Flume-Exec Source 监控单个本地文件
实时监控,并上传到 HDFS 中。
一、Flume 要想将数据输出到 HDFS,须持有 Hadoop 相关 jar 包
若 Hadoop 环境和 Flume 在同一节点,那么只要配置 Hadoop 环境变量即可,不需要复制相关 jar 包。
# 将相关包拷贝到 flume 的 lib 目录下
# commons-configuration-x.x.jar
# hadoop-auth-x.x.x.jar、
# hadoop-common-x.x.x.jar、
# hadoop-hdfs-x.x.x.jar、
# commons-io-x.x.jar、
# htrace-core-x.x.x-incubating.jar cp /opt/hadoop-2.9./share/hadoop/hdfs/hadoop-hdfs-2.9..jar /opt/apache-flume-1.9.-bin/lib/
cp /opt/hadoop-2.9./share/hadoop/common/hadoop-common-2.9..jar /opt/apache-flume-1.9.-bin/lib/
cp /opt/hadoop-2.9./share/hadoop/common/lib/commons-io-2.4.jar /opt/apache-flume-1.9.-bin/lib/
cp /opt/hadoop-2.9./share/hadoop/common/lib/hadoop-auth-2.9..jar /opt/apache-flume-1.9.-bin/lib/
cp /opt/hadoop-2.9./share/hadoop/common/lib/commons-configuration-1.6.jar /opt/apache-flume-1.9.-bin/lib/
cp /opt/hadoop-2.9./share/hadoop/common/lib/htrace-core4-4.1.-incubating.jar /opt/apache-flume-1.9.-bin/lib/
二、创建 flume-file-hdfs.conf 文件
https://flume.apache.org/FlumeUserGuide.html#exec-source
https://flume.apache.org/FlumeUserGuide.html#flume-sinks
要想读取 Linux 系统中的文件,就得按照 Linux 命令的规则执行命令。由于 Hive 日志在 Linux 系统中所以读取文件的类型选择:exec 即 execute 执行的意思。表示执行 Linux 命令来读取文件。
# Name the components on this agent
# 定义 source
a2.sources = r2
# 定义 sink
a2.sinks = k2
# 定义 channel
a2.channels = c2 # Describe/configure the source
# 定义 source 类型为 exec 可执行命令
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /tmp/tomcat.log
# 执行 shell 脚本的绝对路径
a2.sources.r2.shell = /bin/bash -c # Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://h136:9000/flume/%Y%m%d/%H
# 上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
# 是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round = true
# 多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
# 重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
# 是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
# 积攒多少个 Event 才 flush 到 HDFS 一次
a2.sinks.k2.hdfs.batchSize = 100
# 设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
# 多久生成一个新的文件
a2.sinks.k2.hdfs.rollInterval = 30
# 设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
# 文件的滚动与 Event 数量无关
a2.sinks.k2.hdfs.rollCount = 0 # Use a channel which buffers events in memory
# 表示 a2 的 channel 类型是 memory 内存型
a2.channels.c2.type = memory
# 表示 a2 的 channel 总容量 1000 个 event
a2.channels.c2.capacity = 1000
# 表示 a2 的 channel 传输时收集到了 100 条 event 以后再去提交事务
a2.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel
# 表示将 r2 和 c2 连接起来
a2.sources.r2.channels = c2
# 表示将 k2 和 c2 连接起来
a2.sinks.k2.channel = c2
注意:a2.sinks.k2.hdfs.useLocalTimeStamp = true,对于所有与时间相关的转义序列,Event Header 中必须存在以 “timestamp” 的 key(除非 hdfs.useLocalTimeStamp 设置为 true,此方法会使用 TimestampInterceptor 自动添加 timestamp)。
三、启动
在启动之前需要先启动 Hadoop 环境。
cd /opt/apache-flume-1.9.-bin/
bin/flume-ng agent --conf conf/ --name a2 --conf-file /tmp/flume-job/flume-file-hdfs.conf -Dflume.root.logger=INFO,console # 追加日志内容
echo 'add xxxxx' >> /tmp/tomcat.log
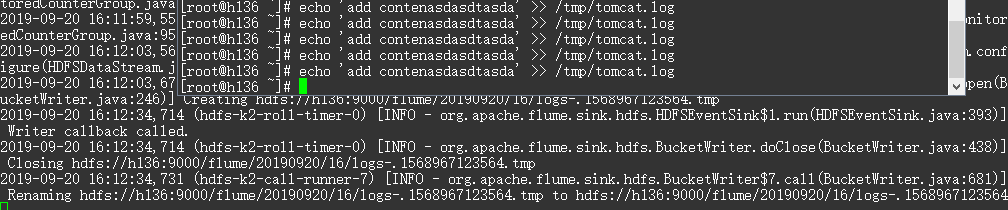
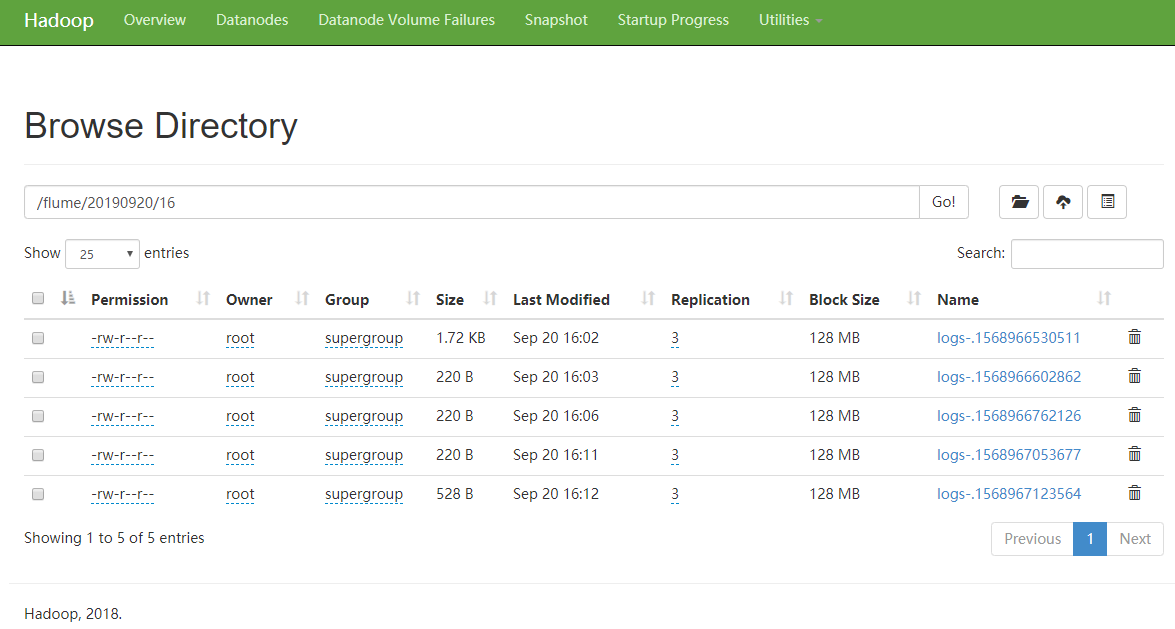
HDFS 上的文件
Flume-Exec Source 监控单个本地文件的更多相关文章
- 一次flume exec source采集日志到kafka因为单条日志数据非常大同步失败的踩坑带来的思考
本次遇到的问题描述,日志采集同步时,当单条日志(日志文件中一行日志)超过2M大小,数据无法采集同步到kafka,分析后,共踩到如下几个坑.1.flume采集时,通过shell+EXEC(tail -F ...
- Flume-Taildir Source 监控目录下多个文件的追加
Exec source 适用于监控一个实时追加的文件,但不能保证数据不丢失:Spooldir Source 能够保证数据不丢失,且能够实现断点续传,但延迟较高,不能实时监控:而 Taildir Sou ...
- flume使用之exec source收集各端数据汇总到另外一台服务器
转载:http://blog.csdn.net/liuxiao723846/article/details/78133375 一.场景一描述: 线上api接口服务通过log4j往本地磁盘上打印日志,在 ...
- Flume-Spooling Directory Source 监控目录下多个新文件
使用 Flume 监听整个目录的文件,并上传至 HDFS. 一.创建配置文件 flume-dir-hdfs.conf https://flume.apache.org/FlumeUserGuide.h ...
- 第1节 网站点击流项目(上):4、网站的数据采集,使用flume的taildir实现多个文件的监控采集
一. 模块开发----数据采集 1. 需求 在网站web流量日志分析这种场景中,对数据采集部分的可靠性.容错能力要求通常不会非常严苛,因此使用通用的flume日志采集框架完全可以满足需求. 2. Fl ...
- 本地文件到通过flume到hdfs
配置文件 cd /usr/app/flume1.6/conf vi flume-dirTohdfs.properties #agent1 name agent1.sources=source1 age ...
- 本地文件到通过flume到kafka
配置文件 cd /usr/app/flume1.6/conf vi flume-dirKakfa.properties #agent1 name agent1.sources=source1 agen ...
- Flume案例Ganglia监控
Flume案例和Flume监控系统的使用: 安装 将apache-flume-1.7.0-bin.tar.gz上传到linux的/opt/software目录下 解压apache-flume-1.7. ...
- Flume:source和sink
Flume – 初识flume.source和sink 目录基本概念常用源 Source常用sink 基本概念 什么叫flume? 分布式,可靠的大量日志收集.聚合和移动工具. events ...
随机推荐
- 深入JavaScript对象(Object)与类(class),详细了解类、原型
JavaScript基于原型的对象机制 JavaScript原型上的哪些事 一.JavaScript基于原型的对象机制 JavaScript对象是基于原型的面向对象机制.在一定程度上js基于原型的对象 ...
- WinPE基础知识之导出表
// 导出的东西包括函数(变量.类)地址,序号,函数(变量.类)名 typedef struct _IMAGE_EXPORT_DIRECTORY { DWORD Characteristics; // ...
- 红外 NEC编码
它是一种电磁波,可以实现数据的无线传输 它的波长范围为760nm ~ 1mm,不为人眼所见 紫外光波长为10-400nm 红外与蓝牙 红外:对准.直接.0-10米,单对单 蓝牙:10米左右,加强信号后 ...
- You are using the runtime-only build of Vue where the template compiler is not available.
使用vue-cli搭建的项目,启动报错 You are using the runtime-only build of Vue where the template compiler is not a ...
- JavaSpring【六、AOP的API】
AOP API Spring1.2历史用法,现在仍然支持 现在xml配置和注解的用法是基于API的,只是比较简便
- IDEA找不到maven仓库无法下载依赖解决办法
1.确认Maven安装正常,在cmd窗口输入mvn -version 可以获得版本号: 2. 确认maven安装包下/conf/setting.xml配置文件正确 本地仓库位置: <localR ...
- (十四)Linux kernel mmc 框架说明,包括mmc_test使用方法
1.Linux 总线模型 Linux下的任何驱动在内核中最终都抽象为bus, driver以及device三者间的相互作用. 总线是处理器和一个或多个设备之间的通道,在设备模型中,所有 ...
- python+selenium之——错误:selenium.common.exceptions.WebDriverException: Message: ‘geckodriver’ executable needs to be in PATH.
此时,需要自己配置geckodriver 下载geckodriver,地址:https://github.com/mozilla/geckodriver/releases 下载后解压得到geckodr ...
- pyltp安装
第一步:下载wheel文件 第二步:进入该文件的文件夹 第三步:pip install wheel文件名 注意:python的安装版本必须和pyltp的版本相同,我这版本都是pyhton3.6.之前p ...
- bat 读取 ini 文件
bat 读取 ini 文件 参考链接:https://stackoverflow.com/questions/2866117/windows-batch-script-to-read-an-ini-f ...