限制:3000 ms | 内存限制:65535 KB 难度:5 描写叙述 <三国志>是一款非常经典的经营策略类游戏.我们的小白同学是这款游戏的忠实玩家.如今他把游戏简化一下 ...
- Thinkphp5图片上传正常,音频和视频上传失败的原因及解决
Thinkphp5图片上传正常,音频和视频上传失败的原因及解决 一.总结 一句话总结:php中默认限制了上传文件的大小为2M,查找错误的时候百度,且根据错误提示来查找错误. 我的实际问题是: 我的表单 ...