pandas的数据联级
一.索引的堆(stack)
1.行列的转化:
Stack():列转行
Unstack():行转列
Stack对应行,
使用小技巧:使用stack()的时候,level等于哪一个,哪一个就消失,出现在行里。
使用UNstack的时候,level等于哪一个,哪一个就消失,出现在列里。
如:
原来:A:
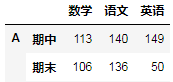
现在:A.stack(level=0).unstack(level=0).unstack(level=0)执行后
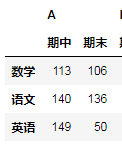
二.多层索引的聚合操作
所谓的操作是指:平均数mean()、方差std()、最大数max()、最小值min()等.....
注意:需要指定axis
小技巧:和unstack()相反,聚合操作的时候,axis等于哪一个,哪一个就保留
求平均值:
重点是axis和level的组合
A.mean(axis=0,level=1)
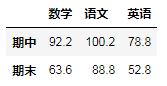
求方差:
df.std(asis=x,level=y)
方差是衡量随随机变量或一组数据时离散程度的度量。
A.std(axis=0,level=0)

Pandas的拼接操作
1.联级:pd.concal,pd.append
(1)使用pd.concat()级联
Pandas使用pd.concat()函数,与np.concatenate函数类似,只是多了一些参数
dp.concat(['objs', 'axis=0', "join='outer'", 'join_axes=None', 'ignore_index=False', 'keys=None', 'levels=None', 'names=None', 'verify_integrity=False', 'sort=None', 'copy=True'])
Concat()此方法默认增加行数,即样本。通过设置axis进行行方向或是列方向的级联。
如:
行方向级联:
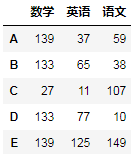
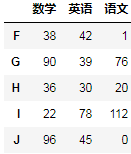
pd.concat([df1,df2],axis=0)
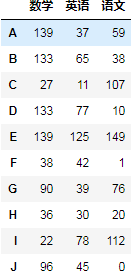
进行列方向级联
df3: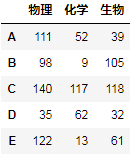
pd.concat([df1,df3],axis=1)
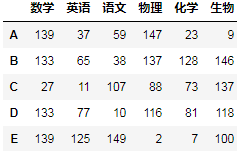
Pandas中的参数:
['objs', 'axis=0', "join='outer'", 'join_axes=None', 'ignore_index=False', 'keys=None', 'levels=None', 'names=None', 'verify_integrity=False', 'sort=None', 'copy=True']
Jgnore_index:
默认:False
如果为T,忽视给定的索引值,用1,2,3,4,.....代替,当然在操作时,以前给定的索引值失效。
如:pd.concat([df1,df2],ignore_index=True)
Keys:
序列,默认没有
如果传递了多个级别,则应该包含元组。构造使用传递的键作为最外层的分层索引
如:pd.concat([df1,df1],keys=["期中","期末"])
Join:
默认join=”outer”
Outer指合并除了公有列还合并非共有列
Inner指只合公有列
如:
pd.concat([df1,df5],join="outer")
pd.concat([df1,df5],join="inner")
Join_axes
当两张表中数据有部分列不同时,可以设置join_axes根据那个表中的列进行合并
如:pd.concat([df1,df5],join_axes=[df5.columns])
(2)使用append()追加
如:df1.append(df2)
- 合并:pd.merge,pd.join
(1)Merge:融合
A.参数:
['right', "how='inner'", 'on=None', 'left_on=None', 'right_on=None', 'left_index=False', 'right_index=False', 'sort=False', "suffixes=('_x', '_y')", 'copy=True', 'indicator=False', 'validate=None']
根据表中的属性值相同进行融合
Merge与concat的区别
merge需要依据某一共同的行或者列进行合并,使用pd.merge()合并时,会自动根据两者形同的column名称的那一列,作为key来进行合并。注意每一列元素的顺序不要求一致。
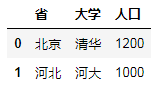
B.一对一合并
如:
df6 = DataFrame({"省":["北京","山东","河北"],"大学":["清华","山大","河大"],"人口":[1200,200,1000]})
df7 = DataFrame({"省":["北京","上海","河北"],"大学":["清华","复旦","河大"],"人口":[1200,1220,1000]})
df6.merge(df7)
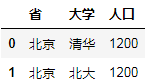
C.多对一合并
Df8 = DataFrame({"省":["北京","山东","北京"],"大学":["清华","山大","北大"]})
Df9 = DataFrame({"省":["北京","上海","河北"],"人口":[1200,1220,1000]})
Df8.merge(df9)
D.多对多合并
df6 = DataFrame({"省":["北京","山东","北京"],"大学":["清华","山大","北大"]})
df7 = DataFrame({"省":["北京","上海","北京"],"人口":[1200,1220,1000]})
df6.merge(df7)

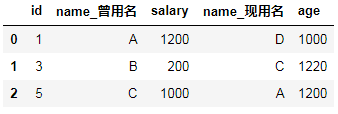
E.Key的规范化
使用on=显示指定那一列为key,当有多个key相同时使用
如:
df6 = DataFrame({"id":[1,3,5],"name":["A","B","C"],"salary":[1200,200,1000]})
df7 = DataFrame({"id":[5,3,1],"name":["A","C","D"],"age":[1200,1220,1000]})
df6.merge(df7,on="id",suffixes=["_曾用名","_现用名"]) #指定根据id进行合并
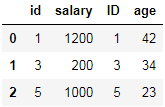
使用left_on和right_on指定左右两边的列作为key,当左右两边的key都不相等时使用
如:
df6 = DataFrame({"id":[1,3,5],"salary":[1200,200,1000]})
df7 = DataFrame({"ID":[5,3,1],"age":[23,34,42]})
df6.merge(df7,left_on = "id",right_on = "ID")
内合并与外合并
内合并:只保留两者都有的key(默认模式)
How = “inner”
外合并:how = “outer”,补nan
左合并,右合并:how=”left”,how=”right”
G.列冲突的解决
当列冲突时,即有多个列名称相同时,需要使用on=来指定哪一个作为key,配合suffixes指定冲突列名,可以使用suffixes=自己指定的列名
Left_index=,right_index=,是否使用索引
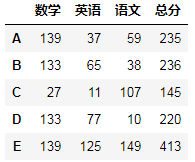
如:将总分列添加到总表中
s = df1.sum(axis=1)
df0 = DataFrame(s,columns=["总分"])
df1.merge(df0,left_index=True,right_index=True)
pandas的数据联级的更多相关文章
- FreeSql 导航属性的联级保存功能
写在前面 FreeSql 一个款 .net 平台下支持 .net framework 4.5+..net core 2.1+ 的开源 ORM.单元测试超过3100+,正在不断吸引新的开发者,生命不息开 ...
- Blazor和Vue对比学习(基础1.6):祖孙传值,联级和注入
前面章节,我们实现了父子组件之间的数据传递.大多数时候,我们以组件形式来构建页面的区块,会涉及到组件嵌套的问题,一层套一层.这种情况,很大概率需要将祖先的数据,传递给子孙后代去使用.我们当然可以使用父 ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 【转载】使用Pandas对数据进行筛选和排序
使用Pandas对数据进行筛选和排序 本文转载自:蓝鲸的网站分析笔记 原文链接:使用Pandas对数据进行筛选和排序 目录: sort() 对单列数据进行排序 对多列数据进行排序 获取金额最小前10项 ...
- 【转载】使用Pandas进行数据提取
使用Pandas进行数据提取 本文转载自:蓝鲸的网站分析笔记 原文链接:使用python进行数据提取 目录 set_index() ix 按行提取信息 按列提取信息 按行与列提取信息 提取特定日期的信 ...
- 【转载】使用Pandas进行数据匹配
使用Pandas进行数据匹配 本文转载自:蓝鲸的网站分析笔记 原文链接:使用Pandas进行数据匹配 目录 merge()介绍 inner模式匹配 lefg模式匹配 right模式匹配 outer模式 ...
- 【转载】使用Pandas创建数据透视表
使用Pandas创建数据透视表 本文转载自:蓝鲸的网站分析笔记 原文链接:使用Pandas创建数据透视表 目录 pandas.pivot_table() 创建简单的数据透视表 增加一个行维度(inde ...
- Pandas 把数据写入csv
Pandas 把数据写入csv from sklearn import datasets import pandas as pd iris = datasets.load_iris() iris_X ...
- pandas学习(数据分组与分组运算、离散化处理、数据合并)
pandas学习(数据分组与分组运算.离散化处理.数据合并) 目录 数据分组与分组运算 离散化处理 数据合并 数据分组与分组运算 GroupBy技术:实现数据的分组,和分组运算,作用类似于数据透视表 ...
随机推荐
- 【SpringBoot】编写一个自己的Starter
一.什么是Starter? 在开发过程中我们就经常使用到各种starter,比如mybatis-spring-boot-starter,只需要进行简单的配置即可使用,就像一个插件非常方便.这也是Spr ...
- Glassfish 4 修改server.log 等配置
如果所示:
- CF 1215解题报告
T1 偶数输出n/2 奇数输出(n-1)/2即可 T2 判断是不是回文 不是直接输出子串 是回文继续判断 如果他前(len+1)/2内没有相同 输出-1 其他的 交换不同字符,输出子串 T3 贪心+二 ...
- sublime安装与使用
整理sublime的安装和使用的步骤,以及一些常用插件的安装.配置.使用.免得每次换环境都需要重新上网查找一堆资料. 前言目前使用的版本是sublime text3.选择sublime的理由 subl ...
- spring 公用异常处理
1. 采用spring boot注解方式,如果采用swagger的话会导致swagger不可用 1.1 spring 配置如下 #出现错误时, 直接抛出异常 spring.mvc.throw-exc ...
- [bzoj 1758] 重建计划
bzoj 1758 重建计划 题意: 给定一棵有边权的树和两个数 \(L, R (L\leq R)\),求一条简单路径,使得这条路径经过的边数在 \(L, R\) 之间且路径经过的边的边权的平均值最大 ...
- Hive进阶_汇总
=========================================================================== 第2章 Hive数据的导入 使用Load语句执行 ...
- devOps开发(Web API 实例)dotnet core 和 Azure PaaS服务
使用 dotnet core 和 Azure PaaS服务进行devOps开发(Web API 实例) 作者:陈希章 发表于 2017年12月19日 引子 这一篇文章将用一个完整的实例,给大家介绍如何 ...
- JavasJavaScript笔试题
这几天参加了好多场宣讲会,记录一下遇到的编程题还有平时练习遇到的(如果有更好的方法欢迎提出,本人也是菜鸟一枚): 1.数组查重,并返回出重复次数最多的项并记录重复次数: function chacho ...
- scrapy-redis 分布式哔哩哔哩网站用户爬虫
scrapy里面,对每次请求的url都有一个指纹,这个指纹就是判断url是否被请求过的.默认是开启指纹即一个URL请求一次.如果我们使用分布式在多台机上面爬取数据,为了让爬虫的数据不重复,我们也需要一 ...