HBase ProcedureV2 分析
Procedure V2, 是hbase1.1版本引入的一套fault-tolerant的执行multi-steps-job的框架, 目前主要用在Master中, 比如创建表,删除表等操作
新旧比较
下面比较0.94版本和1.25版本下的建表流程
0.94
0.94版本中,创建表是通过HBaseAdmin类,向Master发起一个异步的建表请求,然后不断的扫描meta表,直到从meta表中扫描到的表的region数目和预期的数据相同,即认为建表成功, 时序图如下:
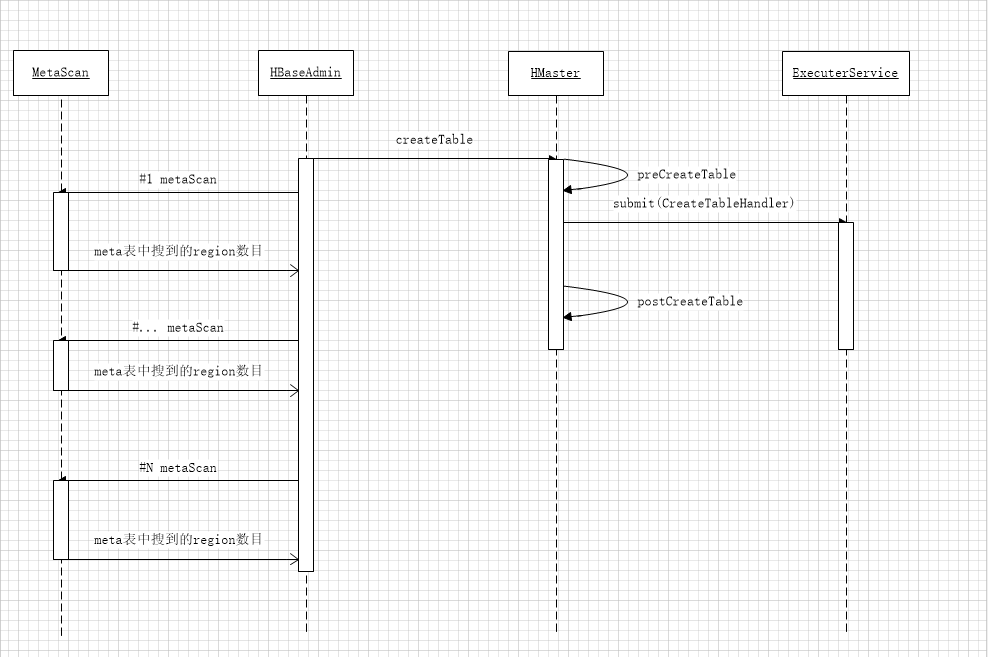
流程:
1. 从HBaseAdmin发起 createTable请求到master[异步请求]
2. Master做完基本检查后,如果有MasterCoprocessor,就调用coprocessor的preCreateTable做前置检查
3. 检查通过后,Master生成CreateTableHandler, 提交给ExecuterService服务去执行
3.1. hdfs的 hbaseroot/.tmp目录上创建TableDescriptor
3.2. hdfs的hbaseroot/.tmp目录上创建region及相关文件
3.3. 把tmp目录中创建好的表文件拷贝到hbaseroot目录下
3.4. 新增region信息到META表
3.5. 触发所有region的assignment,随机分配到集群alive的regionserver上
3. 6. zk上修改表的状态为TableState.ENABLED
4. HBaseAdmin在第1步完成后, 会通过MetaScan不断的去meta表查看所创建表的region数目是不是和预期的相等,如果是,建表成功,如果经过了一定的重试次数后(默认10*10=100次),依然失败,则抛出TableNotEnabledException异常
存在的问题:
1. 如果一切顺利还好,但是如果任意一步出现问题,则很难定位和修复,比如:
1. 3.3成功后,master宕机, 3.4还没有执行, 那么定位后,可以通过hbase hbck -fixMeta 工具做修复
2. 如果3.4部分成功, 就没有很好的工具做修复, 这时候就需要人工介入,去做回滚操作,然后再重新建表
1.2.5
procedure v2是在hbase1.1版本引入的特性,主要是为了解决之前的方案中存在的问题, 比如,任务意外中断后,中间状态需要人工接入, 难以追溯任务状态等问题, 用户可以选择是否开启procedure特性,如果不开启,就还是使用类似0.94版本的Handler机制.
Procedure有以下核心组件:

其中, ProcedureExecuter负责procedure的编排和运行, procedureStore用于持久化procedure的状态
Procedure 有以下状态:

每个Procedure都会经过这几个状态,每次状态的变化,都会通过ProcedureStore记录到WAL中
Procedure V2有以下几个核心接口类:
1. Procedure 代表一个任务的基础类, 主要包含两个接口方法:
a. execute
b. rollback
2. ProcedureStore 持久化Procedure状态的类, 机器宕机恢复后会通过ProcedureStore获取之前没有运行完的任务状态,并且继续执行
3. ProcedureExecutor 类似于ExecutorService, 用于执行procedure,同时也负责Procedure任务的恢复和rollback等操作, 复杂程度超过ExecutorService
使用Procedure v2的场景下,时序图如下:
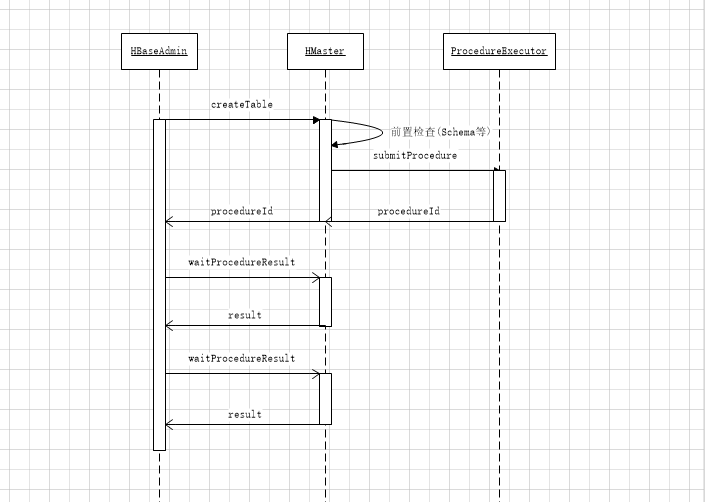
通过Procedure V2,可以将一个任务拆分成多个子Procedure, 具体的实现方式是, 父任务的execute返回多个Procedure子任务,这个时候, 父任务的状态变成Waiting, 并继续完成子任务,当所有子任务都成功后, 父任务继续执行
根据这个特性, hbase实现了一个StateMachineProcedure, 基于状态机, CreateTableProcedure被分成了多个状态:
enum CreateTableState {
CREATE_TABLE_PRE_OPERATION = 1;
CREATE_TABLE_WRITE_FS_LAYOUT = 2;
CREATE_TABLE_ADD_TO_META = 3;
CREATE_TABLE_ASSIGN_REGIONS = 4;
CREATE_TABLE_UPDATE_DESC_CACHE = 5;
CREATE_TABLE_POST_OPERATION = 6;
}
初始化状态下, 状态为CREATE_TABLE_PRE_OPERATION, 状态变化逻辑在ExecuteFromState中实现:
@Override
protected Flow executeFromState(final MasterProcedureEnv env, final CreateTableState state)
throws InterruptedException {
if (LOG.isTraceEnabled()) {
LOG.trace(this + " execute state=" + state);
}
try {
switch (state) {
case CREATE_TABLE_PRE_OPERATION:
// Verify if we can create the table
boolean exists = !prepareCreate(env);
ProcedurePrepareLatch.releaseLatch(syncLatch, this); if (exists) {
assert isFailed() : "the delete should have an exception here";
return Flow.NO_MORE_STATE;
} preCreate(env);
setNextState(CreateTableState.CREATE_TABLE_WRITE_FS_LAYOUT);
break;
case CREATE_TABLE_WRITE_FS_LAYOUT:
newRegions = createFsLayout(env, hTableDescriptor, newRegions);
setNextState(CreateTableState.CREATE_TABLE_ADD_TO_META);
break;
case CREATE_TABLE_ADD_TO_META:
newRegions = addTableToMeta(env, hTableDescriptor, newRegions);
setNextState(CreateTableState.CREATE_TABLE_ASSIGN_REGIONS);
break;
case CREATE_TABLE_ASSIGN_REGIONS:
assignRegions(env, getTableName(), newRegions);
setNextState(CreateTableState.CREATE_TABLE_UPDATE_DESC_CACHE);
break;
case CREATE_TABLE_UPDATE_DESC_CACHE:
updateTableDescCache(env, getTableName());
setNextState(CreateTableState.CREATE_TABLE_POST_OPERATION);
break;
case CREATE_TABLE_POST_OPERATION:
postCreate(env);
return Flow.NO_MORE_STATE;
default:
throw new UnsupportedOperationException("unhandled state=" + state);
}
} catch (HBaseException|IOException e) {
LOG.error("Error trying to create table=" + getTableName() + " state=" + state, e);
setFailure("master-create-table", e);
}
return Flow.HAS_MORE_STATE;
}
如果CreateTable过程中,在某一个状态下运行失败需要回滚, ProcedureExecutor会负责追溯回滚procedure的父Procedure,直到全部回滚; 如果Procedure执行或者回滚过程中出现宕机,Master在启动的时候,会启动ProcedureExecutor,从WAL中恢复出之前Procedure的状态;
ProcedureStore的实现
...未完待续
HBase ProcedureV2 分析的更多相关文章
- HBase源代码分析之MemStore的flush发起时机、推断条件等详情
前面的几篇文章.我们具体介绍了HBase中HRegion上MemStore的flsuh流程,以及HRegionServer上MemStore的flush处理流程.那么,flush究竟是在什么情况下触发 ...
- HBase源代码分析之HRegionServer上MemStore的flush处理流程(一)
在<HBase源代码分析之HRegion上MemStore的flsuh流程(一)>.<HBase源代码分析之HRegion上MemStore的flsuh流程(二)>等文中.我们 ...
- HBase源代码分析之HRegionServer上MemStore的flush处理流程(二)
继上篇文章<HBase源代码分析之HRegionServer上MemStore的flush处理流程(一)>遗留的问题之后,本文我们接着研究HRegionServer上MemStore的fl ...
- HBase源代码分析之MemStore的flush发起时机、推断条件等详情(二)
在<HBase源代码分析之MemStore的flush发起时机.推断条件等详情>一文中,我们具体介绍了MemStore flush的发起时机.推断条件等详情.主要是两类操作.一是会引起Me ...
- HBase源代码分析之HRegion上MemStore的flsuh流程(二)
继上篇<HBase源代码分析之HRegion上MemStore的flsuh流程(一)>之后.我们继续分析下HRegion上MemStore flush的核心方法internalFlushc ...
- 1、Hbase原理分析
一.Hbase介绍 1.1.对Hbase的认识 HBase作为面向列的数据库运行在HDFS之上,HDFS缺乏随机读写操作,HBase正是为此而出现. HBase参考 Google 的 Bigtable ...
- HBase源代码分析之HRegion上MemStore的flsuh流程(一)
了解HBase架构的用户应该知道,HBase是一种基于LSM模型的分布式数据库.LSM的全称是Log-Structured Merge-Trees.即日志-结构化合并-树. 相比于Oracle普通索引 ...
- HBase可用性分析与高可用实践
HBase作为一个分布式存储的数据库,它是如何保证可用性的呢?对于分布式系统的CAP问题,它是如何权衡的呢? 最重要的是,我们在生产实践中,又应该如何保证HBase服务的高可用呢? 下面我们来仔细分析 ...
- Hbase案例分析(二)
情景1:
随机推荐
- 【Miller-Rabin算法】
存个板子,应该是对的吧……没太试 http://www.cnblogs.com/Norlan/p/5350243.html Matrix67写的 根据wiki,取前9个素数当base的时候,long ...
- 【Trie图+DP】BZOJ1030[JSOI2007]-文本生成器
[题目大意] 给出单词总数和固定的文章长度M,求出至少包含其中一个单词的可能文章数量. [思路] 对于至少包含一个的类型,我们可以考虑补集.也就是等于[总的文章可能性总数-不包含任意一个单词的文章总数 ...
- JavaScript继承方式
我的上一篇随笔中写了有关原型继承的,下面介绍几种更加有用的. 借用构造函数 在解决原型中关于引用类型值所带来的问题,开发人员开始使用一种叫做借用构造函数. 基本思想: 在子类型构造函数的内部调用超类型 ...
- Java高级架构师(一)第37节:反向代理和动静分离的实现
http协议->server->location 输入http:locahost:80/ 进入百度的界面. 做负载转发测试.路径已经转发,可能一些协议已经屏蔽了,导致内容出不来. 关于负载 ...
- 《SQL Server企业级平台管理实践》读书笔记
http://www.cnblogs.com/zhijianliutang/category/277162.html
- Inno Setup自定义卸载文件名称的脚本
Inno Setup 支持在同一个目录中安装多个应用程序,所以根据安装的先后次序自动将卸载程序文件命名为 unins000.exe,unins001.exe,unins002.exe 等等.这是 IN ...
- selector简介
最近在学习java NIO,发现java nio selector 相对 channel ,buffer 这两个概念是比较难理解的 ,把学习理解的东西以文字的东西记录下来,就像从内存落地到硬盘,把内存 ...
- Android 通过URL scheme 实现点击浏览器中的URL链接,启动特定的App,并调转页面传递参数
点击浏览器中的URL链接,启动特定的App. 首先做成HTML的页面,页面内容格式如下: <a href="[scheme]://[host]/[path]?[query]" ...
- 将图片转换为Base64字符串公共类抽取
public class ImageToBase64 { //图片转化成base64字符串 public static String GetImageStr(String path,int width ...
- PostgreSQL配置文件--AUTOVACUUM参数
8 AUTOVACUUM参数 AUTOVACUUM PARAMETERS 8.1 autovacuum 字符型 默认: autovacuum = on Enable autovacuum subpro ...