spark学习之Lambda架构日志分析流水线
单机运行
一、环境准备
Flume 1.6.0
Hadoop 2.6.0
Spark 1.6.0
Java version 1.8.0_73
Kafka 2.11-0.9.0.1
zookeeper 3.4.6
二、配置
spark和hadoop配置见()
kafka和zookeeper使用默认配置
1、kafka配置
启动
bin/kafka-server-start.sh config/server.properties
创建一个test的topic
bin/kafka-topics.sh --create --zookeeper vm: --replication-factor --partitions --topic test
2、flume配置文件,新建一个dh.conf文件,配置如下
其中发送的内容为apache-tomcat-8.0.32的访问日志
#define c1
agent1.channels.c1.type = memory
agent1.channels.c1.capacity =
agent1.channels.c1.transactionCapacity =
#define c1 end #define c2
agent1.channels.c2.type = memory
agent1.channels.c2.capacity =
agent1.channels.c2.transactionCapacity =
#define c2 end #define source monitor a file
agent1.sources.avro-s.type = exec
agent1.sources.avro-s.command = tail -f -n+ /usr/local/hong/apache-tomcat-8.0./logs/localhost_access_log.--.txt
agent1.sources.avro-s.channels = c1 c2
agent1.sources.avro-s.threads = # send to hadoop
agent1.sinks.log-hdfs.channel = c1
agent1.sinks.log-hdfs.type = hdfs
agent1.sinks.log-hdfs.hdfs.path = hdfs://vm:9000/flume
agent1.sinks.log-hdfs.hdfs.writeFormat = Text
agent1.sinks.log-hdfs.hdfs.fileType = DataStream
agent1.sinks.log-hdfs.hdfs.rollInterval =
agent1.sinks.log-hdfs.hdfs.rollSize =
agent1.sinks.log-hdfs.hdfs.rollCount =
agent1.sinks.log-hdfs.hdfs.batchSize =
agent1.sinks.log-hdfs.hdfs.txnEventMax =
agent1.sinks.log-hdfs.hdfs.callTimeout =
agent1.sinks.log-hdfs.hdfs.appendTimeout = #send to kafaka
agent1.sinks.log-sink2.type = org.apache.flume.sink.kafka.KafkaSink
agent1.sinks.log-sink2.topic = test
agent1.sinks.log-sink2.brokerList = vm:
agent1.sinks.log-sink2.requiredAcks =
agent1.sinks.log-sink2.batchSize =
agent1.sinks.log-sink2.channel = c2 # Finally, now that we've defined all of our components, tell
# agent1 which ones we want to activate.
agent1.channels = c1 c2
agent1.sources = avro-s
agent1.sinks = log-hdfs log-sink2
三、测试flume发送
1、启动hdfs
./start-dfs.sh
2、启动zookeeper
./zkServer.sh start
3、kafka的见上面
4、启动flume
flume-ng agent -c conf -f dh.conf -n agent1 -Dflume.root.logger=INFO,console
四、测试效果
运行kafka的consumer查看
bin/kafka-console-consumer.sh --zookeeper localhost: --topic test --from-beginning
可以看到如下内容说明kafka和flume的配置成功
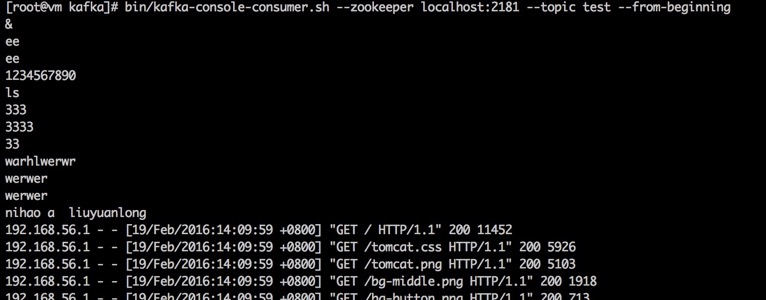
访问hdfs查看如果/flume可以下载文件进行查看验证hdfs发送是否成功
spark学习之Lambda架构日志分析流水线的更多相关文章
- spark SQL学习(综合案例-日志分析)
日志分析 scala> import org.apache.spark.sql.types._ scala> import org.apache.spark.sql.Row scala&g ...
- Hadoop学习笔记—20.网站日志分析项目案例(一)项目介绍
网站日志分析项目案例(一)项目介绍:当前页面 网站日志分析项目案例(二)数据清洗:http://www.cnblogs.com/edisonchou/p/4458219.html 网站日志分析项目案例 ...
- Hadoop学习笔记—20.网站日志分析项目案例(三)统计分析
网站日志分析项目案例(一)项目介绍:http://www.cnblogs.com/edisonchou/p/4449082.html 网站日志分析项目案例(二)数据清洗:http://www.cnbl ...
- Hadoop学习笔记—20.网站日志分析项目案例
1.1 项目来源 本次要实践的数据日志来源于国内某技术学习论坛,该论坛由某培训机构主办,汇聚了众多技术学习者,每天都有人发帖.回帖,如图1所示. 图1 项目来源网站-技术学习论坛 本次实践的目的就在于 ...
- Hadoop学习笔记—20.网站日志分析项目案例(二)数据清洗
网站日志分析项目案例(一)项目介绍:http://www.cnblogs.com/edisonchou/p/4449082.html 网站日志分析项目案例(二)数据清洗:当前页面 网站日志分析项目案例 ...
- 【Spark】通过Spark实现点击流日志分析
文章目录 数据大致内容及格式 统计PV(PageViews) 统计UV(Unique Visitor) 求取TopN 数据大致内容及格式 194.237.142.21 - - [18/Sep/2013 ...
- Spark学习之Spark调优与调试(7)
Spark学习之Spark调优与调试(7) 1. 对Spark进行调优与调试通常需要修改Spark应用运行时配置的选项. 当创建一个SparkContext时就会创建一个SparkConf实例. 2. ...
- 架构之ELK日志分析系统
ELK多种架构及优劣 既然要谈ELK在大数据运维系统中的应用,那么ELK架构就不得不谈.本章节引出四种笔者曾经用过的ELK架构,并讨论各种架构所适合的场景和优劣供大家参考. 先大致介绍ELK组件.EL ...
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
随机推荐
- oracle口令文件在windows和linux系统下的命名和位置
分类: Oracle 1.windows系统下 oracle口令文件在:$ORACLE_HOME/database目录下: 命名规则为:PWD$SID.ora 2.linux系统下 oracl ...
- BOM问题
在php编写中,很多人喜欢用notepad editplus 等等在windows下编写程序, 这就很容易出现一个问题,那就是文件签名的东西--BOM!所谓BOM,全称是Byte Order Mark ...
- Android性能优化-电量优化
前言 电量优化,这个名词在传统PC时代,我们基本很少听见.然而到了诺基亚时代,我们也同样很少关注.直到了移动互联的智能机时代.电量优化才被慢慢的重视起来.可能的原因如下: 移动设备,不能一直使用电源供 ...
- SQL-W3School-基础:SQL 语法
ylbtech-SQL-W3School-基础:SQL 语法 1.返回顶部 1. 数据库表 一个数据库通常包含一个或多个表.每个表由一个名字标识(例如“客户”或者“订单”).表包含带有数据的记录(行) ...
- HttpURLConnection 多线程下载
影响下载的速度 * 宽带的带宽 * 服务器的限制 * 服务器的资源固定,开启的线程越多抢占的资源就越多 import java.io.InputStream; import java.io.Rando ...
- 【转】APIJSON,让接口见鬼去吧!
我: APIJSON,让接口和文档见鬼去吧! https://github.com/TommyLemon/APIJSON 服务端: 什么鬼? 客户端: APIJSON是啥? 我: APIJSON是一种 ...
- Nginx知识
OpenResty最佳实践->location匹配规则传说中图片防盗链的爱恨情仇
- DPDK 网络加速在 NFV 中的应用
目录 文章目录 目录 前文列表 传统内核协议栈的数据转发性能瓶颈是什么? DPDK DPDK 基本技术 DPDK 架构 DPDK 核心组件 应用 NUMA 亲和性技术减少跨 NUMA 内存访问 应用 ...
- 关于Server2008 R2日志的查看
Server 2008 r2通过 系统事件查看器 分析日志: 查看 系统 事件: 事件ID号: 审计目录服务访问 4934 - Active Directory 对象的属性被复制 4935 -复制失败 ...
- Oracle 本地创建多个实例并创建多个监听(只能在服务端弄,不可在客户端)
注意:监听必须在客户端创建,在客户端创建,会报错. 1.创建监听 通过 Net Configuration Assistant 创建监听,设置端口: 注意:此监听创建完后,服务列表里面并没有此服务的 ...