关于 tf.nn.softmax_cross_entropy_with_logits 及 tf.clip_by_value
In order to train our model, we need to define what it means for the model to be good. Well, actually, in machine learning we typically define what it means for a model to be bad. We call this the cost, or the loss, and it represents how far off our model is from our desired outcome. We try to minimize that error, and the smaller the error margin, the better our model is.
One very common, very nice function to determine the loss of a model is called "cross-entropy." Cross-entropy arises from thinking about information compressing codes in information theory but it winds up being an important idea in lots of areas, from gambling to machine learning. It's defined as:
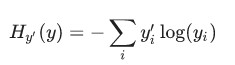
Where y is our predicted probability distribution, and y′ is the true distribution (the one-hot vector with the digit labels). In some rough sense, the cross-entropy is measuring how inefficient our predictions are for describing the truth. Going into more detail about cross-entropy is beyond the scope of this tutorial, but it's well worthunderstanding.
To implement cross-entropy we need to first add a new placeholder to input the correct answers:
y_ = tf.placeholder(tf.float32, [None, 10])
Then we can implement the cross-entropy function, 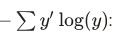
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
First, tf.log computes the logarithm of each element of y. Next, we multiply each element of y_ with the corresponding element of tf.log(y). Then tf.reduce_sum adds the elements in the second dimension of y, due to the reduction_indices=[1] parameter. Finally, tf.reduce_mean computes the mean over all the examples in the batch.
Note that in the source code, we don't use this formulation, because it is numerically unstable. Instead, we apply tf.nn.softmax_cross_entropy_with_logits on the unnormalized logits (e.g., we call softmax_cross_entropy_with_logits on tf.matmul(x, W) + b), because this more numerically stable function internally computes the softmax activation. In your code, consider usingtf.nn.softmax_cross_entropy_with_logits instead.
大意是:如果使用 cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
来计算交叉熵,则需要使用 tf.clip_by_value 来使某些求 log 的值,因为 log 会产生 none (如 log-3 ), 用它来限定不出现none,具体使用方式如下:
cross_entropy = -tf.reduce_sum(y_*tf.log(tf.clip_by_value(y_conv, 1e-10, 1.0)))但后来有人用了一个更好的方法来避免none:
cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv + 1e-10))具体参见 http://stackoverflow.com/questions/33712178/tensorflow-nan-bug 的讨论。
而如果直接用 tf.nn.softmax_cross_entropy_with_logits 则你再没有上面的后顾之忧了,它自动解决了上面的问题。
关于 tf.nn.softmax_cross_entropy_with_logits 及 tf.clip_by_value的更多相关文章
- 【TensorFlow】tf.nn.softmax_cross_entropy_with_logits的用法
在计算loss的时候,最常见的一句话就是 tf.nn.softmax_cross_entropy_with_logits ,那么它到底是怎么做的呢? 首先明确一点,loss是代价值,也就是我们要最小化 ...
- 深度学习原理与框架-Tensorflow卷积神经网络-卷积神经网络mnist分类 1.tf.nn.conv2d(卷积操作) 2.tf.nn.max_pool(最大池化操作) 3.tf.nn.dropout(执行dropout操作) 4.tf.nn.softmax_cross_entropy_with_logits(交叉熵损失) 5.tf.truncated_normal(两个标准差内的正态分布)
1. tf.nn.conv2d(x, w, strides=[1, 1, 1, 1], padding='SAME') # 对数据进行卷积操作 参数说明:x表示输入数据,w表示卷积核, stride ...
- [TensorFlow] tf.nn.softmax_cross_entropy_with_logits的用法
在计算loss的时候,最常见的一句话就是tf.nn.softmax_cross_entropy_with_logits,那么它到底是怎么做的呢? 首先明确一点,loss是代价值,也就是我们要最小化的值 ...
- tf.nn.softmax_cross_entropy_with_logits的用法
http://blog.csdn.net/mao_xiao_feng/article/details/53382790 计算loss的时候,最常见的一句话就是tf.nn.softmax_cross_e ...
- tf.nn.softmax & tf.nn.reduce_sum & tf.nn.softmax_cross_entropy_with_logits
tf.nn.softmax softmax是神经网络的最后一层将实数空间映射到概率空间的常用方法,公式如下: \[ softmax(x)_i=\frac{exp(x_i)}{\sum_jexp(x_j ...
- tf.nn.softmax_cross_entropy_with_logits()函数的使用方法
import tensorflow as tf labels = [[0.2,0.3,0.5], [0.1,0.6,0.3]]logits = [[2,0.5,1], [0.1,1,3]] a=tf. ...
- 1、求loss:tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits, labels, name=None))
1.求loss: tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits, labels, name=None)) 第一个参数log ...
- tf.nn.softmax_cross_entropy_with_logits 分类
tf.nn.softmax_cross_entropy_with_logits(logits, labels, name=None) 参数: logits:就是神经网络最后一层的输出,如果有batch ...
- 深度学习原理与框架-图像补全(原理与代码) 1.tf.nn.moments(求平均值和标准差) 2.tf.control_dependencies(先执行内部操作) 3.tf.cond(判别执行前或后函数) 4.tf.nn.atrous_conv2d 5.tf.nn.conv2d_transpose(反卷积) 7.tf.train.get_checkpoint_state(判断sess是否存在
1. tf.nn.moments(x, axes=[0, 1, 2]) # 对前三个维度求平均值和标准差,结果为最后一个维度,即对每个feature_map求平均值和标准差 参数说明:x为输入的fe ...
随机推荐
- (译)Getting Started——1.2.2 Desinging a User Interface(设计用户界面)
用户需要以最简单的方式与应用界面进行交互.应该从用户的角度出发设计页面,使得界面更高效.简捷和直接. storyboard以图形化的方式帮助你设计和实现界面.在设计和实现界面的过程中,你 ...
- Django1.6 +wsgi 部署到Apache2 的步骤。
网上很多教程都是关于1.6之前的版本,很多都不适用,经历告诉我们最靠谱的还是官方文档. 一个Demo例子: 以 python shell开发的方式部署没有问题,但当独立部署到Apache2的过程非常艰 ...
- CC1101 433无线模块,STM8串口透传
CC1101 433无线模块,STM8串口透传 原理图:http://download.csdn.net/detail/cp1300/7496509 下面是STM8程序 CC1101.C /*** ...
- 基于WebBrowser 的爬虫程序
WebBrowser的属性和事件 WebBrowser 如何跳转页面 web.Navigate(""); WebBrowser 如何循环跳转获取页面内容 bool loading ...
- yalmip + lpsolve + matlab 求解混合整数线性规划问题(MIP/MILP)
最近建立了一个网络流模型,是一个混合整数线性规划问题(模型中既有连续变量,又有整型变量).当要求解此模型的时候,发现matlab优化工具箱竟没有自带的可以求解这类问题的算法(只有bintprog求解器 ...
- 利用Java编写简单的WebService实例
使用Axis编写WebService比較简单,就我的理解,WebService的实现代码和编写Java代码事实上没有什么差别,主要是将哪些Java类公布为WebService. 以下是一个从编写測试样 ...
- c/c++中内存对齐完全理解
一,什么是内存对齐?内存对齐用来做什么? 所谓内存对齐,是为了让内存存取更有效率而采用的一种编译阶段优化内存存取的手段. 比如对于int x;(这里假设sizeof(int)==4),因为cpu对内存 ...
- 面试题思考:Java 8 / Java 7 为我们提供了什么新功能
Java 7 的7个新特性 1.对集合类的语言支持: 2.自动资源管理: 3.改进的通用实例创建类型推断: 4.数字字面量下划线支持: 5.switch中使用string: 6.二进制字面量: 7.简 ...
- boost::interprocess::shared_memory_object(1)(基本类型)
#include <iostream> #include <boost/interprocess/managed_shared_memory.hpp> struct pos2d ...
- Delphi xe7 android实现透明度可以调整的对话框
Delphi xe7 android实现透明度可以调整的对话框 Delphi xe7 android实现透明度可以调整的对话框 Delphi xe7 android实现透明度可以调整的对话框 要实现对 ...