数据分析之CE找数据大法
一.基本介绍
CE的全称为Cheat Engine,是一款内存修改编辑工具,其官网是http://www.cheatengine.org,可以在其官网下载到最新的CE工具,目前最新版本是Cheat Engine6.5。CE同时也是一款开源的工具,使用者可以在git中下载源代码: https://github.com/cheat-engine/cheat-engine。
CE的功能包括有16进制编辑,反汇编程序,内存查找工具。与同类修改工具相比,它具有强大的反汇编功能及调试功能,可以附加到游戏中进行调试,所以是分析游戏的工具之一。
二.CE内存搜索功能的使用
1. 精确搜索:
CE的主界面如下图所示,使用CE搜索游戏数据,首先需要将CE附加到游戏进程中。
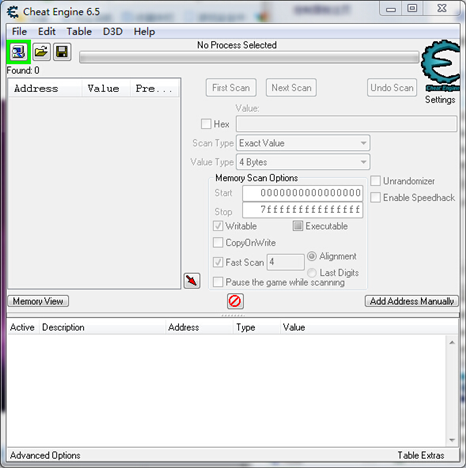
点击左上角菜单下发的绿色方框的按钮,打开进程列表对话框。
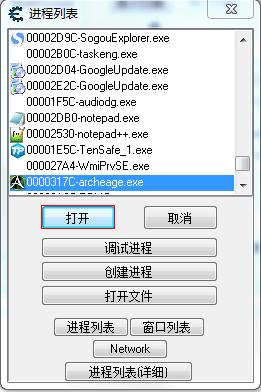
选择相应的游戏并点击打开,此时,就可以在数值搜索框中输入需要搜索的数据。比如搜索游戏中显示角色血量值的存放地址:
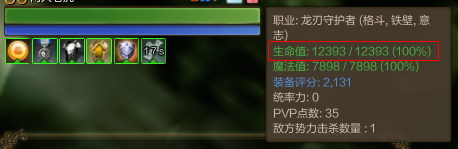
如上图血量所示,在CE的搜索数值输入框中输入“生命值”12393,选择扫描类型为“精确数值”,点击“新的扫描”开始第一次扫描。
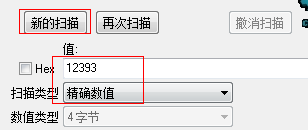
搜索出的匹配值有98个,由于结果较多,这个时候不能确定正确的存放地址,需要再次搜索。
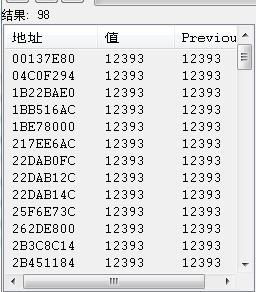
这个时候被怪打一下(使血量变化),输入新的生命值,点击“再次搜索”,此时的搜索值可以缩小到3个。
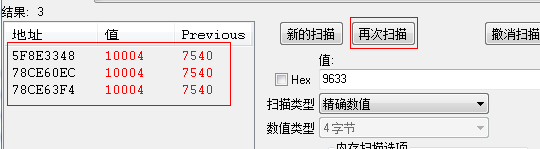
此时经过测试就可以发现第一个地址就是存放游戏界面中血量显示的地址。
2. 模糊搜索
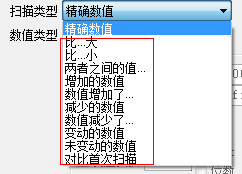
如果搜索数值不确定的话,就需要使用模糊搜索的方法。使用模糊搜索的情况主要有具体数值不显示在游戏界面上,比如血量用百分比表示。模糊搜索的类型比较多,如下图所示:
同样以搜索生命值为例,首次扫描时选择“未知的初始值”
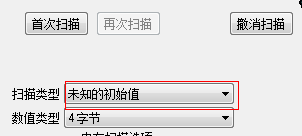
点击“首次扫描”,这个时候会出现非常多的扫描结果。这个时候去被怪物打一下减少血量后,由于此时数值是减小的,所以在扫描类型中选择“减少的数值”,然后点击再次扫描:
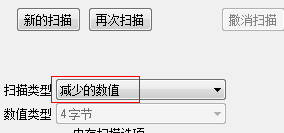
重复多次扫描后,即可找到存放的生命值的地址。
三.代码跟踪
代码跟踪比较常见的用途是找基址,游戏中任何数据都在内存中存在,比如角色的血,蓝,等级等数据,这些数值存放的方式一般是对象+偏移,在C++就是以指针的方式表示,如果需要知道对象在内存中的存放地址,就需要找到对象的基址。
需要知道对象的地址或数据的偏移,常见的方法就是找到访问或改变这个值的指令,可以使用Cheat Engine的反汇编及调试功能。
如上例的数据搜索找到的生命值存放的地址,将其放到CE最下方地址列表中,右键点击列表中的地址项,如下图所示,“找出是什么访问了这个地址”和“找出是什么改下了这个地址”分别可以跟踪生命值在代码的什么地方被读取和改写。
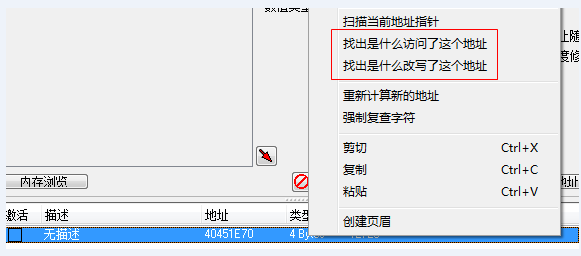
例如需要找到在血量被改写的地方,先在地址列表中右键点击“找出是什么改写了这个地址”,此时CE会附加到其内置的调试器,并自动列入对生命值进行写入的代码。
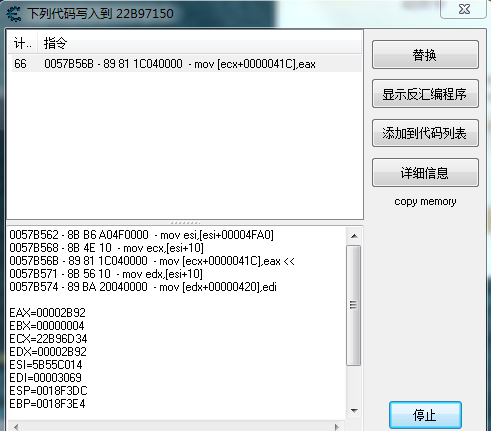
此时,ecx=0x22B96D34是对象的地址,血量通过eax赋值到+41Ch的地址漂移处。如上图所示,所以一级指针ecx的偏移+41Ch地址处。Ecx的赋值为上一条指令mov ecx, [esi+10],其二级指针是esi的偏移+10h地址处,再往上一条指令mov esi, [esi+4FA0],可以确定三级指针为esi,偏移为+4FA0h,以此类推,就可以找到血量存放的基址。
数据分析之CE找数据大法的更多相关文章
- 使用Python一步一步地来进行数据分析总结
原文链接:Step by step approach to perform data analysis using Python译文链接:使用Python一步一步地来进行数据分析--By Michae ...
- python requests抓取NBA球员数据,pandas进行数据分析,echarts进行可视化 (前言)
python requests抓取NBA球员数据,pandas进行数据分析,echarts进行可视化 (前言) 感觉要总结总结了,希望这次能写个系列文章分享分享心得,和大神们交流交流,提升提升. 因为 ...
- 基于Python的数据分析(1):配置安装环境
数据分析是一个历史久远的东西,但是直到近代微型计算机的普及,数据分析的价值才得到大家的重视.到了今天,数据分析已经成为企业生产运维的一个核心组成部分. 据我自己做数据分析的经验来看,目前数据分析按照使 ...
- 数据分析之---Python可视化工具
1. 数据分析基本流程 作为非专业的数据分析人员,在平时的工作中也会遇到一些任务:需要对大量进行分析,然后得出结果,解决问题. 所以了解基本的数据分析流程,数据分析手段对于提高工作效率还是非常有帮助的 ...
- 使用docker搭建数据分析环境
注:早在学习<云计算>这门课之前就已经知道docker,学习这门课时老师还鼓励我们自己尝试一下:但是直到去年年底才有机会尝试,用过之后感觉确实很好用.最近需要部署几个shiny应用,又回顾 ...
- 数据分析侠A的成长故事
数据分析侠A的成长故事 面包君 同学A:22岁,男,大四准备实习,计算机专业,迷茫期 作为一个很普通的即将迈入职场的他来说,看到周边的同学都找了技术开发的岗位,顿觉自己很迷茫,因为自己不是那么喜欢钻 ...
- 简易数据分析 09 | Web Scraper 自动控制抓取数量 & Web Scraper 父子选择器
这是简易数据分析系列的第 9 篇文章. 今天我们说说 Web Scraper 的一些小功能:自动控制 Web Scraper 抓取数量和 Web Scraper 的父子选择器. 如何只抓取前 100 ...
- mysql 数据分析如何实现日报、周报、月报和年报?
以天为统计周期,是常见需求.周报.月报更是常见需求.长周期项目,甚至有年报需求.我已经掌握了mysql中按天统计,如何实现按年.按月.按周统计呢? 1.已掌握的技能:按天统计 实现以天为统计周期很简单 ...
- 小白学 Python 数据分析(7):Pandas (六)数据导入
人生苦短,我用 Python 前文传送门: 小白学 Python 数据分析(1):数据分析基础 小白学 Python 数据分析(2):Pandas (一)概述 小白学 Python 数据分析(3):P ...
随机推荐
- Android中Parcelabel对象的使用和理解
1. Parcelable接口 Interface for classes whose instances can be written to and restored from a Parcel. ...
- lintcode-173-链表插入排序
173-链表插入排序 用插入排序对链表排序 样例 Given 1->3->2->0->null, return 0->1->2->3->null 标签 ...
- 软工实践原型设计——PaperRepositories
软工实践原型设计--PaperRepositories 写在前面 本次作业链接 队友(031602237吴杰婷)博客链接 pdf文件地址 原型设计地址(加载有点慢...) 结对成员:031602237 ...
- 工具函数:cookie的添加、获取、删除
cookie是浏览器存储的命名数据,作用是保存用户的信息,这样我们就可以用这些信息来做一些事了,但是cookie容量很小,只有4kb. 下面是我总结的cookie的添加.获取.删除的函数: cooki ...
- 【Redis】- 缓存击穿
什么是缓存击穿 在谈论缓存击穿之前,我们先来回忆下从缓存中加载数据的逻辑,如下图所示 因此,如果黑客每次故意查询一个在缓存内必然不存在的数据,导致每次请求都要去存储层去查询,这样缓存就失去了意义.如果 ...
- AutoResetEvent的基本用法
The following example uses an AutoResetEvent to synchronize the activities of two threads.The first ...
- opencv2.4.0版本不支持Mat的大小自动调整?
在opencv2.4.9中,resize(img,img,Size(850,550))是没问题的.到了2.4.0中,要新声明一个变量Mat img1;resize(img,img1,Size(850, ...
- 刚装的vs无法运行正确的程序
- [OS] 信号量(Semaphore)
一个信号量S是一个整型量,除对其初始化外,它只能由两个原子操作P和V来访问.P和V的名称来源于荷兰文proberen(测试)和verhogen(增量),后面亦将P/V操作分别称作wait(), sig ...
- Go语言【第十四篇】:Go语言基础总结
Go语言类型转换 类型转换用于将一种数据类型的变量转换为另外一种类型的变量,Go语言类型转换基本格式如下: type_name(expression) type_name为类型,expression为 ...