论文学习-系统评估卷积神经网络各项超参数设计的影响-Systematic evaluation of CNN advances on the ImageNet
博客:blog.shinelee.me | 博客园 | CSDN
写在前面
论文状态:Published in CVIU Volume 161 Issue C, August 2017
论文地址:https://arxiv.org/abs/1606.02228
github地址:https://github.com/ducha-aiki/caffenet-benchmark
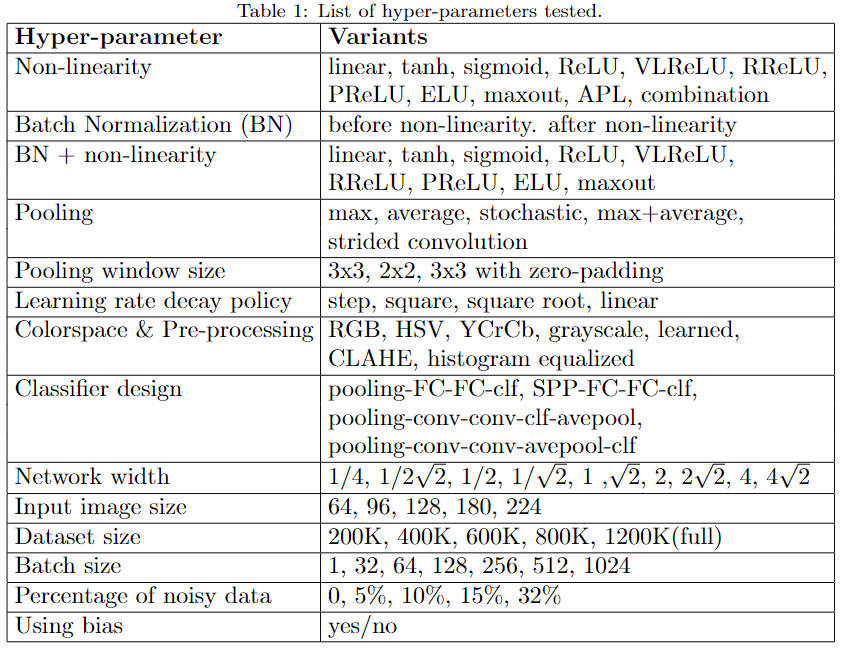
在这篇文章中,作者在ImageNet上做了大量实验,对比卷积神经网络架构中各项超参数选择的影响,对如何优化网络性能很有启发意义,对比实验包括激活函数(sigmoid、ReLU、ELU、maxout等等)、Batch Normalization (BN)、池化方法与窗口大小(max、average、stochastic等)、学习率decay策略(step, square, square root, linear 等)、输入图像颜色空间与预处理、分类器设计、网络宽度、Batch size、数据集大小、数据集质量等等,具体见下图
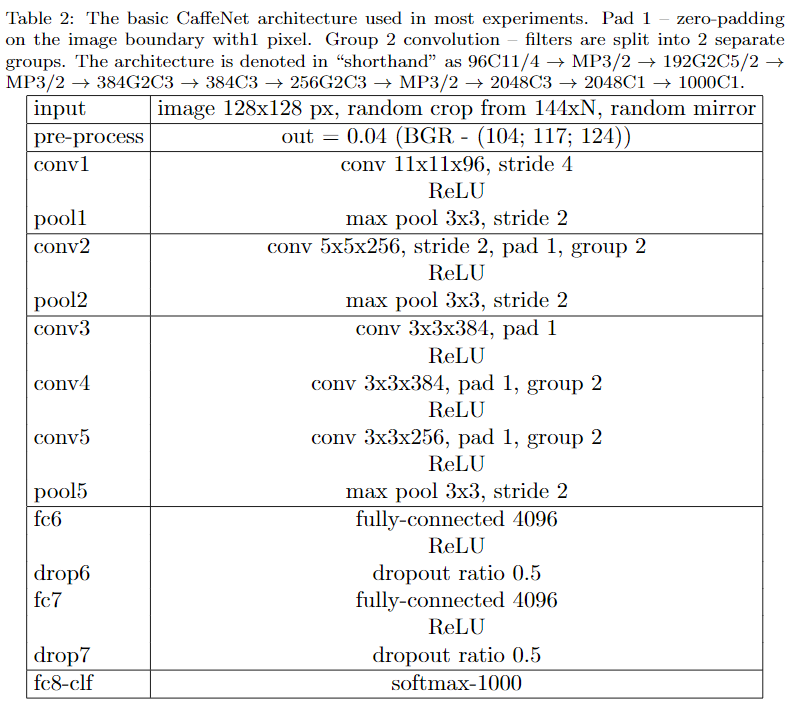
实验所用的基础架构(Baseline)从CaffeNet修改而来,有以下几点不同:
- 输入图像resize为128(出于速度考虑)
- fc6和fc7神经元数量从4096减半为2048
- 网络使用LSUV进行初始化
- 移除了LRN层(对准确率无贡献,出于速度考虑移除)
所有性能比较均以基础架构为Baseline,实验中所有超参数调整也都是在Baseline上进行,Baseline accuracy为47.1%,Baseline网络结构如下
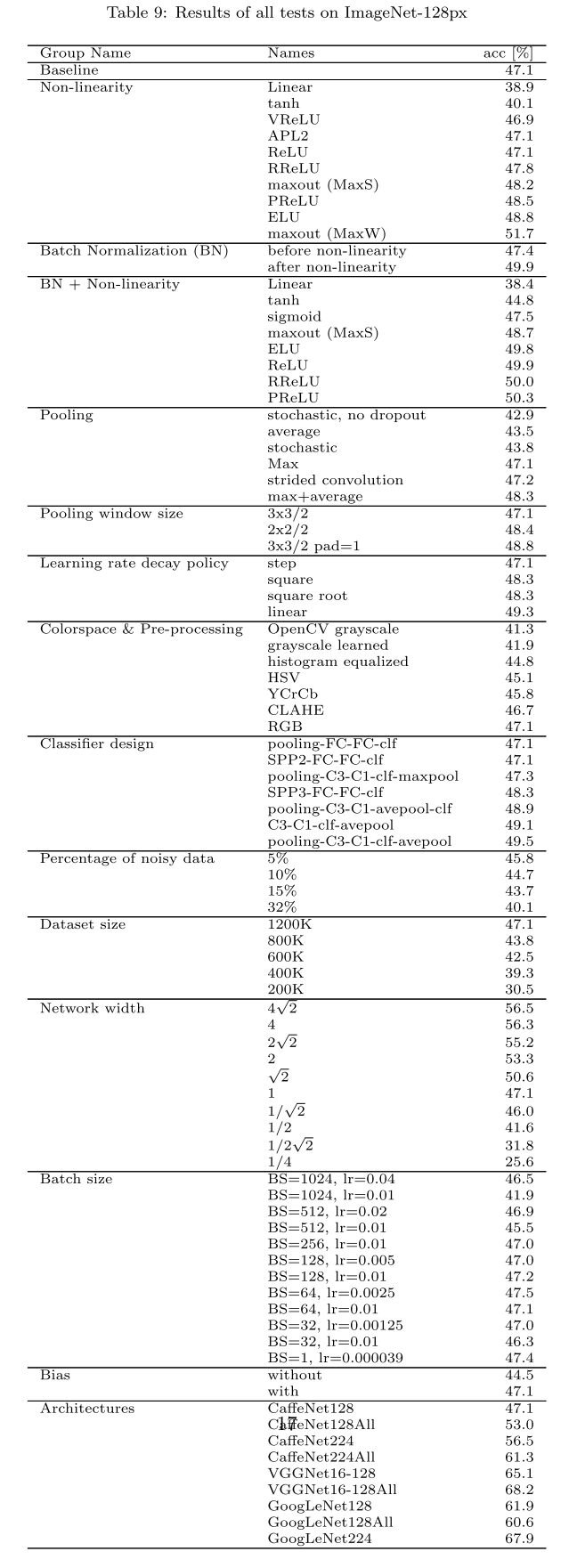
论文实验结论
论文通过控制变量的方式进行实验,最后给出了如下建议:
- 不加 BN时使用 ELU,加BN时使用ReLU(加BN时,两者其实差不多)
- 对输入RGB图学习一个颜色空间变换,再接网络
- 使用linear decay学习策略
- 池化层将average与max求和
- BatchSize使用128或者256,如果GPU内存不够大,在调小BatchSize的同时同比减小学习率
- 用卷积替换全连接层,在最后决策时对输出取平均
- 当决定要扩大训练集前,先查看是否到了“平坦区”——即评估增大数据集能带来多大收益
- 数据清理比增大数据集更重要
- 如果不能提高输入图像的大小,减小隐藏层的stride有近似相同的效果
- 如果网络结构复杂且高度优化过,如GoogLeNet,做修改时要小心——即将上述修改在简单推广到复杂网络时不一定有效
需要注意的是,在Batch Size和学习率中,文章仅做了两个实验,一个是固定学习调整BatchSize,另一个学习率与Batch Size同比增减,但两者在整个训练过程中的Batch Size都保持不变,在这个条件下得出了 学习率与Batch Size同比增减 策略是有效的结论。最近Google有一篇文章《Don't Decay the Learning Rate, Increase the Batch Size》提出了在训练过程中逐步增大Batch Size的策略。
论文实验量非常大,每项实验均通过控制变量测试单一或少数因素变化的影响,相当于通过贪心方式一定意义上获得了每个局部最优的选择,最后将所有局部最优的选择汇总在一起仍极大地改善了性能(但不意味着找到了所有组合中的最优选择)。实验结果主要是在CaffeNet(改)上的得出的,并不见得能推广到所有其他网络。
但是,总的来讲,本篇文章做了很多笔者曾经想过但“没敢”做的实验,实验结果还是很有启发意义的,值得一读。
文章全部实验汇总如下,github上有更多实验结果:
论文细节
一图胜千言,本节主要来自论文图表。
激活函数
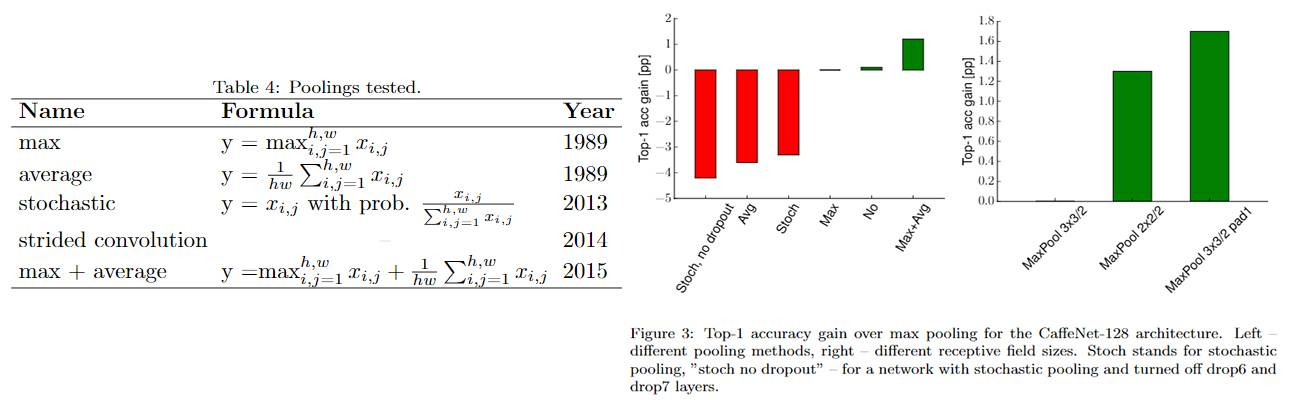
在计算复杂度与ReLU相当的情况下,ELU的单一表现最好,ELU(卷积后)+maxout(全连接后)联合表现最好,前者提升约2个百分点,后者约4个百分点。值得注意的是,不使用非线性激活函数时,性能down了约8个百分点,并非完全不能用。
池化

方法上,max和average池化结合取得最好效果(结合方式为 element-wise 相加),作者推测是因为同时具备了max的选择性和average没有扔掉信息的性质。尺寸上,在保证输出尺寸一样的情况下,non-overlapping优于overlapping——前者的kernel size更大。
学习率

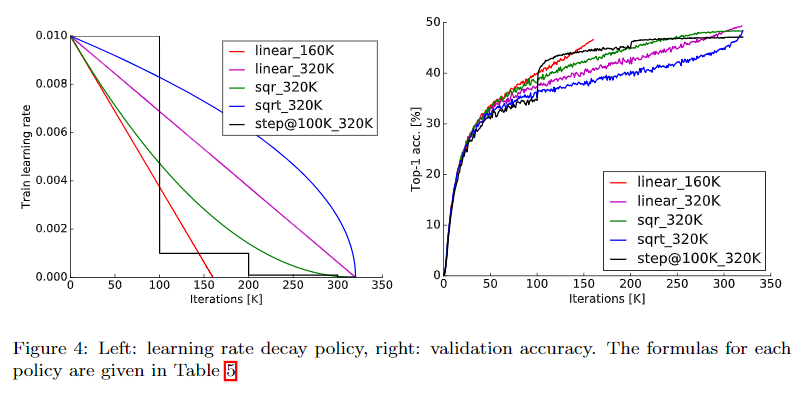
linear decay取得最优效果。
BatchSize与学习率
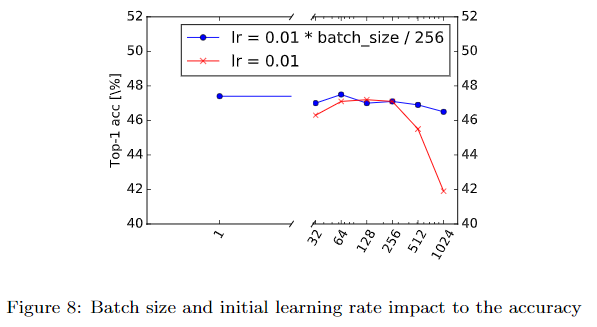
文章中仅实验了固定学习调整BatchSize以及学习率与Batch Size同比增减两个实验,在整个训练过程中Batch Size保持不变,得出了 学习率与Batch Size同比增减 策略是有效的结论。
图像预处理

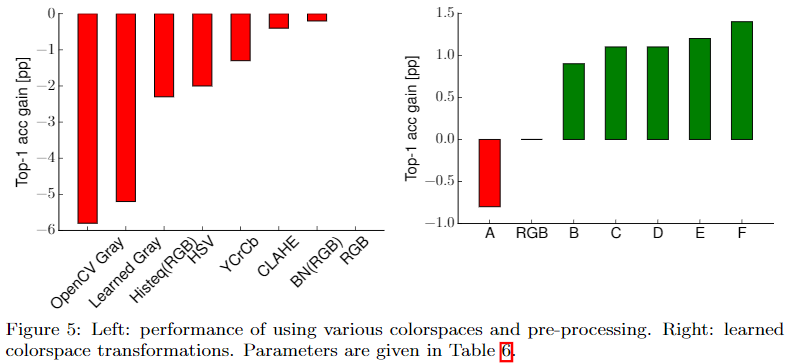
灰度及其他颜色空间均比RGB差,通过两层1x1卷积层将RGB图映射为新的3通道图取得了最好效果。
BN层
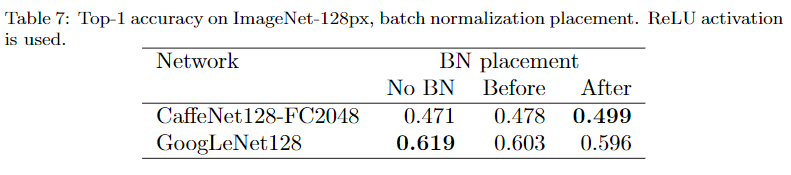
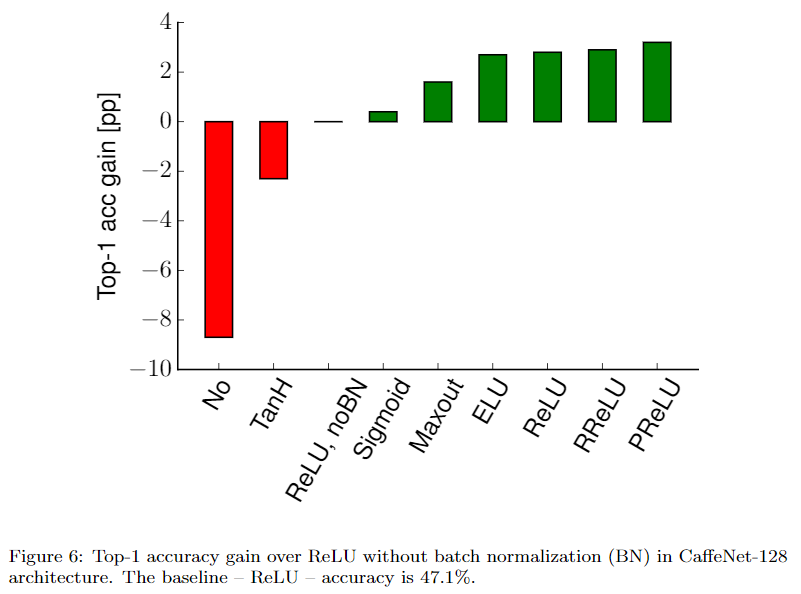
Sigmoid + BN 好于 ReLU无BN,当然,ReLU+BN更好。
分类器设计
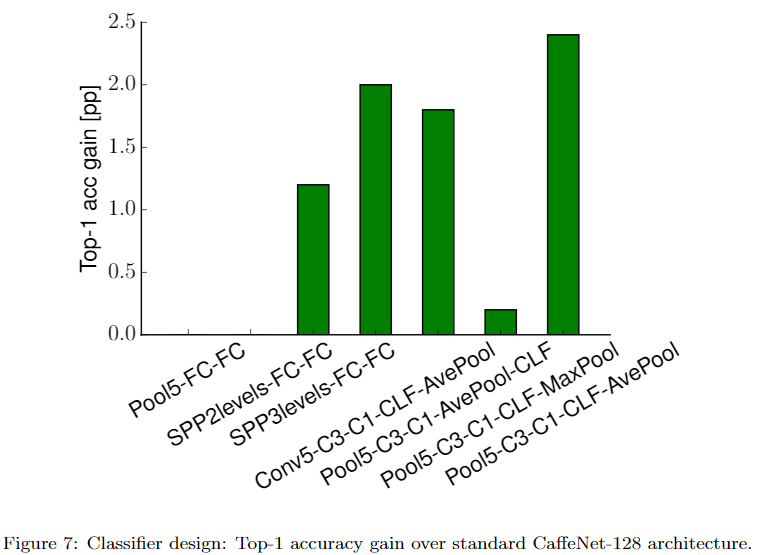
若将CNN网络拆成两个部分,前为特征提取,后为分类器。分类器部分一般有3种设计:
- 特征提取最后一层为max pooling,分类器为一层或两层全连接层,如LeNet、AlexNet、VGGNet
- 使用spacial pooling代替max pooling,分类器为一层或两层全连接层
- 使用average pooling,直接连接softmax,无全连接层,如GoogLeNet、ResNet
作者实验发现,将全连接替换为卷积层(允许zero padding),经过softmax,最后average pooling,即Pool5-C3-C1-CLF-AvePool取得了最好效果。
网络宽度
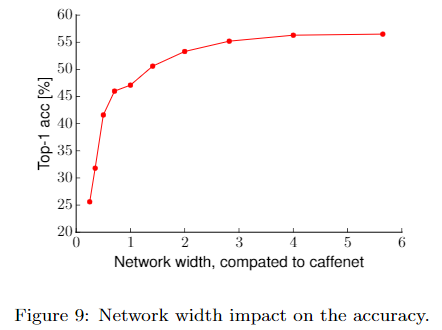
对文章采用的基础网络,增大网络宽度,性能会提升,但增大超过3倍后带来的提升就十分有限了,即对某个特定的任务和网络架构,存在某个适宜的网络宽度。
输入图像大小
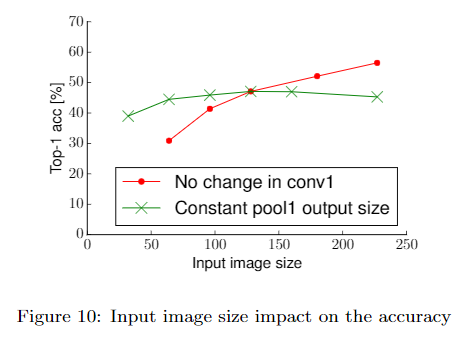
准确率随图像尺寸线性增长,但计算量是平方增长。如果不能提高输入图像的大小,减小隐藏层的stride有近似相同的效果。
Dataset size and noisy labels
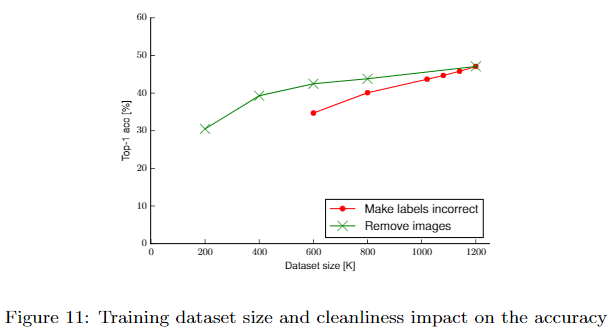
增大数据集可以改善性能,数据清理也可改善性能,但数据清理比数据集大小更重要,为了获得同样的性能,有错误标签的数据集需要更大。
Bias有无的影响

卷积层和全连接层无Bias比有Bias降了2.6个百分点。
改善项汇总
将 学到的颜色空间变换、ELU作为卷积层激活函数、maxout作为全连接层激活函数、linear decay学习率策略、average+max池化 结合使用,在CaffeNet、VGGNet、GoogLeNet上对比实验,如下:
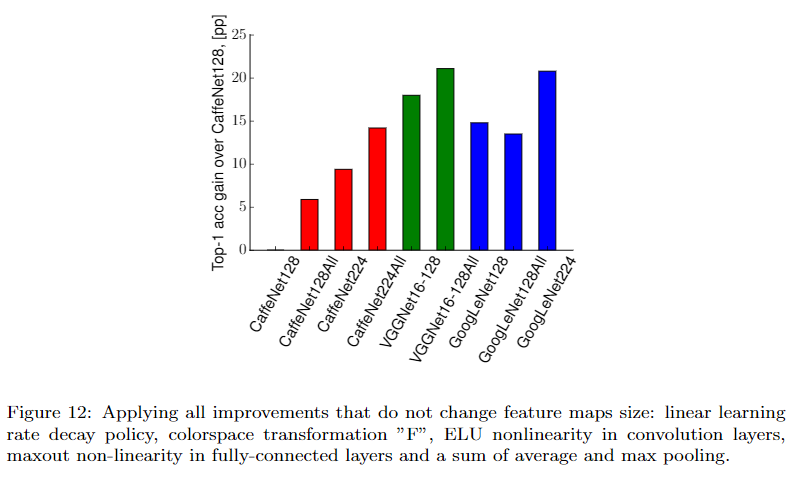
CaffeNet和VGGNet的表现均得以改善,GoogLeNet则不是,对于复杂且高度优化过的网络,一些改进策略不能简单推广。
参考
- paper-Systematic evaluation of CNN advances on the ImageNet
- github-Systematic evaluation of CNN advances on the ImageNet[图片上传失败...(image-eef9ec-1542507708571)]
论文学习-系统评估卷积神经网络各项超参数设计的影响-Systematic evaluation of CNN advances on the ImageNet的更多相关文章
- CNN学习笔记:卷积神经网络
CNN学习笔记:卷积神经网络 卷积神经网络 基本结构 卷积神经网络是一种层次模型,其输入是原始数据,如RGB图像.音频等.卷积神经网络通过卷积(convolution)操作.汇合(pooling)操作 ...
- Coursera Deep Learning笔记 改善深层神经网络:超参数调试 Batch归一化 Softmax
摘抄:https://xienaoban.github.io/posts/2106.html 1. 调试(Tuning) 超参数 取值 #学习速率:\(\alpha\) Momentum:\(\bet ...
- 深度学习项目——基于卷积神经网络(CNN)的人脸在线识别系统
基于卷积神经网络(CNN)的人脸在线识别系统 本设计研究人脸识别技术,基于卷积神经网络构建了一套人脸在线检测识别系统,系统将由以下几个部分构成: 制作人脸数据集.CNN神经网络模型训练.人脸检测.人脸 ...
- DeepLearning.ai学习笔记(二)改善深层神经网络:超参数调试、正则化以及优化--Week2优化算法
1. Mini-batch梯度下降法 介绍 假设我们的数据量非常多,达到了500万以上,那么此时如果按照传统的梯度下降算法,那么训练模型所花费的时间将非常巨大,所以我们对数据做如下处理: 如图所示,我 ...
- 动手学习Pytorch(6)--卷积神经网络基础
卷积神经网络基础 本节我们介绍卷积神经网络的基础概念,主要是卷积层和池化层,并解释填充.步幅.输入通道和输出通道的含义. 二维卷积层 本节介绍的是最常见的二维卷积层,常用于处理图像数据. 二维 ...
- 【学习笔记】卷积神经网络 (CNN )
前言 对于卷积神经网络(cnn)这一章不打算做数学方面深入了解,所以只是大致熟悉了一下原理和流程,了解了一些基本概念,所以只是做出了一些总结性的笔记. 感谢B站的视频 https://www.bili ...
- 学习笔记TF027:卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN),可以解决图像识别.时间序列信息问题.深度学习之前,借助SIFT.HoG等算法提取特征,集合SVM等机器学习算法识别图像 ...
- 【深度学习系列】卷积神经网络CNN原理详解(一)——基本原理
上篇文章我们给出了用paddlepaddle来做手写数字识别的示例,并对网络结构进行到了调整,提高了识别的精度.有的同学表示不是很理解原理,为什么传统的机器学习算法,简单的神经网络(如多层感知机)都可 ...
- Deep Learning.ai学习笔记_第二门课_改善深层神经网络:超参数调试、正则化以及优化
目录 第一周(深度学习的实践层面) 第二周(优化算法) 第三周(超参数调试.Batch正则化和程序框架) 目标: 如何有效运作神经网络,内容涉及超参数调优,如何构建数据,以及如何确保优化算法快速运行, ...
随机推荐
- &&和&、||和|的区别
&& 和 || 为短路与 短路或&&若前面的表达式为false,整个逻辑表达式为false,所以后面的表达式无论true和false都无法影响整个表达式的逻辑结果,所以 ...
- Stackoverflow 最受关注的 10 个 Java 问题
Stack Overflow 是一个大型的编程知识库.在 Stack Overflow 中已经有数以百万计的问题,并且很多答案有着很高的质量.这就是为什么 Stack Overflow 的答案经常位于 ...
- 【BZOJ 2673】[Wf2011]Chips Challenge
题目大意: 传送门 $n*n$的棋盘,有一些位置可以放棋子,有一些已经放了棋子,有一些什么都没有,也不能放,要求放置以后满足:第i行和第i列的棋子数相同,同时每行的棋子数占总数比例小于$\frac{A ...
- 【组合数学】Bzoj2916 [Poi1997]Monochromatic Triangles
Description 空间中有n个点,任意3个点不共线.每两个点用红线或者蓝线连接,如果一个三角形的三边颜色相同,那么称为同色三角形.给你一组数据,告诉你哪些点间有一条红线,计算同色三角形的总数. ...
- Pandas 错误笔记(持续更新)
更新至2018.5.1 字典生成DataFrame 今天一个字典生成一个DataFrame,采用了以下形式,每一个value都是一个数(不是vector) df = pd.DataFrame({ 'i ...
- Hadoop配置第1节-集群网络配置
Hadoop-集群网络配置 总体目标:完成zookeeper+Hadoop+Hbase 整合平台搭建 进度:1:集群网络属性配置2:集群免密码登陆配置3:JDK的安装4:Zookeeper的安装5 ...
- [Inside HotSpot] C1编译器HIR的构造
1. 简介 这篇文章可以说是Christian Wimmer硕士论文Linear Scan Register Allocation for the Java HotSpot™ Client Compi ...
- 【Python3爬虫】常见反爬虫措施及解决办法(二)
这一篇博客,还是接着说那些常见的反爬虫措施以及我们的解决办法.同样的,如果对你有帮助的话,麻烦点一下推荐啦. 一.防盗链 这次我遇到的防盗链,除了前面说的Referer防盗链,还有Cookie防盗链和 ...
- Fiddler 接口测试(Composer)的使用方法及并发测试
下载地址:https://www.telerik.com/download/fiddler 一.Composer简介 右侧Composer区域,是测试接口的界面: 相关说明: 1.请求方式:点开可以勾 ...
- Center a website:网页居中
inside the <body> tags, using a "wrapper" div to control the whole section. HTML: &l ...