scrapy(1)——scrapy介绍
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
所谓网络爬虫,就是一个在网上到处或定向抓取数据的程序,当然,这种说法不够专业,更专业的描述就是,抓取特定网站网页的HTML数据。抓取网页的一般方法是,定义一个入口页面,然后一般一个页面会有其他页面的URL,于是从当前页面获取到这些URL加入到爬虫的抓取队列中,然后进入到新页面后再递归的进行上述的操作,其实说来就跟深度遍历或广度遍历一样。
Scrapy 使用 Twisted这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求。
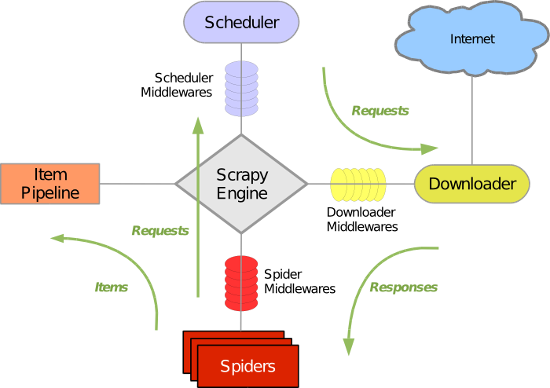
- 引擎(Scrapy Engine),用来处理整个系统的数据流处理,触发事务。
- 调度器(Scheduler),用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。
- 下载器(Downloader),用于下载网页内容,并将网页内容返回给蜘蛛。
- 蜘蛛(Spiders),蜘蛛是主要干活的,用它来制订特定域名或网页的解析规则。编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
- 项目管道(Item Pipeline),负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清晰、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件(Downloader Middlewares),位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
- 蜘蛛中间件(Spider Middlewares),介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。
- 调度中间件(Scheduler Middlewares),介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
scrapy(1)——scrapy介绍的更多相关文章
- python Scrapy安装和介绍
python Scrapy安装和介绍 Windows7下安装1.执行easy_install Scrapy Centos6.5下安装 1.库文件安装yum install libxslt-devel ...
- golang学习笔记17 爬虫技术路线图,python,java,nodejs,go语言,scrapy主流框架介绍
golang学习笔记17 爬虫技术路线图,python,java,nodejs,go语言,scrapy主流框架介绍 go语言爬虫框架:gocolly/colly,goquery,colly,chrom ...
- 爬虫--Scrapy框架课程介绍
Scrapy框架课程介绍: 框架的简介和基础使用 持久化存储 代理和cookie 日志等级和请求传参 CrawlSpider 基于redis的分布式爬虫 一scrapy框架的简介和基础使用 a) ...
- Python -- Scrapy 框架简单介绍(Scrapy 安装及项目创建)
Python -- Scrapy 框架简单介绍 最近在学习python 爬虫,先后了解学习urllib.urllib2.requests等,后来发现爬虫也有很多框架,而推荐学习最多就是Scrapy框架 ...
- scrapy爬虫框架介绍
一 介绍 Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速.简单.可扩展的方式从网站中提取所需的数据.但目前Scrapy的用途十分广泛,可 ...
- Scrapy之Scrapy shell
Scrapy Shell Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据 ...
- python爬虫scrapy之scrapy终端(Scrapy shell)
Scrapy终端是一个交互终端,供您在未启动spider的情况下尝试及调试您的爬取代码. 其本意是用来测试提取数据的代码,不过您可以将其作为正常的Python终端,在上面测试任何的Python代码. ...
- 第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令 Scrapy框架安装 1.首先,终端执行命令升级pip: python -m pip install --u ...
- 十 web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
Scrapy框架安装 1.首先,终端执行命令升级pip: python -m pip install --upgrade pip2.安装,wheel(建议网络安装) pip install wheel ...
- scrapy - 给scrapy 的spider 传值
scrapy - 给scrapy 的spider 传值 方法一: 在命令行用crawl控制spider爬取的时候,加上-a选项,例如: scrapy crawl myspider -a categor ...
随机推荐
- vue vue-router 完美实现前进刷新,后退不刷新。附scrollBehavior源码解析
需求:在一个vue的项目中,我们需要从一个列表页面点击列表中的某一个详情页面,从详情页面返回不刷新列表,而从列表的上一个页面重新进入列表页面则需要刷新列表. 而浏览器的机制则是每一次的页面打开都会重新 ...
- DXP常用的设置及快捷键
原文地址:http://www.cnblogs.com/NickQ/p/8799240.html 测试环境:Altium Designer Summer 16 一.快捷键 1.原理图和PCB通用快捷键 ...
- 008---vim编辑器
vim 编辑器 三个模式 三个模式之间切换 图 命令模式进入编辑模式 A:行末 a:向后 i:向前 I:行首 o:向上 O:向下 命令模式 复制 yy:复制光标所在行 4yy:向下复制四行 剪切(删除 ...
- 蓝桥杯 算法训练 K好数
参考:https://blog.csdn.net/jjmjeffrey/article/details/69298110 https://www.cnblogs.com/TWS-YIFEI/p/634 ...
- 苏州Uber优步司机奖励政策(1月4日~1月10日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- P1208 [USACO1.3]混合牛奶 Mixing Milk
P1208 [USACO1.3]混合牛奶 Mixing Milk 题目描述 由于乳制品产业利润很低,所以降低原材料(牛奶)价格就变得十分重要.帮助Marry乳业找到最优的牛奶采购方案. Marry乳业 ...
- VIM第七版
ZZ:退出并保存 e!:退回到上次保存时的样子 cw:修改单词(自动进入插入模式) cc:修改一整行的内容 cs:修改一个词(自动进入插入模式) .:可以重复上一个命令 J:将下一行内容合并到本行末尾 ...
- Git一分钟系列--快速安装git客户端
在项目开发过程中,几乎所有公司都会用到版本控制工具来管理自己的项目资源文件,比如Git,SVN. 什么是svn? 版本控制软件,通过svn来实现版本控制首先需要搭建一个服务器,在服务器上创建仓库保存项 ...
- Win10系统XWware虚拟机安装Linux系统(Ubuntu)最新版教程
XWware虚拟机安装Linux系统(Ubuntu)教程 一.下载并安装VMware虚拟机 借助VMware Workstation Pro, 我们可以在同一台Windows或Linux PC上同时运 ...
- tpo-09 C2 Return a sociology book
check out 在library里有借书的意思 第 1 段 1.Listen to a conversation between a student and a librarian employe ...