浅谈HashMap与线程安全 (JDK1.8)
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30; static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
// ....
}
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
transient Node<K,V>[] table;
//....
}
HashMap 内部存储使用了一个 Node 数组(默认大小是16),每个Node都是一个链表。每个链表存储相同索引的元素。
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;
从Java 8开始,HashMap(ConcurrentHashMap以及LinkedHashMap)在处理频繁冲突时,为了提升性能将使用平衡树来代替链表,当同一hash桶中的元素数量超过特定的值(TREEIFY_THRESHOLD )便会由链表切换到平衡树,这会将get()方法的性能从O(n)提高到O(logn)。
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
HashMap 内部的 Node 数组默认的大小是16(DEFAULT_INITIAL_CAPACITY )。
- Hashtable
- ConcurrentHashMap
- Synchronized Map
//Hashtable
Map<String, String> hashtable = new Hashtable<>();
//synchronizedMap
Map<String, String> synchronizedHashMap = Collections.synchronizedMap(new HashMap<String, String>());
//ConcurrentHashMap
Map<String, String> concurrentHashMap = new ConcurrentHashMap<>();
Hashtable (deprecate)
public synchronized V get(Object key) {...}
public synchronized V put(K key, V value) {...}
所以当一个线程访问 HashTable 的同步方法时,其他线程如果也要访问同步方法,会被阻塞住。因此Hashtable效率很低,基本被废弃。
/** For serialization compatibility. */
private static final ObjectStreamField[] serialPersistentFields = {
new ObjectStreamField("segments", Segment[].class),
new ObjectStreamField("segmentMask", Integer.TYPE),
new ObjectStreamField("segmentShift", Integer.TYPE)
};
负数代表正在进行初始化或扩容操作
-1代表正在初始化
-N 表示有N-1个线程正在进行扩容操作
正数或0代表hash表还没有被初始化,这个数值表示初始化或下一次进行扩容的大小
/**
* Table initialization and resizing control. When negative, the
* table is being initialized or resized: -1 for initialization,
* else -(1 + the number of active resizing threads). Otherwise,
* when table is null, holds the initial table size to use upon
* creation, or 0 for default. After initialization, holds the
* next element count value upon which to resize the table.
*/
private transient volatile int sizeCtl;
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
public final V setValue(V value) {
throw new UnsupportedOperationException();
}
}
/**
* Virtualized support for map.get(); overridden in subclasses.
*/
Node<K,V> find(int h, Object k) {
Node<K,V> e = this;
if (k != null) {
do {
K ek;
if (e.hash == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
} while ((e = e.next) != null);
}
return null;
}
private static class SynchronizedMap<K,V>
implements Map<K,V>, Serializable {
private final Map<K,V> m; // Backing Map
final Object mutex; // Object on which to synchronize
public int size() {
synchronized (mutex) {return m.size();}
}
public boolean isEmpty() {
synchronized (mutex) {return m.isEmpty();}
}
public boolean containsKey(Object key) {
synchronized (mutex) {return m.containsKey(key);}
}
public boolean containsValue(Object value) {
synchronized (mutex) {return m.containsValue(value);}
}
public V get(Object key) {
synchronized (mutex) {return m.get(key);}
} public V put(K key, V value) {
synchronized (mutex) {return m.put(key, value);}
}
public V remove(Object key) {
synchronized (mutex) {return m.remove(key);}
}
public void putAll(Map<? extends K, ? extends V> map) {
synchronized (mutex) {m.putAll(map);}
}
public void clear() {
synchronized (mutex) {m.clear();}
}
//...
}
ExecutorService 来并发运行5个线程,每个线程添加/获取500K个元素,比较其用时多少。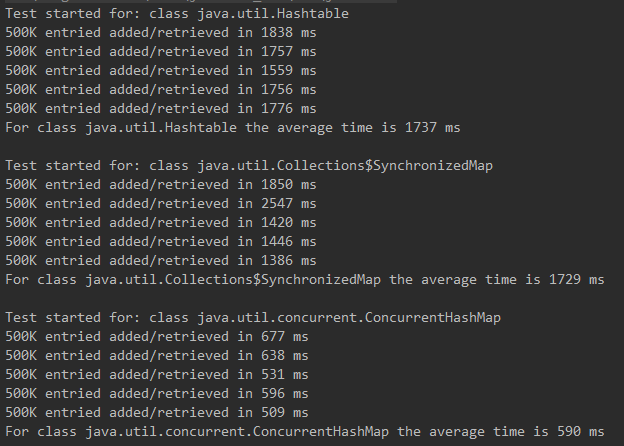
浅谈HashMap与线程安全 (JDK1.8)的更多相关文章
- Java重点之小白解析--浅谈HashMap与HashTable
这是一个面试经常遇到的知识点,无论什么公司这个知识点几乎是考小白必备,为什么呢?因为这玩意儿太特么常见了,常见到你写一百行代码,都能用到好几次,不问这个问哪个.so!本小白网罗天下HashMap与Ha ...
- 浅谈HashMap的实现原理
1. HashMap概述: HashMap是基于哈希表的Map接口的非同步实现.此实现提供所有可选的映射操作,并允许使用null值和null键.此类不保证映射的顺序,特别是它不保证该顺序恒久不变 ...
- 浅谈HashMap的内部实现
权衡时空 HashMap是以键值对的方式存储数据的. 如果没有内存限制,那我直接用哈希Map的键作为数组的索引,取的时候直接按索引get就行了,可是地价那么贵,哪里有无限制的地盘呢. 如果没有时间限制 ...
- 转:浅谈SimpleDateFormat的线程安全问题
转自:https://blog.csdn.net/weixin_38810239/article/details/79941964 在实际项目中,我们经常需要将日期在String和Date之间做转化, ...
- JAVA容器-浅谈HashMap的实现原理
概述 HashMap是通过数组+链表的方式实现的,由于HashMap的链表也是采用数组方式,我就修改直接利用LinkedList实现,简单模拟一下. 1.Key.Value的存取方式. 2.HashM ...
- 浅谈java中线程和操作系统线程
在聊线程之前,我们先了解一下操作系统线程的发展历程,在最初的时候,操作系统没有进程线程一说,执行程序都是串行方式执行,就像一个队列一样,先执行完排在前面的,再去执行后面的程序,这样的话很多程序的响应就 ...
- 【JDK源码分析】浅谈HashMap的原理
这篇文章给出了这样的一道面试题: 在 HashMap 中存放的一系列键值对,其中键为某个我们自定义的类型.放入 HashMap 后,我们在外部把某一个 key 的属性进行更改,然后我们再用这个 key ...
- struts 2学习笔记—浅谈struts的线程安全
Sruts 2工作流程: Struts 1中所有的Action都只有一个实例,该Action实例会被反复使用.通过上面Struts 2 的工作流程的红色字体部分我们可以清楚看到Struts 2中每个A ...
- 【Java】浅谈HashMap
HashMap是常用的集合类,以Key-Value形式存储值.下面一起从代码层面理解它的实现. 构造方法 它有好几个构造方法,但几乎都是调此构造方法: public HashMap(int initi ...
随机推荐
- [acm 1001] c++ 大数加法 乘法 幂
北大的ACM 1001 poj.org/problem?id=1001 代码纯手动编写 - - #include <iostream> #include <cstdio> #i ...
- bitekind
xrp这个人到SNT家坐在IOST的椅子上,喝着THETA. 武之巅峰,是孤独,是寂寞,是漫漫求索,是高处不胜寒 逆境中成长,绝地里求生,不屈不饶,才能堪破武之极道. 凌霄阁试炼弟子兼扫地 ...
- Data Flow ->> Multiple Excel Sheet Loaded Into One Table
同个Excel文件中多个Sheet中的数据导入到单张表中,参考了文章:http://www.cnblogs.com/biwork/p/3478778.html 思路: 1) ForEach Loop组 ...
- UVaOJ 694 - The Collatz Sequence
题目很简单,但是一开始却得到了Time Limit的结果,让人感到很诧异.仔细阅读发现,题目中有一个说明: Neither of these, A or L, is larger than 2,147 ...
- 记账本app(一)
计划开发一款小程序应用,主要来记录自己的财务账目. 通过使用SpringBoot开发后端应用,提供接口,对应前端使用微信小程序来实现. 功能模块(用户信息,账本.账目列表,新增一笔账,修改一笔账,删除 ...
- ZT SAFE_DELETE
SAFE_DELETE 分类: c/C++ 2008-10-14 14:26 706人阅读 评论(2) 收藏 举报 delete文本编辑nullflash破解加密 我发现学程序大家差不多都有相似的地方 ...
- call/apply
call与apply都可以改变this指向,但是传参列表不同. call 任何一种方法都可以.call,借用别人函数,自己用. call只需把实参按照形参的个数传进去,apply只能传一个argume ...
- 文件上传之FileItem使用
一.介绍 FileItem类的常用方法: 1.boolean isFormField().isFormField方法用来判断FileItem对象里面封装的数据是一个普通文本表单字段(true),还是一 ...
- Lambda收集器示例
Collectors常用方法 工厂方法 返回类型 作用 toSet Set 把流中所有项目收集到一个 Set,删除重复项 toList List 收集到一个 List 集合中 toCollection ...
- stack的三个意思
(转自阮一峰的网络日志,原网址http://www.ruanyifeng.com/blog/2013/11/stack.html) 阮一峰老师终于又更新博客了,个人认为这篇文章有一定科普意义,有一定解 ...