(数据科学学习手札51)用pymysql来操控MySQL数据库
一、简介
pymysql是Python中专门用来操控MySQL数据库的模块,通过pymysql,可以编写简短的脚本来方便快捷地操控MySQL数据库,本文就将针对pymysql的基本功能进行介绍;
二、操控数据库
2.1 连接数据库
利用pymysql.connect(host,user,password,port,db)来实现对已知MySQL数据库的连接,其中各参数分别对应着目标数据库的各项属性,db用于指定要连接的database的名称,下面是一个示例:
要连接的数据库:
import pymysql '''连接数据库'''
try:
print('-'*200)
print('尝试连接数据库')
print('-'*200)
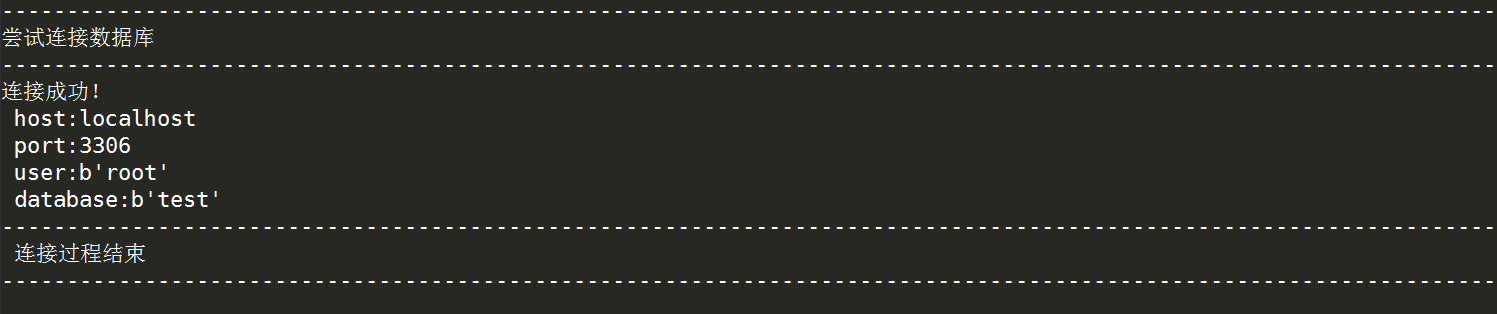
db = pymysql.connect(host='localhost',user='root',password='我的密码',port=3306,db='test')
print('连接成功!','\n',
'host:{}'.format(db.host),'\n',
'port:{}'.format(db.port),'\n',
'user:{}'.format(db.user),'\n',
'database:{}'.format(db.db)) except Exception as e:
print('因{},连接失败'.format(e))
finally:
print('-'*200,'\n','连接过程结束')
print('-'*200)
若连接成功,显示如下信息:
2.2 插入数据
在成功连接数据库之后,我们使用db.cursor()来获取数据库的操作游标:
'''获取操作游标'''
cur = db.cursor()
接下来我们使用.execute()来执行需要完成的SQL语句,其传入参数为字符串类型的SQL语句,譬如,下面的例子中我们创建一个新的表,并将sklearn中内置的鸢尾花数据传入进去:
from sklearn.datasets import load_iris '''获取鸢尾花数据,其中X,y为二维数组'''
X,y = load_iris(return_X_y=True)
'''建立指定鸢尾花类别名称的列表'''
Species = ['setosa','versicolor','virginica'] '''通过操作游标执行SQL语句,以创建iris表'''
cur.execute("CREATE TABLE IF NOT EXISTS iris"
"(Sepal_Length float,"
"Sepal_Width float,"
"Petal_Length float,"
"Petal_Width float,Species char(20)"
")") '''构造将X,y数据一次性插入iris的SQL语句'''
BaseSQL = "INSERT INTO iris VALUES" for i in range(X.shape[0]):
BaseSQL += "({},{},{},{},'{}'),".format(X[i,0],X[i,1],X[i,2],X[i,3],Species[y[i]]) '''去除末尾多余的逗号'''
BaseSQL = BaseSQL[:-1] '''执行插入鸢尾花数据的SQL语句'''
cur.execute(BaseSQL)
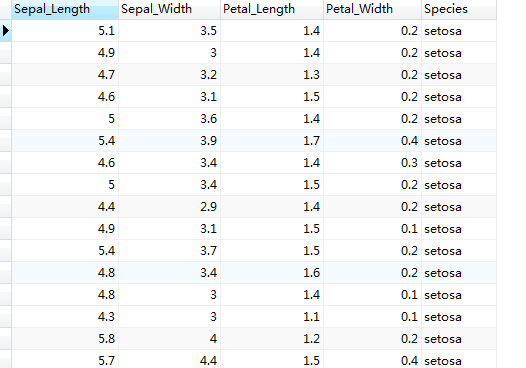
运行完上述语句,在已经连接数据库的navicat中查看iris表中的全部数据:
USE test;
SELECT * FROM iris;

这是会发现,查询结果只有一张空表,这是因为在执行完插入数据的语句后,并没有提交结果,使用.commit()向数据库提交结果:
'''提交结果'''
db.commit()
在navicat中再次查询得到想要的结果:
2.3 查询数据
查询功能是数据库中核心功能之一,查询取数也是数据分析人员在数据库上最常用的操作,在pymysql中想要完成查询取数的过程,要在执行SQL语句之后,对我们的游标对象使用.fetchall()方法来取得对应的查询结果:
'''查询取数'''
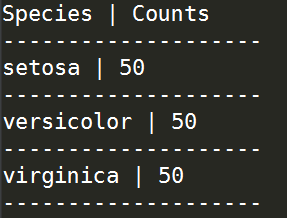
cur.execute("SELECT Species,COUNT(*) FROM iris GROUP BY Species") '''获取查询结果'''
results = cur.fetchall() print(results)

可以看到,取回的结果为一个规整的tuple对象,可以按照其格式打印出查询结果:
print('Species','|','Counts')
for result in results:
print('-'*20)
print(result[0],'|',result[1])
print('-'*20)
或者转换为其他格式保存为其他规整的格式以便进一步分析:
import pandas as pd df = pd.DataFrame(list(results),columns=['Species','Counts'])
print(df)
而关于其他对数据库的操作(如删除、更新等),与上面类似,只是涉及到更改数据库中数据时,不要忘记commit();
2.4 关闭数据库
在完成需要的操作后,不要忘记断开与数据库间的连接:
db.close()
以上就是本文的全部内容,如有笔误,望指出!
(数据科学学习手札51)用pymysql来操控MySQL数据库的更多相关文章
- (数据科学学习手札55)利用ggthemr来美化ggplot2图像
一.简介 R中的ggplot2是一个非常强大灵活的数据可视化包,熟悉其绘图规则后便可以自由地生成各种可视化图像,但其默认的色彩和样式在很多时候难免有些过于朴素,本文将要介绍的ggthemr包专门针对原 ...
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
- (数据科学学习手札49)Scala中的模式匹配
一.简介 Scala中的模式匹配类似Java中的switch语句,且更加稳健,本文就将针对Scala中模式匹配的一些基本实例进行介绍: 二.Scala中的模式匹配 2.1 基本格式 Scala中模式匹 ...
- (数据科学学习手札47)基于Python的网络数据采集实战(2)
一.简介 马上大四了,最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑. 二.马蜂窝评论数据采集 ...
- (数据科学学习手札44)在Keras中训练多层感知机
一.简介 Keras是有着自主的一套前端控制语法,后端基于tensorflow和theano的深度学习框架,因为其搭建神经网络简单快捷明了的语法风格,可以帮助使用者更快捷的搭建自己的神经网络,堪称深度 ...
- (数据科学学习手札42)folium进阶内容介绍
一.简介 在上一篇(数据科学学习手札41)中我们了解了folium的基础内容,实际上folium在地理信息可视化上的真正过人之处在于其绘制图像的高度可定制化上,本文就将基于folium官方文档中的一些 ...
- (数据科学学习手札40)tensorflow实现LSTM时间序列预测
一.简介 上一篇中我们较为详细地铺垫了关于RNN及其变种LSTM的一些基本知识,也提到了LSTM在时间序列预测上优越的性能,本篇就将对如何利用tensorflow,在实际时间序列预测任务中搭建模型来完 ...
- (数据科学学习手札36)tensorflow实现MLP
一.简介 我们在前面的数据科学学习手札34中也介绍过,作为最典型的神经网络,多层感知机(MLP)结构简单且规则,并且在隐层设计的足够完善时,可以拟合任意连续函数,而除了利用前面介绍的sklearn.n ...
- (数据科学学习手札32)Python中re模块的详细介绍
一.简介 关于正则表达式,我在前一篇(数据科学学习手札31)中已经做了详细介绍,本篇将对Python中自带模块re的常用功能进行总结: re作为Python中专为正则表达式相关功能做出支持的模块,提供 ...
随机推荐
- 计算机支持的最大内存与CPU之间的关系
在使用计算机时,其最大支持的内存是由 操作系统 和 硬件 两方面决定的. 先说一下硬件方面的因素,在计算机中 CPU的地址总线数目 决定了CPU 的 寻址 范围,这种由地址总线对应的地址称作为物理地 ...
- Exchange 2016证书配置
配置证书: 第一步,在ECP界面生成证书请求文件: 1.在“服务器 —>证书”界面,选择一台服务器,点击“+”来添加证书申请,如下图: 2.默认下一步, 3.填写证书的友好名称,如下图: 4.默 ...
- pip 升级 Appium-Python-Client
第一种方法: pip install --upgrade Appium-Python-Client 如果出现权限提醒: sudo -H pip install --upgrade Appium-Pyt ...
- WinRAR(5.21)-0day漏洞-始末分析
0x00 前言 上月底,WinRAR 5.21被曝出代码执行漏洞,Vulnerability Lab将此漏洞评为高危级,危险系数定为9(满分为10),与此同时安全研究人员Mohammad Reza E ...
- 几个第三方yum源
1.repoforge 官方网站:http://repoforge.org/ 2.epel http://fedoraproject.org/wiki/EPEL 3.Remi http://rpms. ...
- IOS Singleton(单例)
Singleton.h // .h #define singleton_interface(class) + (instancetype)shared##class; // .m #define si ...
- python内置模块(三)
hashlib模块 通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示). Python2中使用hashlib: import hashlib m = hashlib ...
- MySQL5.7 不同操作系统下的主从配置
1. 服务器信息 1.1 Ubuntu 17.0.4 (Master服务器) MySQL版本: 5.7.20 主数据库:dslbcp IP: 192.168.12.130 3306 1.2 Wind ...
- JavaScript的DOM_动态加载脚本和样式
一.动态加载脚本 当网站需求变大,脚本的需求也逐步变大.我们就不得不引入太多的 JS 脚本而降低了整站的性能,所以就出现了动态脚本的概念,在适时的时候加载相应的脚本. 1.动态加载js文件 比如:我们 ...
- Nginx学习.md
正常运行的必备配置 user Syntax: user user [group]; Default: user nobody nobody; Context: main 指定运行worker进程的用户 ...