【Python】简单实现爬取小说《天龙八部》,并在页面本地访问
背景
很多人说学习爬虫是提升自己的一个非常好的方法,所以有了第一次使用爬虫,水平有限,依葫芦画瓢,主要作为学习的记录。
思路
- 使用python的requests模块获取页面信息
- 通过re模块(正则表达式)取出需要的内容(小说标题,正文)
- 通过MysqlDB模块入库
- 使用webpy模块生成访问页面
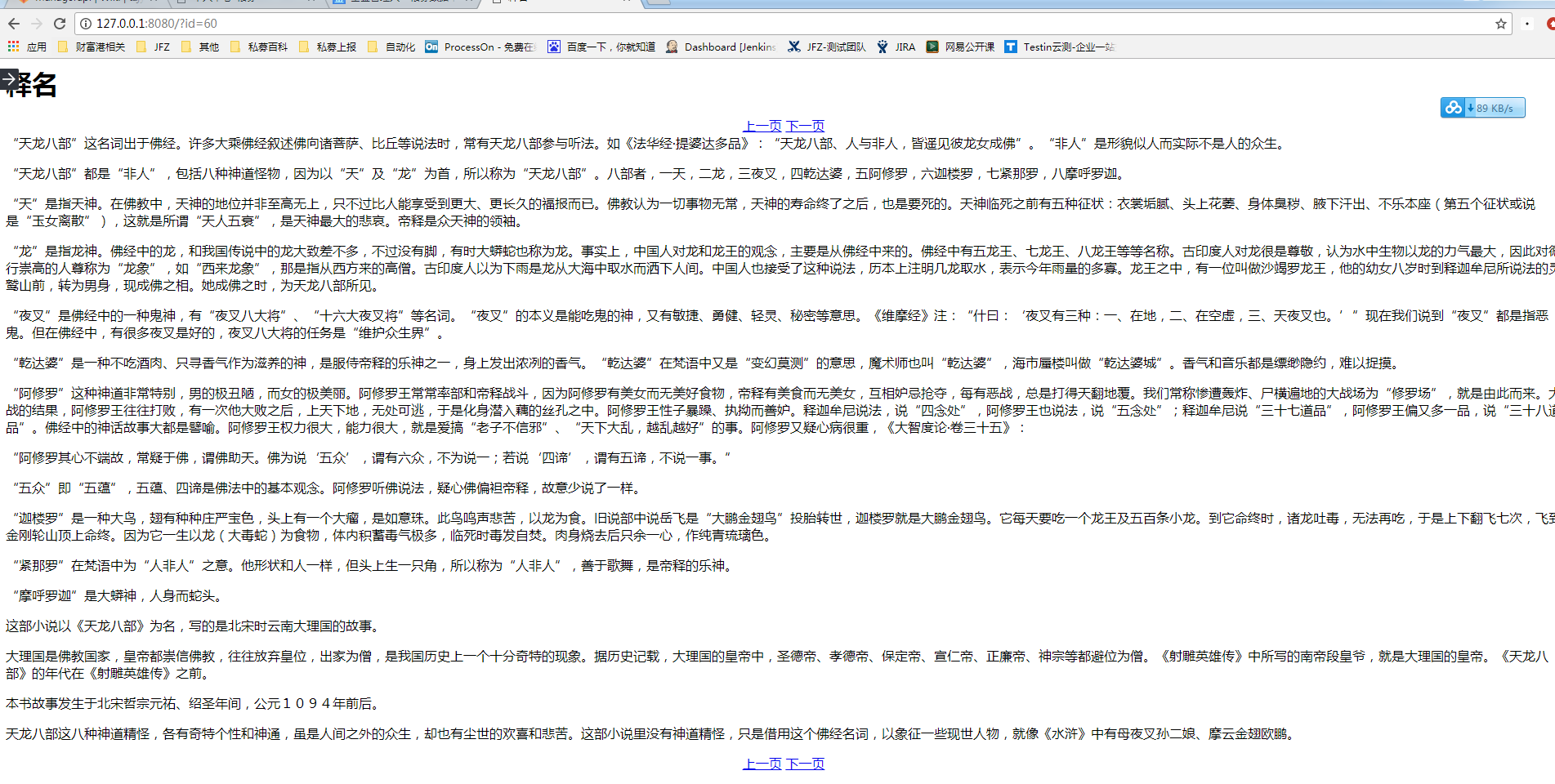
最终的效果图
下面是效果图,简单实现了点击上一页、下一页翻页的功能:
目录结构
目录结构如下:
D:\PROJECT\SPIDER
│ fiction_spider.py
│ webapp.py
│
└─template
index.html
爬取信息及入库示例代码
#coding:utf-8#fiction_spider.py
import requests
import re
import MySQLdb
def get_title():
html = requests.get('http://www.jinyongwang.com/tian/').content
rem = r'<li><a href="(.*?)">(.*?)</a>'
return re.findall(rem,html)
def get_content(url):
html = requests.get('http://www.jinyongwang.com/'+url).content
#print html
matchs_p = r'<p>(.*?)</p><script.*?'
data = re.findall(matchs_p, html)
return data[0]
if __name__ == '__main__':
a = MySQLdb.connect(host='10.1.*.*', port=3306, user='user', passwd='passwd', db='testdb', charset='utf8')
for i in get_title():
cur = a.cursor()
print i[1]
print i[0]
sqli = 'INSERT INTO `fiction` (`title`, `content`) VALUES ("%s","%s" )'%(i[1],get_content(i[0]))
cur.execute(sqli)
cur.close()
a.commit()
a.close()
生成访问页面示例代码
#coding:utf-8#webapp.py
import web
import re
urls = ('/(.*)','Index')
db = web.database(dbn = 'mysql',host='10.1.*.*', port=3306, user='user', passwd='passwd', db='testdb', charset='utf8')
render = web.template.render('template')
class Index:
def GET(self,html):
id = re.findall('(.*?).html',html)[0]
print id
data = db.query("select * from fiction where id=%s"%id)
return render.index(data[0],id)
if __name__ == '__main__':
web.application(urls,globals()).run()
页面访问的index.html内容如下:
$def with(data,s) <meta charset="utf-8"/> <title>$:data.title</title> <h1>$:data.title</h1> <div style="margin:0px auto;text-align:center;"> <a href="$:(int(s)-1).html">上一页</a> <a href="$:(int(s)+1).html">下一页</a> </div> $:data.content <br> <div style="margin:0px auto;text-align:center;"> <a href="$:(int(s)-1).html">上一页</a> <a href="$:(int(s)+1).html">下一页</a> </div>
保存到txt:
if __name__ == '__main__':
a = open(u'射雕**传.txt','w')
m = 0
for i in get_title():
#print i[1], get_content(i[0])
time.sleep(2)
data = i[1] + '\n' + '\n' + get_content(i[0]).replace('</p><p>','\n\n') + '\n\n' #在标题和内容之间插入换行符,将html中的<p>参数变成换行符
a.writelines(data)
m += 1
print u'正在爬取第%s段内容' % m
# if m >2:
# print u'正在爬取第%s段内容' % m
# break
a.close()
【Python】简单实现爬取小说《天龙八部》,并在页面本地访问的更多相关文章
- 初次尝试python爬虫,爬取小说网站的小说。
本次是小阿鹏,第一次通过python爬虫去爬一个小说网站的小说. 下面直接上菜. 1.首先我需要导入相应的包,这里我采用了第三方模块的架包,requests.requests是python实现的简单易 ...
- Python简单程序爬取天气信息,定时发邮件给朋友【高薪必学】
前段时间看到了这个博客.https://blog.csdn.net/weixin_45081575/article/details/102886718.他用了request模块,这不巧了么,正好我刚用 ...
- python简单爬虫爬取百度百科python词条网页
目标分析:目标:百度百科python词条相关词条网页 - 标题和简介 入口页:https://baike.baidu.com/item/Python/407313 URL格式: - 词条页面URL:/ ...
- 04 Python网络爬虫 <<爬取get/post请求的页面数据>>之requests模块
一. urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib ...
- python爬虫——爬取小说 | 探索白子画和花千骨的爱恨情仇(转载)
转载出处:药少敏 ,感谢原作者清晰的讲解思路! 下述代码是我通过自己互联网搜索和拜读完此篇文章之后写出的具有同样效果的爬虫代码: from bs4 import BeautifulSoup imp ...
- Scrapy爬取小说简单逻辑
Scrapy爬取小说简单逻辑 一 准备工作 1)安装Python 2)安装PIP 3)安装scrapy 4)安装pywin32 5)安装VCForPython27.exe ........... 具体 ...
- Python实战项目网络爬虫 之 爬取小说吧小说正文
本次实战项目适合,有一定Python语法知识的小白学员.本人也是根据一些网上的资料,自己摸索编写的内容.有不明白的童鞋,欢迎提问. 目的:爬取百度小说吧中的原创小说<猎奇师>部分小说内容 ...
- Golang 简单爬虫实现,爬取小说
为什么要使用Go写爬虫呢? 对于我而言,这仅仅是练习Golang的一种方式. 所以,我没有使用爬虫框架,虽然其很高效. 为什么我要写这篇文章? 将我在写爬虫时找到资料做一个总结,希望对于想使用Gola ...
- python之爬取小说
继上一篇爬取小说一念之间的第一章,这里将进一步展示如何爬取整篇小说 # -*- coding: utf- -*- import urllib.request import bs4 import re ...
随机推荐
- Pycharm建立web2py项目并简单连接MySQL数据库
引言 web2py是一种免费的,开源的web开发框架,用于敏捷地开发安全的,数据库驱动的web应用:web2p采用Python语言编写,并且可以使用Python编程.web2py是一个完整的堆栈框架, ...
- python中的抽象方法
python中的抽象方法 父类要限制1.子类必须有父类的方法2.子类实现的方法必须跟父类的方法的名字一样 import abc class A(metaclass=abc.ABCMeta): @abc ...
- celery-rabbitmq 安装部署
一:Python安装 1.下载python3源码 wget https://www.python.org/ftp/python/3.5.0/Python-3.5.0.tgz 2.解压 tar xf P ...
- Apache http server linux 安装过程说明
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/sundenskyqq/article/details/24733923 PS:Apache http ...
- java-mybaits-00501-案例-映射分析-订单商品数据模型
1.数据模型分析思路 1.每张表记录的数据内容 分模块对每张表记录的内容进行熟悉,相当 于你学习系统 需求(功能)的过程. 2.每张表重要的字段设置 非空字段.外键 ...
- beego——日志处理
这是一个用来处理日志的库,它的设计思路来自于 database/sql,目前支持的引擎有 file.console.net.smtp,可以通过如下方式进行安装: go get github.com/a ...
- Linux系统——特殊符号、通配符及正则表达式
特殊符号 | 管道符号,将管道符左边的命令的执行结果以字符串的形式通过 管道符传送到管道符右边命令末尾,作为管道符右边命令的执行 范围 > 输出重定向 >> 追加输出重定向 < ...
- Tornado 自定义Form,session实现方法
一. 自定义Tornado 验证模块 我们知道,平时在登陆某个网站或软件时,网站对于你输入的内容是有要求的,并且会对你输入的错误内容有提示,对于Django这种大而全的web框架,是提供了form表单 ...
- linux meta 18.0.1 系统安装nodejs
前置条件是:需要准备sudo apt-get 命令 第一步: 执行命令sudo apt-get install nodejs 即可安装, 之后可使用node -v 查看版本node 版本号 第二步: ...
- 前端虚拟接口mockjs的使用
最近在学习VueJS,也进一步学习了ES6,看了一遍之后,难免手痒,所以想仿写点什么,但是数据是个问题,你总不能写个分页,写个轮播吧,但是在公司做自己的东西找后台要接口也不那么像回事,怎么办呢? 无意 ...