python kd树 搜索 代码
kd树就是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构,可以运用在k近邻法中,实现快速k近邻搜索。构造kd树相当于不断地用垂直于坐标轴的超平面将k维空间切分,依次选择坐标轴对空间进行切分,选择训练实例点在选定坐标轴上的中位数为切分点。具体kd树的原理可以参考kd树的原理。
代码是参考《统计学习方法》k近邻 kd树的python实现得到
首先创建一个类,用于表示树的节点,包括:该节点的值,用于划分左右子树的切分轴,左子树,右子树
class decisionnode:
def __init__(self,value=None,col=None,rb=None,lb=None):
self.value=value
self.col=col
self.rb=rb
self.lb=lb
切分点为坐标轴上的中值,下面代码求得一个序列的中值
def median(x):
n=len(x)
x=list(x)
x_order=sorted(x)
return x_order[n//2],x.index(x_order[n//2])
然后就可以构造一颗kd树,左子树小于切分点,右子树大于切分点,data是输入的数据
def buildtree(x,j=0):
rb=[]
lb=[]
m,n=x.shape
if m==0: return None
edge,row=median(x[:,j].copy())
for i in range(m):
if x[i][j]>edge:
rb.append(i)
if x[i][j]<edge:
lb.append(i)
rb_x=x[rb,:]
lb_x=x[lb,:]
rightBranch=buildtree(rb_x,(j+1)%n)
leftBranch=buildtree(lb_x,(j+1)%n)
return decisionnode(x[row,:],j,rightBranch,leftBranch)
接下来是树的搜索过程,可以用下图表示树的搜索过程,具体过程可以参考kd树的原理。
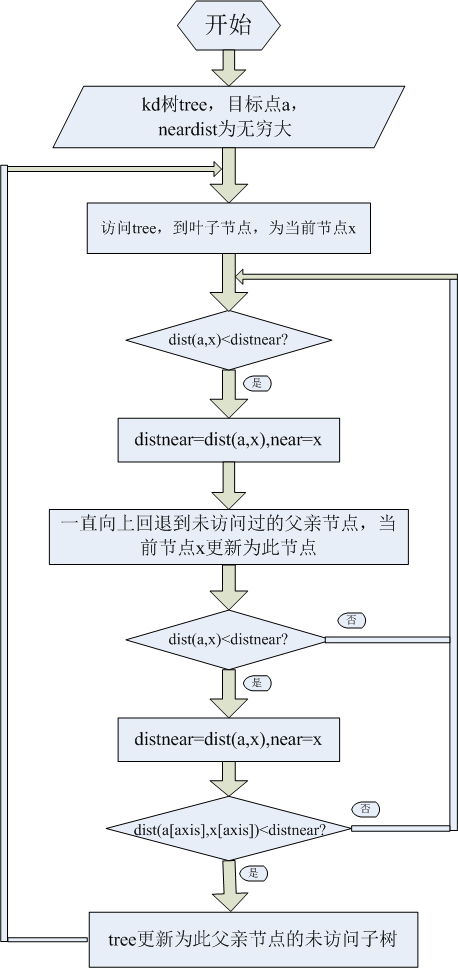
代码如下:
#搜索树:nearestPoint,nearestValue均为全局变量
def traveltree(node,point):
global nearestPoint,nearestValue
if node==None: return
print(node.value)
print('---')
col=node.col
if point[col]>node.value[col]:
traveltree(node.rb,point)
if point[col]<node.value[col]:
traveltree(node.lb,point)
dis=dist(node.value,point)
print(dis)
if dis<nearestValue:
nearestPoint=node
nearestValue=dis
#print('nearestPoint,nearestValue' % (nearestPoint,nearestValue))
if node.rb!=None or node.lb!=None:
if abs(point[node.col] - node.value[node.col]) < nearestValue:
if point[node.col]<node.value[node.col]:
traveltree(node.rb,point)
if point[node.col]>node.value[node.col]:
traveltree(node.lb,point) def searchtree(tree,aim):
global nearestPoint,nearestValue
#nearestPoint=None
nearestValue=float('inf')
traveltree(tree,aim)
return nearestPoint def dist(x1, x2): #欧式距离的计算
return ((np.array(x1) - np.array(x2)) ** 2).sum() ** 0.5
完整代码在此处取
import numpy as np
from numpy import array
class decisionnode:
def __init__(self,value=None,col=None,rb=None,lb=None):
self.value=value
self.col=col
self.rb=rb
self.lb=lb #读取数据并将数据转换为矩阵形式
def readdata(filename):
data=open(filename).readlines()
x=[]
for line in data:
line=line.strip().split('\t')
x_i=[]
for num in line:
num=float(num)
x_i.append(num)
x.append(x_i)
x=array(x)
return x #求序列的中值
def median(x):
n=len(x)
x=list(x)
x_order=sorted(x)
return x_order[n//2],x.index(x_order[n//2]) #以j列的中值划分数据,左小右大,j=节点深度%列数
def buildtree(x,j=0):
rb=[]
lb=[]
m,n=x.shape
if m==0: return None
edge,row=median(x[:,j].copy())
for i in range(m):
if x[i][j]>edge:
rb.append(i)
if x[i][j]<edge:
lb.append(i)
rb_x=x[rb,:]
lb_x=x[lb,:]
rightBranch=buildtree(rb_x,(j+1)%n)
leftBranch=buildtree(lb_x,(j+1)%n)
return decisionnode(x[row,:],j,rightBranch,leftBranch) #搜索树:nearestPoint,nearestValue均为全局变量
def traveltree(node,point):
global nearestPoint,nearestValue
if node==None: return
print(node.value)
print('---')
col=node.col
if point[col]>node.value[col]:
traveltree(node.rb,point)
if point[col]<node.value[col]:
traveltree(node.lb,point)
dis=dist(node.value,point)
print(dis)
if dis<nearestValue:
nearestPoint=node
nearestValue=dis
#print('nearestPoint,nearestValue' % (nearestPoint,nearestValue))
if node.rb!=None or node.lb!=None:
if abs(point[node.col] - node.value[node.col]) < nearestValue:
if point[node.col]<node.value[node.col]:
traveltree(node.rb,point)
if point[node.col]>node.value[node.col]:
traveltree(node.lb,point) def searchtree(tree,aim):
global nearestPoint,nearestValue
#nearestPoint=None
nearestValue=float('inf')
traveltree(tree,aim)
return nearestPoint def dist(x1, x2): #欧式距离的计算
return ((np.array(x1) - np.array(x2)) ** 2).sum() ** 0.5
kdtree
python kd树 搜索 代码的更多相关文章
- kd树 求k近邻 python 代码
之前两篇随笔介绍了kd树的原理,并用python实现了kd树的构建和搜索,具体可以参考 kd树的原理 python kd树 搜索 代码 kd树常与knn算法联系在一起,knn算法通常要搜索k近邻, ...
- RobHess的SIFT代码解析之kd树
平台:win10 x64 +VS 2015专业版 +opencv-2.4.11 + gtk_-bundle_2.24.10_win32 主要参考:1.代码:RobHess的SIFT源码:SIFT+KD ...
- KNN算法与Kd树
最近邻法和k-近邻法 下面图片中只有三种豆,有三个豆是未知的种类,如何判定他们的种类? 提供一种思路,即:未知的豆离哪种豆最近就认为未知豆和该豆是同一种类.由此,我们引出最近邻算法的定义:为了判定未知 ...
- 从K近邻算法谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/v_july_v/article/details/8203674 ,感谢july的辛勤劳动 前言 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章 ...
- C# 通过KD树进行距离最近点的查找.
本文首先介绍Kd-Tree的构造方法,然后介绍Kd-Tree的搜索流程及代码实现,最后给出本人利用C#语言实现的二维KD树代码.这也是我自己动手实现的第一个树形的数据结构.理解上难免会有偏差,敬请各位 ...
- <转>从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/likika2012/article/details/39619687 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章待写:1.KD树:2.神经 ...
- 从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转载自:http://blog.csdn.net/v_july_v/article/details/8203674/ 从K近邻算法.距离度量谈到KD树.SIFT+BBF算法 前言 前两日,在微博上说: ...
- 02-17 kd树
目录 kd树 一.kd树学习目标 二.kd树引入 三.kd树详解 3.1 构造kd树 3.1.1 示例 3.2 kd树搜索 3.2.1 示例 四.kd树流程 4.1 输入 4.2 输出 4.3 流程 ...
- k临近法的实现:kd树
# coding:utf-8 import numpy as np import matplotlib.pyplot as plt T = [[2, 3], [5, 4], [9, 6], [4, 7 ...
随机推荐
- http://www.jb51.net/article/28619.htm
http://www.jb51.net/article/28619.htm js autocomplete 自动完成
- SaltStack应用grains和jinja模板-第四篇
目标需求 1.使用jinja模板让apache配置监听本地ip地址 2.了解grains的基本使用方法 说明:实验环境是在前面的第二篇和第三篇基础上完成 实现步骤 使用grains获取ip地址信息 使 ...
- svn的分支
svn的分支使用 新建一个项目的时候,选择建立自带trunk,branches和tags文件夹的. 其中trunk作为主开发. 有需要的时候,从trunk创建分支到对应的branches下面,新建分支 ...
- Java分支结构 - if...else/switch
Java分支结构 - if...else/switch 顺序结构只能顺序执行,不能进行判断和选择,因此需要分支结构. Java有两种分支结构: if语句 switch语句 if语句 一个if语句包含一 ...
- 转载:Mongodb start
Mongodb 操作 Start MongoDB The MongoDB instance stores its data files in the /var/lib/mongo and its lo ...
- anaconda的一些命令
先安装好TensorFlow. 1.安装sklearn 本安装方式是在anaconda prompt上用命令来更新 (1)激活TensorFlow:activate tensorflow (2)查看是 ...
- react 子组件改变父组件状态
class Father extends Component { construtor(props){ super(props); this.state={ ...
- Java中操作Redis
一.server端安装 1.下载 https://github.com/MSOpenTech/redis 可看到当前可下载版本:redis2.6 下载后的文件为: 解压后,选择当前64位win7系统对 ...
- java和python互相调用
java和python互相调用 作者:xuaijun 日期:2017.1.1 python作为一种脚本语言,大量用于测试用例和测试代码的编写,尤其适用于交互式业务场景.实际应用中,很多网管系统 ...
- laravel怎么获取到public路径
app_path() app_path函数返回app目录的绝对路径: $path = app_path(); 你还可以使用app_path函数为相对于app目录的给定文件生成绝对路径: $path = ...