集成学习之Adaboost算法原理
在boosting系列算法中,Adaboost是最著名的算法之一。Adaboost既可以用作分类,也可以用作回归。
1. boosting算法基本原理
集成学习原理中,boosting系列算法的思想:

Boosting算法首先对训练集用初始权重训练一个弱学习器1,根据弱学习1的学习误差率更新训练样本点的权重,使学习误差率高的点权重变高,从而在弱学习器2得到更多重视。然后训练弱学习器2。如此重复进行,直到弱学习器到达到指定数目T,最后将T个弱学习通过集合策略整合成强学习器。
2. Adaboost算法原理
这里讲解Adaboost算法中如何解决下面4个问题:
- 如何计算学习误差率e
- 如何得到弱学习器权重系数α
- 如何更新样本权重D
- 结合策略
假设训练样本是

训练集第k个弱学习器的输出权重为
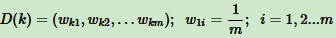
Adaboost分类问题
多元分类是二元分类的推广,假设我们是二元分类,输出为 {-1, 1},
则第k个弱分类器 Gk(x) 在训练集上的加权误差率为
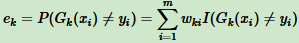
对于二分类问题,第k个弱分类器 Gk(x) 的权重系数为
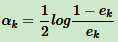
从上式看出,分类误差率 ek 越大,对应的弱分类器权重系数 αk 越小。即误差率小的弱分类器权重系数越大。
更新样本权重D。假设第 k 个弱分类器的样本集权重系数为 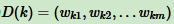 ,对应的第 k+1 个弱分类器的样本集权重系数为
,对应的第 k+1 个弱分类器的样本集权重系数为

这里 Zk 是规范化因子
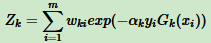
从 wk+1,i 公式看出,如果第 i 个分类样本错误,则  ,导致样本权重在第 k+1 个弱分类器中增大,如果分类正确,则权重在第 k+1 个弱分类器中减少。
,导致样本权重在第 k+1 个弱分类器中增大,如果分类正确,则权重在第 k+1 个弱分类器中减少。
集成学习之Adaboost算法原理的更多相关文章
- 集成学习值Adaboost算法原理和代码小结(转载)
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类: 第一个是个体学习器之间存在强依赖关系: 另一类是个体学习器之间不存在强依赖关系. 前者的代表算法就是提升(bo ...
- 集成学习之Adaboost算法原理小结
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系.前者的代表算法就是是boostin ...
- AdaBoost算法原理简介
AdaBoost算法原理 AdaBoost算法针对不同的训练集训练同一个基本分类器(弱分类器),然后把这些在不同训练集上得到的分类器集合起来,构成一个更强的最终的分类器(强分类器).理论证明,只要每个 ...
- 学习《深度学习与计算机视觉算法原理框架应用》《大数据架构详解从数据获取到深度学习》PDF代码
<深度学习与计算机视觉 算法原理.框架应用>全书共13章,分为2篇,第1篇基础知识,第2篇实例精讲.用通俗易懂的文字表达公式背后的原理,实例部分提供了一些工具,很实用. <大数据架构 ...
- 机器学习之Adaboost算法原理
转自:http://www.cnblogs.com/pinard/p/6133937.html 在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习 ...
- 机器学习回顾篇(13):集成学习之AdaBoost
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 基于单层决策树的AdaBoost算法原理+python实现
这里整理一下实验课实现的基于单层决策树的弱分类器的AdaBoost算法. 由于是初学,实验课在找资料的时候看到别人的代码中有太多英文的缩写,不容易看懂,而且还要同时看代码实现的细节.算法的原理什么的, ...
- 数据挖掘学习笔记--AdaBoost算法(一)
声明: 这篇笔记是自己对AdaBoost原理的一些理解,如果有错,还望指正,俯谢- 背景: AdaBoost算法,这个算法思路简单,但是论文真是各种晦涩啊-,以下是自己看了A Short Introd ...
- 集成学习之AdaBoost
AdaBoost 当做出重要决定时,大家可能会考虑吸取多个专家而不只是一个人的意见,机器学习也是如此,这就是集成学习的基本思想.使用集成方法时有多种形式:可以是不同算法的集成,也可以是同一算法在不同设 ...
随机推荐
- 【异常】hue:unknown database hue
1 hue error日志报错,找不到hue数据库 2 解决办法 删除hue服务,重新添加,再次在添加database阶段验证密码,test通过,再继续. 还有造成这个事情的原因,是自己移动了mysq ...
- XML和XML解析
1. XML文件: 什么是XML?XML一般是指可扩展标记语言,标准通用标记语言的子集,是一种用于标记电子文件使其具有结构性的标记语言. 2.XML文件的优点: 1)XML文档内容和结构完全分离. 2 ...
- mysql数据库:mysql增删改、单表、多表及子查询
一.数据增删改 二.单表查询 三.正表达式匹配 四.多表查询 五.子查询 一..数据增删改 增加 insert [into] 表名[(可选字段名)] values(一堆值1),( ...
- 第1章 python入门
1.1 python的出生与应用 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏姆(中文名字:龟叔)为了在阿姆斯特丹打发时间,决心开 ...
- poj3417 Network/闇の連鎖[树上差分]
首先隔断一条树边,不计附加边这个树肯定是断成两块了,然后就看附加边有没有连着的两个点在不同的块内. 方法1:BIT乱搞(个人思路) 假设考虑到$x$节点隔断和他父亲的边,要看$x$子树内有没有点连着附 ...
- python3爬虫--shell命令的使用和firefox firebug获取目标信息的xpath
scrapy version -v #该命令用于查看scrapy安装的相关组件和版本 一个工程下可创建多个爬虫 scrapy genspider rxmetal rxmetal.com scrapy ...
- 1 FBV与CBV,前后端分离(初识),postman
yuan的Blog:https://www.cnblogs.com/yuanchenqi/articles/8715364.html alice的Blog:https://www.cnblogs.co ...
- HDU 5335 Walk Out BFS 比较坑
H - H Time Limit:1000MS Memory Limit:65536KB 64bit IO Format:%I64d & %I64u Submit Status ...
- 博弈dp入门 POJ - 1678 HDU - 4597
本来博弈还没怎么搞懂,又和dp搞上了,哇,这真是冰火两重天,爽哉妙哉. 我自己的理解就是,博弈dp有点像对抗搜索的意思,但并不是对抗搜索,因为它是像博弈一样,大多数以当前的操作者来dp,光想是想不通的 ...
- HTML5属性备忘单
在网上闲逛的时候看到了文章,感觉总结的这个html5文章,决定转载过来,在排版的时候也帮助自己重新梳理复习一遍.毕竟学习基础最重要. by zhangxinxu from http://www.zha ...