05_Hive分区总结
2.1.创建分区表并将本地文件的数据加载到分区表:
使用下面的命令来创建一个带分区的表

通过partitioned by(country string)关键字声明该表是分区表,且分区字段不能为create table时存在的字段。此
时只能说指定了这个表会分区,但是具体数据有哪些分区则会在导入数据时产生
使用下面的命令来指定具体导入到哪个分区:

查询该分区表:select * from t_part;
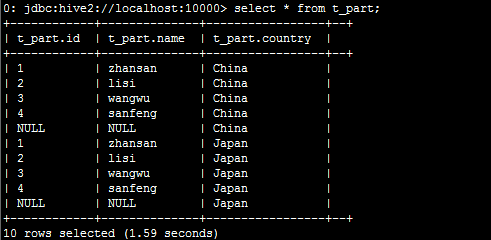
此时分区字段已经变成一个伪字段了。如果要分区查询,可以使用Where或者Group by来进行限定;
2.2.Hive中上传数据:
之前我们直接将数据文件上传到了Hive表所在的数据目录,其实Hive还提供了一个Load命令供我们将数据进行上传
语法结构:Load
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO
TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
参数说明:
Load 操作只是单纯的复制/移动操作,将数据文件移动到 Hive 表对应的位置。
filepath:
相对路径,例如:project/data1
绝对路径,例如:/user/hive/project/data1
包含模式的完整 URI,列如:hdfs://namenode:9000/user/hive/project/data1
LOCAL关键字
如果指定了 LOCAL, load 命令会去查找本地文件系统中的 filepath
如果没有指定 LOCAL关键字,则根据inpath中的uri查找文件
OVERWRITE 关键字
若使用了 OVERWRITE 关键字,则目标表(或者分区)中的内容会被删除,然后再将 filepath 指向的文件/目录中的内容添加到表/分区中
如果目标表(分区)已经有一个文件,并且文件名和 filepath 中的文件名冲突,那么现有的文件会被新文件所替代。
2.3.Hive修改表_增加/删除分区:
语法结构
ALTER TABLE table_name ADD [IF NOT EXISTS] partition_spec [ LOCATION 'location1' ]
partition_spec [ LOCATION 'location2' ] ...
partition_spec:
: PARTITION (partition_col = partition_col_value, partition_col = partiton_col_value, ...) ALTER TABLE table_name DROP partition_spec, partition_spec,...
增加分区:alter table t_part add partition (country='American');
删除分区:alter table t_part drop partition (country='American');
查看分区数据:
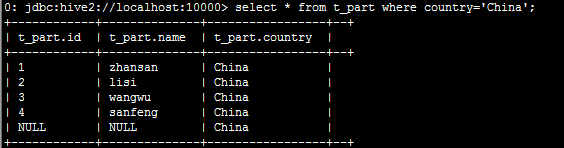
查看分区:show partitions t_part;

总结:分区的目的就是提高查询效率,查询分区数据的方式就是指定分区名,指定分区名之后就不再全表扫描,直接从指
定分区(如name=jack的分区)中查询,从hdfs的角度看就是从相应的文件系统中(如country=‘China’文件夹下)去查找
特定的数据
05_Hive分区总结的更多相关文章
- SQL Server表分区
什么是表分区 一般情况下,我们建立数据库表时,表数据都存放在一个文件里. 但是如果是分区表的话,表数据就会按照你指定的规则分放到不同的文件里,把一个大的数据文件拆分为多个小文件,还可以把这些小文件放在 ...
- win7安装时,避免产生100m系统保留分区的办法
在通过光盘或者U盘安装Win7操作系统时,在对新硬盘进行分区时,会自动产生100m的系统保留分区.对于有洁癖的人来说,这个不可见又删不掉的分区是个苦恼.下面介绍通过diskpart消灭保留分区的办法: ...
- Partition:增加分区
在关系型 DB中,分区表经常使用DateKey(int 数据类型)作为Partition Column,每个月的数据填充到同一个Partition中,由于在Fore-End呈现的报表大多数是基于Mon ...
- Partition2:对表分区
在SQL Server中,普通表可以转化为分区表,而分区表不能转化为普通表,普通表转化成分区表的过程是不可逆的,将普通表转化为分区表的方法是: 在分区架构(Partition Scheme)上创建聚集 ...
- Partition:分区切换(Switch)
在SQL Server中,对超级大表做数据归档,使用select和delete命令是十分耗费CPU时间和Disk空间的,SQL Server必须记录相应数量的事务日志,而使用switch操作归档分区表 ...
- WebGIS项目中利用mysql控制点库进行千万条数据坐标转换时的分表分区优化方案
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1. 背景 项目中有1000万条历史案卷,为某地方坐标系数据,我们的真实 ...
- VMware下对虚拟机Ubuntu14系统所在分区sda1进行磁盘扩容
VMware下对虚拟机Ubuntu14系统所在分区sda1进行磁盘扩容 一般来说,在对虚拟机里的Ubuntu下的磁盘进行扩容时,都是添加新的分区,而并不是对其系统所在分区进行扩容,如在此链接中http ...
- SQL Server 批量主分区备份(Multiple Jobs)
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 案例分析(Case) 方案一(Solution One) 方案二(Solution Two) ...
- SQL Server 批量主分区备份(One Job)
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 案例分析(Case) 实现代码(SQL Codes) 主分区完整.差异还原(Primary B ...
随机推荐
- useJDBC4ColumnNameAndLabelSemantics设置后无效,怎么办?
连接的是DB2数据库, 在查询语句中有SELECT COLUMNNAME AS ALIASNAME FROM TABLE这样的结构时, 会报如下错误: Caused by: com.ibm.db2.j ...
- 【Qt开发】关于QWSServer
QWS Server QT Embeded应用没有来严格的区分server和client进程,如果一个QT进程的启动参数中有-qws,那么这个进程就具有server管理功能,被称为QWS server ...
- 编写shell脚本实现对虚拟机cpu、内存、磁盘监控机制
一.安装Vmware,并通过镜像安装centos7. 二.安装xshell(可以不装,可以直接在虚拟机中直接进行以下步骤) 三.安装mail 一般Linux发送报警邮件通过本地邮箱或外部邮箱服务器,这 ...
- 聊聊BIO、NIO与AIO的区别
题目:说一下BIO/AIO/NIO 有什么区别?及异步模式的用途和意义? 1F 说一说I/O首先来说一下什么是I/O? 在计算机系统中I/O就是输入(Input)和输出(Output)的意思,针对不同 ...
- (二)springMvc 入门
目录 配置前端控制器 servlet拦截方式 springMvc的配置文件 编写处理器类 配置自定义处理器 配置前端控制器 在 web.xml 配置 DispatcherServlet <!-- ...
- HDU 4578 线段树玄学算法?
Transformation 题目链接 http://acm.hdu.edu.cn/showproblem.php?pid=4578 Problem Description Yuanfang is p ...
- Dijstra_优先队列_前向星
Dijstra算法求最短路径 具体实现方式 设置源点,将源点从原集u{}中取出并放入新建集s{} 找出至源点最近的点q从原集取出放入新集s{} 由q点出发,更新所有由q点能到达的仍处于原集的点到源点的 ...
- Java手写简单Linkedlist一(包括增加,插入,查找,toString,remove功能)
@Java300 学习总结 一.自定义节点 LinkList底层为双向链表.特点为查询效率低,但增删效率高,线程不安全. 链表数据储存在节点,且每个节点有指向上个和下个节点的指针. 创建ggLinke ...
- 3.解决git不可用问题
升级gityum -y update git 配置阿里云yum源yum -y update nssyum -y update nss curl libcurl
- WPF 位图处理相关类
位图的存储方式 开始之前,先了解下位图的存储方式 位图的像素都分配有特定的位置和颜色值.每个像素的颜色信息由RGB组合或者灰度值表示,根据位深度,可将位图分为1.4.8.16.24及32位图像等.每个 ...