【Network Architecture】Densely Connected Convolutional Networks 论文解析
目录
0. Paper link
DenseNet
另外,关于DenseNet需要内存优化等,但我目前还看不懂。。先mark一下,之后再去学习:传送门
1. Overview
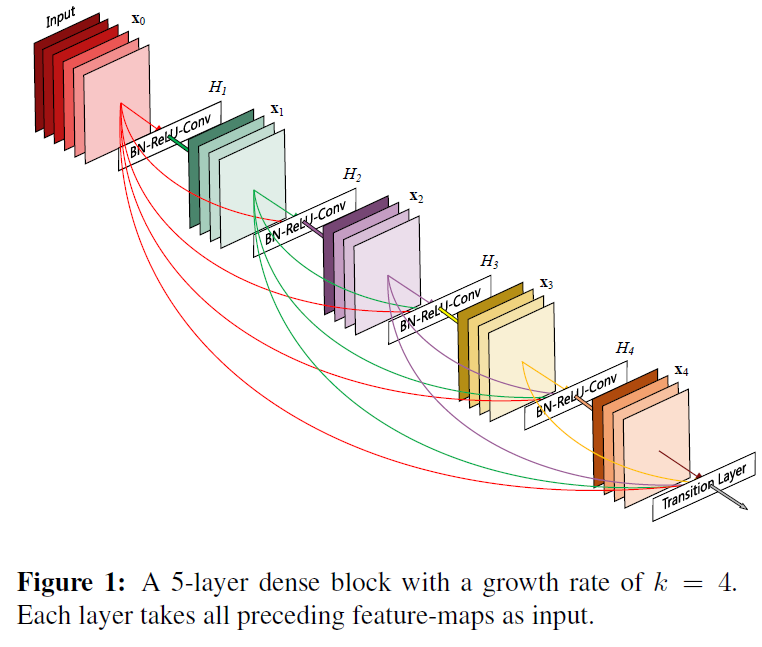
文章开篇提到了如果在靠近输入与输出的层之间存在短连接(shorter connections),可以训练更深、更准确、更有效的卷积网络,DenseNet利用了这个性质,每层都与之前所有的层进行连接,即之前所有层的feature map都作为这一层的输入。DenseNet有减少梯度消失,增强特征传递,鼓励特征重利用同时极大的减少了参数的数量。在很多任务上达到了state-of-the-art.
另外DenseNet并不是像ResNet那样在传入下一层之前把特征进行相加,如同GoogLeNet一样他把feature进行融合,因此\(l^{th}\)有\(l\)个输入包括前面所有的卷积块(convolutional blocks), 另外虽然叫DenseNet,但是他比传统的卷及网络需要更少的参数,因为他没有必要重新学习多余的特征图(stochastic ResNet证明ResNet其实有很多没有用的层数),DenseNet层很窄(例如每一层有12个滤波器),仅仅增加小数量的特征图到网络的“集体知识”(collective knowledge),并且保持这些特征图不变——最后的分类器基于网络中的所有特征图进行预测。
除了具有更好的参数利用率,DenseNets还有一个优点是它改善了网络中信息和梯度的传递,这就让网络更容易训练。每一层都可以直接利用损失函数的梯度以及最开始的输入信息,相当于是一种隐形的深度监督(implicit deep supervision)。这有助于训练更深的网络。此外,作者还发现稠密连接有正则化的作用,在更少训练集的任务中可以降低过拟合。
文章构建了如图上图的“dense block”每一个block内部feature size是相同的, 在中间的transition layer进行feature size的改变与传递。同时还设置了growth rate来调节网络的size。
感觉DenseNet充分的利用了feature之间的fusing,其实在看完ResNet的时候,我就这种想法,为什么ResNet大多数shortcut只是跨过2-3层呢,作者提到实验这些效果最好,他实验的range是多少呢?为什么不能多跨过几个,让模型fuse的更多呢,当时觉得硬性规定shortcut的范围并不是很好,感觉至少要学习一个参数去学习具体应该多少,每一层都去学习一个参数或许更好。而DenseNet则直接把所有的feature融合在一起,达到了一个所有feature作为一个“大feature”,结合GoogLeNet的一些思想,这个模型的提出并不难理解的,难得往往是第一个提出来的思想,比如AlexNet,现在也忘不了第一次见到ResNet的兴奋感与新奇感,也让我爱上了算法,找到了当初ACM的感觉(废话说多了)。
2. DenseNet Architecture
设\(H_{l}(·)\)为一个非线性转化(transformation),\(H_{l}(·)\)可以是BN层,ReLU,poolinghuozhe Conv的一个组合function,设一共有\(L\)层,\(l^{th}\)层的输出为\(x_{l}\)
2.1 Analogy to ResNet
ResNet的形式如下:
\[
X_{l} = H_{l}(X_{l-1}) + X_{l-1}
\]
很显然他是把\(l-1\)层的输出与残差映射的值相加起来,作者提到这可能影响到信息在网络中的流动。
DenseNet的形式如下:
\[
X_l = H_l([X_0, X_1, .....X_{l-1}])
\]
即\(l\)层的输入是0到\(l-1\)层的输出串联起来,实际操作中会把前\(l-1\)层的输入放进一个单独的张量中(tensor)
2.2 Composite function
在DenseNet中,定义\(H_{l}(·)\)为一个BN层后面接着ReLU层和一个3 × 3卷积的复合型函数
2.3 Dense block and Transition layer
很容易发现如果某一层的前\(l-1\)层的向量size不同,就无法拼接起来,因此受GoogLeNet的启发,把densely connected的部分组成一个dense block,在两个dense block中间引入transition layer,用来卷积与池化。在文章实验中transition layer包括一个BN层和1 × 1卷积层在紧接着一个2×2 average pooling layer。
2.4 Growth rate
如果\(H_l\)产生\(k\)个feature maps, 那么\(l^{th}\)有 \(k_0 + k×(l-1)\)层input feature maps,其中\(k_0\)是输入层的channels,DenseNet的一个很好的优点就是DenseNet可以变得很窄,比如\(k = 12\),把\(k\)作为一个超参数,叫做\(growth\ rate\),文章实验证明了很小的\(k\)也可以获得很多state-of-the-art的结果。
作者把这一部分进行了解析,每一层都接收之前所有层的feature,相当于获得了“集体知识(collective knowledge)”,作者提出把feature maps看做一个网络的总体阶段(global state),每一层贡献自己k个feature maps给这个阶段,growth rate决定了每层贡献多少新的信息给global state。
2.5 Bottleneck layers
尽管每层只产生k个feature maps,但是把之前所有层都加起来还是很多的,因此引入一个1 × 1的\(bottleneck layers\)在每个3 × 3卷积之前来减少输入的feature maps,文章中给出了非常适合DenseNet的bottleneck layer: BN-ReLU-Conv(1 × 1)-BN-ReLU-Conv(3 × 3),把这种形式的\(H_l\)表示为DenseNet-B,在实验中,让每个1 × 1 卷积产生4k个feature maps。
2.6 Compression
如果一个dense block 包含m个feature maps, 让紧接着的transition layer 产生\([\theta m]\)个 output feature-maps,其中\(0< \theta \leq 1\)代表压缩因子(compression factor),把\(\theta < 1\)的DenseNet看作DenseNet-C,把同时带有bottleneck layer与compression factor < 1的DenseNet称为DenseNet-BC.
2.7 Global Network Architecture
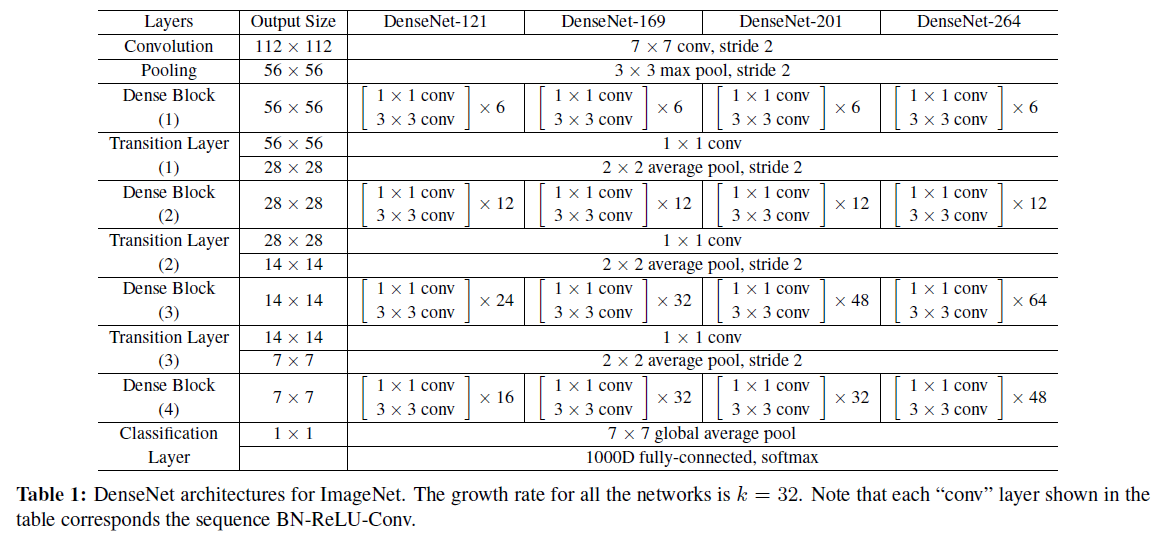
一个整体的结构图:

网络参数:(注意Conv代表BN-ReLU-Conv)
3. Experiments
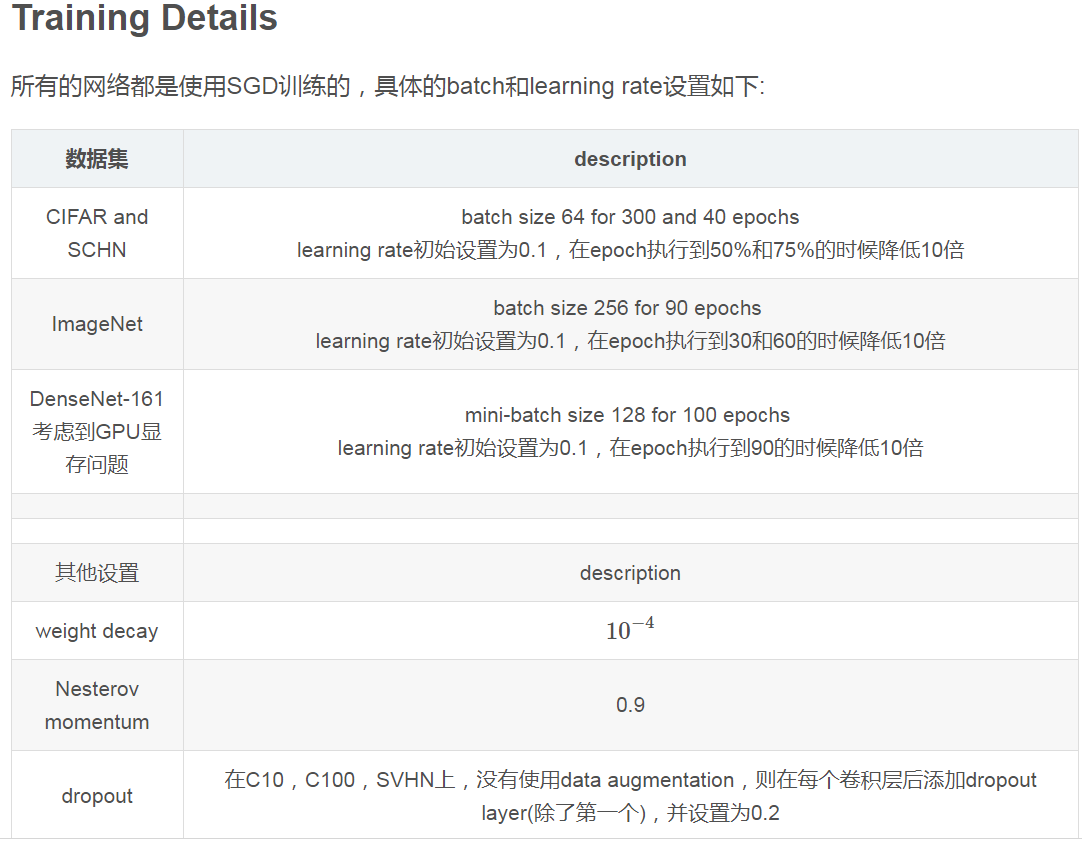
在某篇博客摘取了一个网络训练参数设置,同时这篇博客讲解的也不错
DenseNet在CIFAR与SVHN数据集上与各种主流网络的参数与错误率对比:

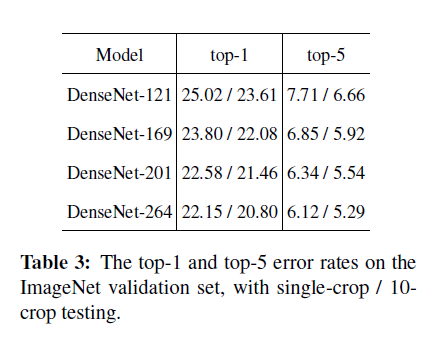
DenseNet在ImageNet 验证集上1-crop / 10-crop对比:
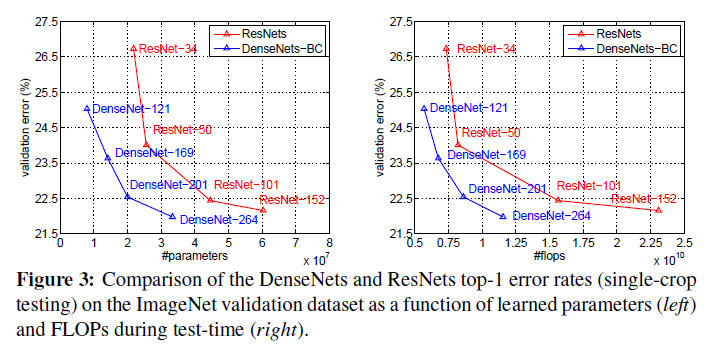
DenseNet在ImageNet 验证集上与ResNet控制变量对比:
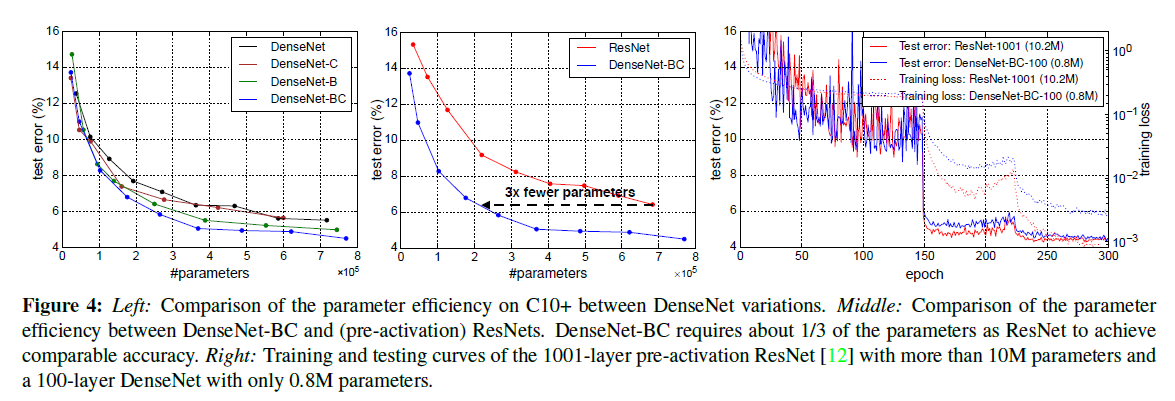
DenseNet在C10+ 验证集上与ResNet控制变量对比:
4. Discussion
隐含的深度监督(implicit deep supervision)。稠密卷积网络可以提升准确率的一个解释是,由于更短的连接,每一层都可以从损失函数中获得监督信息。可以将DenseNets理解为一种“深度监督”(deep supervision)。深度监督的好处已经在之前的深度监督网络(DSN)中说明,该网络在每一隐含层都加了分类器,迫使中间层也学习判断特征(discriminative features)。
DensNets和深度监督网络相似:网络最后的分类器通过最多两个或三个过渡层为所有层都提供监督信息。然而,DenseNets的损失函数值和梯度不是很复杂,这是因为所有层之间共享了损失函数。
遵循这个简单的连接规则,DenseNets可以很自然的将自身映射(identity mappings)、深度监督(deep supervision)和深度多样化(diversified depth)结合在一起。
5. Memory
DenseNet 在训练时对内存消耗非常厉害。这个问题其实是算法实现不优带来的。当前的深度学习框架对 DenseNet 的密集连接没有很好的支持,我们只能借助于反复的拼接(Concatenation)操作,将之前层的输出与当前层的输出拼接在一起,然后传给下一层。对于大多数框架(如 Torch 和 TensorFlow),每次拼接操作都会开辟新的内存来保存拼接后的特征。这样就导致一个 L 层的网络,要消耗相当于 L(L+1)/2 层网络的内存(第 l 层的输出在内存里被存了 (L-l+1) 份)。
解决这个问题的思路其实并不难,我们只需要预先分配一块缓存,供网络中所有的拼接层(Concatenation Layer)共享使用,这样
DenseNet 对内存的消耗便从平方级别降到了线性级别。在梯度反传过程中,我们再把相应卷积层的输出复制到该缓存,就可以重构每一层的输入特征,进而计算梯度。当然网络中由于 Batch Normalization 层的存在,实现起来还有一些需要注意的细节。
【Network Architecture】Densely Connected Convolutional Networks 论文解析的更多相关文章
- Densely Connected Convolutional Networks 论文阅读
毕设终于告一段落,传统方法的视觉做得我整个人都很奔溃,终于结束,可以看些搁置很久的一些论文了,嘤嘤嘤 Densely Connected Convolutional Networks 其实很早就出来了 ...
- 深度学习论文翻译解析(十五):Densely Connected Convolutional Networks
论文标题:Densely Connected Convolutional Networks 论文作者:Gao Huang Zhuang Liu Laurens van der Maaten Kili ...
- Deep Learning 33:读论文“Densely Connected Convolutional Networks”-------DenseNet 简单理解
一.读前说明 1.论文"Densely Connected Convolutional Networks"是现在为止效果最好的CNN架构,比Resnet还好,有必要学习一下它为什么 ...
- 【Semantic Segmentation】 Instance-sensitive Fully Convolutional Networks论文解析(转)
这篇文章比较简单,但还是不想写overview,转自: https://blog.csdn.net/zimenglan_sysu/article/details/52451098 另外,读这篇pape ...
- Paper | Densely Connected Convolutional Networks
目录 黄高老师190919在北航的报告听后感 故事背景 网络结构 Dense block DenseNet 过渡层 成长率 瓶颈层 细节 实验 发表在2017 CVPR. 摘要 Recent work ...
- Densely Connected Convolutional Networks(緊密相連卷積網絡)
- Dense blocks where each layer is connected to every other layer in feedforward fashion(緊密塊是指每一個層與每 ...
- DenseNet——Densely Connected Convolutional Networks
1. 摘要 传统的 L 层神经网络只有 L 个连接,DenseNet 的结构则有 L(L+1)/2 个连接,每一层都和前面的所有层进行连接,所以称之为密集连接的网络. 针对每一层网络,其前面所有层的特 ...
- 【文献阅读】Densely Connected Convolutional Networks-best paper-CVPR-2017
Densely Connected Convolutional Networks,CVPR-2017-best paper之一(共两篇,另外一篇是apple关于GAN的paper),早在去年八月 De ...
- 论文笔记:ReNet: A Recurrent Neural Network Based Alternative to Convolutional Networks
ReNet: A Recurrent Neural Network Based Alternative to Convolutional Networks2018-03-05 11:13:05 ...
随机推荐
- LeetCode—Longest Consecutive Sequence
题目描述: Given an unsorted array of integers, find the length of the longest consecutive elements seque ...
- mysql 约束条件 auto_increment 自动增长 修改自增字段起始值
创建一张表 t20 mysql) ); Query OK, rows affected (0.01 sec) mysql> desc t20; +-------+----------+----- ...
- 赵雅智_ListView_ArrayAdapter
ArrayAdapter六种构造方法的作用 ArrayAdapter<T>(Context context, int textViewResourceId); 上下文,布局文件 Array ...
- Java-小技巧-004-jdk时间,jdk8时间,joda,calendar,获取当前时间前一周、前一月、前一年的时间
1.推荐使用java8 localdate等 线程安全 支持较好 地址 2.joda 一.简述 查看SampleDateFormat源码,叙述有: * Date formats are not syn ...
- robotFramework_ride_python2_Wxpython测试环境搭建
(提示:我的安装版本是robotFramework3.0+ride1.5+python2.7+wxpython2.8,至于wxpython3.0下ride安装打不开的问题我还没找到原因,建议刚开始先不 ...
- index full scan和index fast full scan区别
触发条件:只需要从索引中就可以取出所需要的结果集,此时就会走索引全扫描 Full Index Scan 按照数据的逻辑顺序读取数据块,会发生单块读事件, Fast Full Index Scan ...
- Oracle DB 使用RMAN将数据库移植到ASM存储区
1. 完全关闭数据库. 2. 关闭数据库并修改服务器参数文件,以使用Oracle Managed Files (OMF). 3. 编辑并执行以下RMAN 脚本: STARTUP NOMOUNT; RE ...
- string与CString对比
string是标准C++库中的字符串类,CString是在Windows开发环境下常用的字符串类,CString目前已从MFC中分离出来可以单独使用,只需包含atlstr.h即可. 相比string, ...
- C# 使用 Windows API 发送文件到打印机
最近需要做一个打印的功能,于是在网上找到了这么一个方法. [StructLayout(LayoutKind.Sequential, CharSet = CharSet.Ansi)] public cl ...
- win8.1 设置默认输入法为英文
win8.1中文版 输入法默认为微软拼音且为中文,此事在使用类似cmd就很不方便了,这里我们只需要将输入法设置为 “允许我为每个应用窗口设置不同的输入法”即可,操作如下: