(三)Solr——Solr的基本使用
1. Schema.xml
在schema.xml文件中,主要配置了solrcore的一些数据信息,包括Field和FieldType的定义等信息,在solr中,Field和FieldType都需要先定义后使用。

1.1 Filed(定义Field域)

- Name:指定域的名称
- Type:指定域的类型
- Indexed:是否索引
- Stored:是否存储
- Required:是否必须
- multiValued:是否多值,比如商品信息中,一个商品有多张图片,一个Field像存储多个值的话,必须将multiValued设置为true。
1.2 dynamicField(动态域)

- Name:指定动态域的命名规则
1.3 uniqueKey(指定唯一键)

其中的id是在Field标签中已经定义好的域名,而且该域要设置为required为true。
一个schema.xml文件中必须有且仅有一个唯一键
1.4 copyField(复制域)

- Source:要复制的源域的域名
- Dest:目标域的域名
由dest指的的目标域,必须设置multiValued为true。
1.5 FieldType(定义域的类型)
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
- Name:指定域类型的名称
- Class:指定该域类型对应的solr的类型
- Analyzer:指定分析器
- Type:index、query,分别指定搜索和索引时的分析器
- Tokenizer:指定分词器
- Filter:指定过滤器
2. 中文分词器(ikanalyzer)
第一步:将ikanalyzer的jar包拷贝到以下目录

第二步:将ikanalyzer的扩展词库的配置文件拷贝到 目录

第三步:配置FieldType

第四步:配置使用中文分词的Field

第五步:重启tomcat
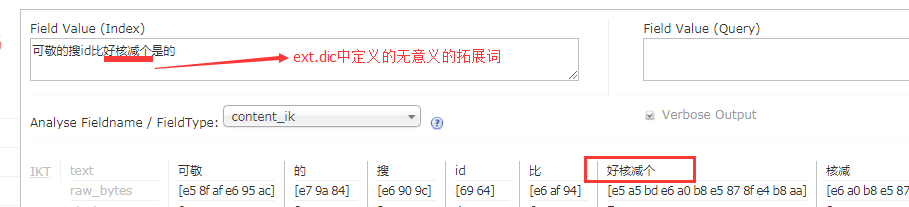
3. Dataimport(该插件可以将数据库中指定的sql语句的结果导入到solr索引库中)
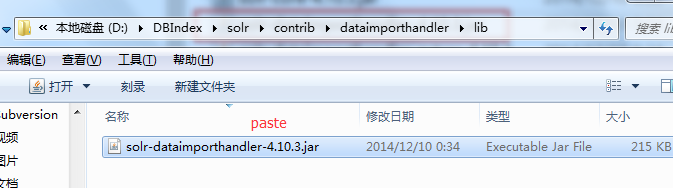
第一步:添加Dataimport的jar包
复制以下目录的jar包

添加到以下目录(lib目录需要新建)
修改solrconfig.xml文件,添加lib标签
<lib dir="${solr.install.dir:../..}/contrib/dataimporthandler/lib" regex=".*\.jar" />
将mysql的驱动包,复制到以下目录
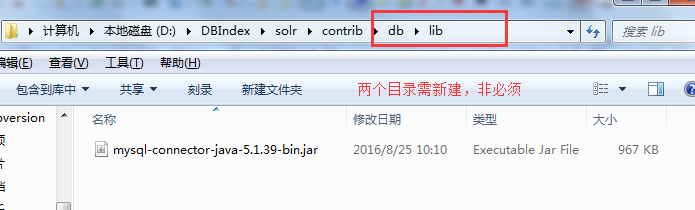
修改solrconfig.xml文件,添加lib标签
<lib dir="${solr.install.dir:../..}/contrib/db/lib" regex=".*\.jar" />
第二步:配置requestHandler
在solrconfig.xml中,添加一个dataimport的requestHandler

第三步:创建data-config.xml
在solrconfig.xml同级目录下,创建data-config.xml

第四步:重启tomcat

(三)Solr——Solr的基本使用的更多相关文章
- 三、Solr多核心及分词器(IK)配置
多核心的概念 多核心说白了就是多索引库.也可以理解为多个"数据库表" 说一下使用multicore的真实场景,比若说,产品搜索和会员信息搜索,不使用多核也没问题,这样带来的问题是 ...
- Solr系列三:solr索引详解(Schema介绍、字段定义详解、Schema API 介绍)
一.Schema介绍 1. Schema 是什么? Schema:模式,是集合/内核中字段的定义,让solr知道集合/内核包含哪些字段.字段的数据类型.字段该索引存储. 2. Schema 的定义方式 ...
- Solr学习总结(三)Solr web 管理后台
前面讲到了Solr的安装,按道理,这次应该讲讲.net与数据库的内容,C#如何操作Solr索引等.不过我还是想先讲一些基础的内容,比如solr查询参数如何使用,各个参数都代表什么意思? 还有solr ...
- solr特点三: 基于Solr实现排序定制化参考
排序实现有N种形式,最低成本.最快响应时间是目标 一份索引,支持N种排序策略并且在线互不干扰是要考虑的每一种实现,处理的场景是不同的,不要千篇一律 020排序,从索引到效果,有不少坑,这篇文章没有细说 ...
- Solr -- Solr Facet 1
一.Facet介绍 solr facet 是solr搜索的一大特色,facet不好翻译,有说是垂直搜索,有说是分片搜索,但都不是很好,还是懒得翻译了,就叫facet ,具体功能看下面的例子意会吧. 比 ...
- Solr 01 - 什么是Solr + Solr安装包目录结构说明
目录 1 Solr概述 1.1 Solr是什么 1.2 Solr与Lucene的区别 2 Solr文件说明 2.1 Solr的目录结构 2.2 其他常用概念说明 2.3 创建基础文件目录 2.4 so ...
- Solr -- Solr Facet 2
solr将以导航为目的的查询结果称为facet. 它并不会修改查询结果信息, 只是在查询结果上根据分类添加了count信息, 然后用户根据count信息做进一步的查询, 比如淘宝的查询列表中, 上面会 ...
- [solr]solr的安装
solr是什么? 翻译: SolrTM is the popular, blazing fast open source enterprise search platform from the Apa ...
- (二)Solr——Solr界面介绍
1. Dashboard 仪表盘,显示了该Solr实例开始启动运行的时间.版本.系统资源.jvm等信息. 2. Logging Solr运行日志信息 3. Cloud Cloud即SolrCloud, ...
随机推荐
- CXF浅析
CXF 框架支撑环境 CXF 框架是一种基于 Servlet 技术的 SOA 应用开发框架,要正常运行基于 CXF 应用框架开发的企业应用,除了 CXF 框架本身之外,还需要 JDK 和 Ser ...
- 【树形dp】The more, The Better
[HDU1561]The more, The Better Time Limit: 6000/2000 MS (Java/Others) Memory Limit: 32768/32768 K ...
- 【推导】【数学期望】Gym - 101237D - Short Enough Task
按照回文子串的奇偶分类讨论,分别计算其对答案的贡献,然后奇偶分别进行求和. 推导出来,化简一下……发现奇数也好,偶数也好,都可以拆成一个等比数列求和,以及一个可以错位相减的数列求和. 然后用高中数学知 ...
- 【数论】【Polya定理】poj1286 Necklace of Beads
Polya定理:设G={π1,π2,π3........πn}是X={a1,a2,a3.......an}上一个置换群,用m中颜色对X中的元素进行涂色,那么不同的涂色方案数为:1/|G|*(mC(π1 ...
- 【后缀自动机】【拓扑排序】【动态规划】hihocoder1457 后缀自动机四·重复旋律7
解题方法提示 小Hi:我们已经学习了后缀自动机,今天我们再来看这道有意思的题. 小Ho:好!这道题目让我们求的是若干的数字串所有不同子串的和. 小Hi:你能不能结合后缀自动机的性质来思考如何解决本题? ...
- NAND Flash大容量存储器K9F1G08U的坏块管理方法
转: http://www.360doc.com/content/11/0915/10/7715138_148381804.shtml 在进行数据存储的时候,我们需要保证数据的完整性,而NAND Fl ...
- Android显示GIF动画 GifView
android中显示gif动画原生态一般支持的不是很好,故找了一个开源的项目,现简单介绍如下: GifView 是一个为了解决android中现在没有直接显示gif的view,只能通过mediapla ...
- Synopsys EDA工具在LinuxMint 18(Ubuntu 16.04.2)安装注意事项
Synopsys家的工具官方对Linux发行版支持为RHEL 5/6/7及SUSE 12/13,对于2014版本的工具(DC.ICC.PT.VCS.HSPICE等).其实,在Debian系及衍生版本上 ...
- python爬虫之scrapy框架
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以 ...
- pymongo常见的高级用法
pymongo是python中基于mongodb数据库开发出来的,比mongoengine要高级一些,也要好用一些. 基本的增删查改就不说了 insert() delete() find() upda ...