GBDT笔记
GBDT笔记
GBDT是Boosting算法的一种,谈起提升算法我们熟悉的是Adaboost,它和AdaBoost算法不同;
区别如下: AdaBoost算法是利用前一轮的弱学习器的误差来更新样本权重值,然后一轮一轮的迭代;
GBDT也是迭代,但是GBDT要求弱学习器必须是CART模型,
而且GBDT在模型训练的时候,是要求模型预测的样本损失尽可能的小。
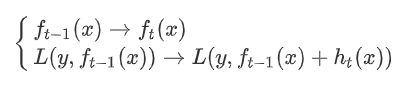
GBDT由三部分构成:
DT(Regression Decistion Tree)、GB(Gradient Boosting)和Shrinkage(衰减)
GBD是由多棵决策树组成,所有树的结果累加起来就是最终结果 迭代决策树和随机森林的区别: 随机森林使用抽取不同的样本构建不同的子树,也就是说第m棵树的构建和前m-1棵树的 结果是没有关系的 迭代决策树在构建子树的时候,使用之前子树构建结果后形成的残差作为输入数据构建下 一个子树;然后最终预测的时候按照子树构建的顺序进行预测(串行),并将预测结果相加.
训练过程
希望损失函数能够不断的减小,并且能够尽可能快的减小。 1.让损失函数沿着梯度方向的下降。这个就是gb。 2.利用损失函数的负梯度在当前模型的值作为回归问题提升树算法中的残差的近似值去拟合一个回归树。这个是dt。 3.这样每轮训练的时候都能够让损失函数尽可能快的减小,尽快的收敛达到局部最优解或者全局最优解。
特征选择
gbdt选择特征的细节其实就是CART树生成的过程。 gbdt的弱分类器默认选择的是CART树。其实也可以选择其他弱分类器的(前提是低方差和高偏差。框架服从boosting 框架即可) CART树(是一种二叉树) 的生成:
CART树生成的过程其实就是一个选择特征的过程
假设我们目前总共有 M 个特征。
从中选择出一个特征 j,做为二叉树的第一个节点(选择量度为基尼系数)。
对特征 j 的值选择一个切分点 m.
一个样本的特征j的值如果小于m则分为一类,如果大于m则分为另外一类,如此便构建了CART 树的一个节点。
其他节点的生成过程和这个是一样的迭代生成。
对于每轮选择的时候,如何选择这个特征 j,以及如何选择特征 j 的切分点 m,原始的gbdt的做法非常的暴力,首先遍历每个特征,然后对每个特征遍历它所有可能的切分点,找到最优特征 m 的最优切分点 j。
算法原理
首先给定输入向量X和输出变量Y组成的若干训练样本(X1,Y1),(X2,Y2)......(Xn,Yn),目标是找到近似函数F(X),使得损失函数L(Y,F(X))的损失值最小。 L损失函数一般采用最小二乘损失函数或者绝对值损失函数:
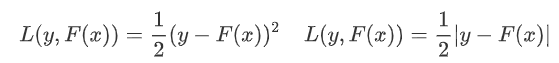
求最优解:

假定最终模型F(x) 是一组最优基函数f(x)的加权和:
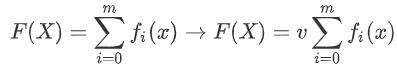
使用贪心算法的思想扩展得到Fm(X),求解最优f:
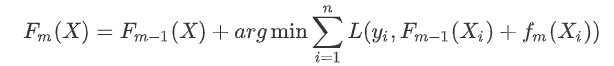
但是贪心法在每次选择最优基函数f时仍然困难,使用梯度下降的方法近似计算
给定常数函数F0(X):

根据梯度下降求解学习率:
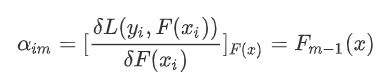
使用数据(x_i,α_im) (i=1……n )计算拟合残差找到一个CART回归树,得到第m棵树:
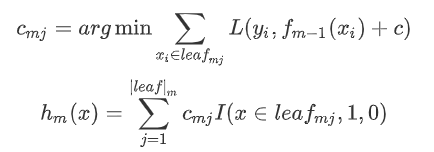
更新模型:

缺点:GBDT在sklearn中执行速度是最慢的
from sklearn.ensemble import GradientBoostingRegressor
# 使用AdaBoostRegressor; GBDT模型只支持CART模型
gbdt = GradientBoostingRegressor(n_estimators=100, learning_rate=0.01, random_state=14)
gbdt.fit(x_train, y_train)
print("训练集上R^2:%.5f" % gbdt.score(x_train, y_train))
print("测试集上R^2:%.5f" % gbdt.score(x_test, y_test))
GBDT笔记的更多相关文章
- 笔记︱决策树族——梯度提升树(GBDT)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 本笔记来源于CDA DSC,L2-R语言课程所 ...
- Boosting学习笔记(Adboost、GBDT、Xgboost)
转载请注明出处:http://www.cnblogs.com/willnote/p/6801496.html 前言 本文为学习boosting时整理的笔记,全文主要包括以下几个部分: 对集成学习进行了 ...
- [笔记]GBDT理论知识总结
一. GBDT的经典paper:<Greedy Function Approximation:A Gradient Boosting Machine> Abstract Function ...
- GBDT学习笔记
GBDT(Gradient Boosting Decision Tree,Friedman,1999)算法自提出以来,在各个领域广泛使用.从名字里可以看到,该算法主要涉及了三类知识,Gradient梯 ...
- scikit-learn 梯度提升树(GBDT)调参笔记
在梯度提升树(GBDT)原理小结中,我们对GBDT的原理做了总结,本文我们就从scikit-learn里GBDT的类库使用方法作一个总结,主要会关注调参中的一些要点. 1. scikit-learn ...
- 【学习笔记】GBDT算法和XGBoost
前言 这一篇内容我学了足足有五个小时,不仅仅是因为内容难以理解, 更是因为前面CART和提升树的概念和算法本质没有深刻理解,基本功不够就总是导致自己的理解会相互在脑子里打架,现在再回过头来,打算好好总 ...
- Adaboost\GBDT\GBRT\组合算法
Adaboost\GBDT\GBRT\组合算法(龙心尘老师上课笔记) 一.Bagging (并行bootstrap)& Boosting(串行) 随机森林实际上是bagging的思路,而GBD ...
- 机器学习&数据挖掘笔记(常见面试之机器学习算法思想简单梳理)
机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理) 作者:tornadomeet 出处:http://www.cnblogs.com/tornadomeet 前言: 找工作时( ...
- [转]机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理)
机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理) 转自http://www.cnblogs.com/tornadomeet/p/3395593.html 前言: 找工作时(I ...
随机推荐
- Java基础系列 - 查找数组的最大值和最小值
package com.test6; public class test5 { public static void main(String[] args) { int[] arr = {1, 2, ...
- 【原】Python基础-函数
#不定长参数,这里prams是一个元组集合def print_params(*prams): for e in prams: print(e) print(prams) #输出('xxx', (1, ...
- 2018-2019-2 20165234 《网络对抗技术》 Exp9 Web安全基础
Exp9 Web安全基础 一. 实践内容 1. 安装JDK.Webgoat 2. SQL注入攻击 数字型注入(Numeric SQL Injection) 日志欺骗(Log Spoofing) 字符串 ...
- 微信小程序设置滚动条
前言 又很久没有写东西了,上周开始将一个APP和一个网站的内容整合到微信小程序中,到这会儿终于搞得快结束了,才发现为啥我的小程序滚动视图没有滚动条,这是闹哪样,没有滚动条的滚动是没有灵魂的. 客官可移 ...
- IDEA使用(03)_git撤回(已经commit未push的)操作
1.问题来源 日常工作中会遇到 commit 到本地仓库的代码,因为一些原因,需要撤销后再提交到本地,或者需要整合多次 commit,然后 push 到远程仓库. 2.IDEA解决方案 I.在idea ...
- DELPHI10.3.2安卓SDK安装
DELPHI10.3.2安卓SDK安装 DELPHI10.3.2默认安装以后,还需要安装安卓SDK,才可以编译安卓项目. 1)运行Android Tools 2)勾选安装下面几个
- 请解释一下 JavaScript 的同源策略
概念: 同源策略是客户端脚本(尤其是Netscape Navigator2.0,其目的是防止某个文档或脚本从多个不同源装载. 这里的同源策略指的是:协议,域名,端口相同,同源策略是一种安全协议. 指一 ...
- linux redis 设置密码:
在服务器上,这里以linux服务器为例,为redis配置密码. 1.第一种方式 (当前这种linux配置redis密码的方法是一种临时的,如果redis重启之后密码就会失效,) (1)首先进入redi ...
- 机器学习 - 算法 - Xgboost 数学原理推导
工作原理 基于集成算法的多个树累加, 可以理解为是弱分类器的提升模型 公式表达 基本公式 目标函数 目标函数这里加入了损失函数计算 这里的公式是用的均方误差方式来计算 最优函数解 要对所有的样本的损失 ...
- 让群辉支持DTS音轨
让群晖Video Station支持DTS音轨的方法原因:因版权问题,群晖Video Station默认不支持DTS音轨,因此默认不能播放使用DTS音轨的影片. 网上搜到好多解决办法,通常是让添加源h ...