SQL Server 索引列的顺序——真的没关系吗
问题:
当设置表的索引时,在性能上有一个微妙的平衡:太多的索引将影响你的INSERT/UPDATE/DELETE操作。但是索引不足又将影响你的SELECT操作。本文将着眼于索引的列顺序和如何影响查询计划及性能。
解决方案:
示例SQLServer表和数据集:
-- Tablecreation logic
CREATE TABLE[dbo].[TABLE1]
([col1][int]
NOT NULL,[col2]
[int]NULL,[col3]
[int] NULL,[col4][varchar](50)NULL)
GO
CREATE TABLE[dbo].[TABLE2]
([col1][int]
NOT NULL,[col2]
[int]NULL,[col3]
[int] NULL,[col4][varchar](50)NULL)
GO
ALTER TABLEdbo.TABLE1ADD
CONSTRAINT PK_TABLE1
PRIMARY KEY
CLUSTERED (col1)
GO
ALTER TABLEdbo.TABLE2ADD
CONSTRAINT PK_TABLE2
PRIMARY KEY
CLUSTERED (col1)
GO
--Populate tables
DECLARE
@val INT
SELECT @val=1
WHILE @val< 1000
BEGIN
INSERT
INTO dbo.Table1(col1,col2,
col3,
col4)VALUES(@val,@val,@val,'TEST')
INSERT
INTO dbo.Table2(col1,col2,
col3,
col4)VALUES(@val,@val,@val,'TEST')
SELECT
@val=@val+1
END
GO
--Create multi-column index on table1
CREATE NONCLUSTEREDINDEX
IX_TABLE1_col2col3ONdbo.TABLE1(col2,col3)
WITH (STATISTICS_NORECOMPUTE=OFF,
IGNORE_DUP_KEY =
OFF,
ALLOW_ROW_LOCKS=ON,
ALLOW_PAGE_LOCKS =
ON)
ON [PRIMARY]
GO
在运行下面的代码前请先打开执行计划(Ctrl+M)和打开统计IO的语句:SET STATISTICS IO ON
单表查询例子:
在第一个例子里面,我们将使用在where子句中的一列来查询。第一个查询中where子句的索引使用第二列(col3),第二个查询使用第一列(col2)。注意这里使用了“DBCC DROPCLEANBUFFERS”,用于确保没有缓存带来的影响,代码如下:
DBCC DROPCLEANBUFFERS
GO
SELECT * FROM dbo.TABLE1 WHEREcol3=88
GO
DBCC DROPCLEANBUFFERS
GO
SELECT * FROM dbo.TABLE1 WHEREcol2=88
GO
执行后查看执行计划如下:


可以看到,第一个查询使用第二列(col3)的索引是在表上执行索引扫描,且没有用到刚才建立的索引。第二个查询使用了表查找,使得在表里只需要使用更少的资源。第一个查询读了6次,而第二个查询只读了4次。
执行查询后,你应该大概猜到,当表越来越大的时候,性能优势就显现出来了。
两表关联查询例子:
在下一个例子中,查询使用同样的where子句,但增加了一个inner join 关联另外一个表。第一个查询的where子句使用col3,并使用col2来关联表。
第二个查询的where子句使用col2,并使用col3来关联表。
同样,先执行DBCC DROPCLEANBUFFERS来确保缓存已经清空。代码如下:
DBCC DROPCLEANBUFFERS
GO
SELECT *
FROM dbo.TABLE1 INNER JOIN
dbo.TABLE2 ON dbo.TABLE1.col2 = dbo.TABLE2.col1
WHERE dbo.TABLE1.col3=255
GO
DBCC DROPCLEANBUFFERS
GO
SELECT *
FROM dbo.TABLE1 INNER JOIN
dbo.TABLE2 ON dbo.TABLE1.col3 = dbo.TABLE2.col1
WHERE dbo.TABLE1.col2=255
GO
执行计划如下:

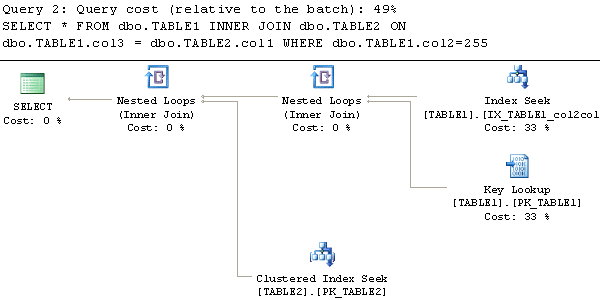
从执行计划可以看到,当用于关联表的列也在索引中,但不是第一列时,会执行索引扫描。第二个查询中索引的第一列来关列,会使用索引查找。从IO来看,同样索引查找的读次数会更小。
总结:
从这些例子中,可以看到索引列的顺序对表的查询也有影响。当创建索引时,先确认你总是对尽可能小的集合进行操作,这意味着索引能从where子句中的列开始。另外,对order by子句中的列和SELECT中的列创建覆盖索引也有助于提高查询性能。这样可以不用在查询时执行书签查找。
在前面提到的,增加太多索引将引起insert/update/delete时对这些索引列的修改。所以,找到平衡点才是最重要的。
SQL Server 索引列的顺序——真的没关系吗的更多相关文章
- [转帖]SQL Server 索引中include的魅力(具有包含性列的索引)
SQL Server 索引中include的魅力(具有包含性列的索引) http://www.cnblogs.com/gaizai/archive/2010/01/11/1644358.html 上个 ...
- SQL Server索引进阶:第五级,包含列
原文地址: Stairway to SQL Server Indexes: Level 5, Included Columns 本文是SQL Server索引进阶系列(Stairway to SQL ...
- SQL Server索引设计 <第五篇>
SQL Server索引的设计主要考虑因素如下: 检查WHERE条件和连接条件列: 使用窄索引: 检查列的选择性: 检查列的数据类型: 考虑列顺序: 考虑索引类型(聚集索引OR非聚集索引): 一.检查 ...
- SQL Server索引总结二
从CREATE开始 通过显式的CREATE INDEX命令 在创建约束时作为隐含的对象 随约束创建的隐含索引 当向表中添加如下两种约束之一时,就会创建隐含索引. 主键约束(聚集索引) 唯一约束(唯一索 ...
- SQL Server索引 (原理、存储)聚集索引、非聚集索引、堆 <第一篇>
一.存储结构 在SQL Server中,有许多不同的可用排列规则选项. 二进制:按字符的数字表示形式排序(ASCII码中,用数字32表示空格,用68表示字母"D").因为所有内容都 ...
- SQL Server 索引结构及其使用(一)
转载:SQL Server 索引结构及其使用(一) 作者:freedk 一.深入浅出理解索引结构 实际上,您可以把索引理解为一种特殊的目录.微软的SQL SERVER提供了两种索引:聚集索引(clus ...
- SQL Server索引进阶:第十级,索引内部结构
原文地址: Stairway to SQL Server Indexes: Level 10,Index Internal Structure 本文是SQL Server索引进阶系列(Stairway ...
- SQL Server索引进阶:第九级,读懂执行计划
原文地址: Stairway to SQL Server Indexes: Level 9,Reading Query Plans 本文是SQL Server索引进阶系列(Stairway to SQ ...
- SQL Server索引进阶:第六级,标签
原文地址: Stairway to SQL Server Indexes: Level 6,Bookmarks 本文是SQL Server索引进阶系列(Stairway to SQL Server I ...
随机推荐
- Linq 导出Excel
var d = db.User; Repeater1.DataSource = d.ToList(); Repeater1.DataBind(); string guid = Guid.NewGuid ...
- Screwturn搭建企业内部wiki
企业内部WIKI搭建 本文所使用的是Screwturn 基于asp.net webform和Sql server的. 仅仅要把本文资源下载下来,直接用IIS部署,然后更改web.config的conn ...
- Socket开发
Socket开发框架之消息的回调处理 伍华聪 2016-03-31 20:16 阅读:152 评论:0 Socket开发框架之数据加密及完整性检查 伍华聪 2016-03-29 22:39 阅 ...
- DRY
DRY(Don't Repeat Yourself )原则 凡是写过一些代码的程序猿都能够意识到应该避免重复的代码和逻辑.我们通过提取方法,提取抽象类等等措施来达到这一目的.我们总能时不时的听到类 ...
- 原创教程“ActionScript3.0游戏中的图像编程”開始连载啦!
经过近两年的不懈努力,笔者的原创教程"ActionScript3游戏中的图像编程"最终在今日划上了完美的句号!这其中记录着笔者多年来在游戏制作,尤其是其中图像处理方 ...
- UNIX网络编程卷1 时间获取程序server TCP 协议相关性
本文为senlie原创.转载请保留此地址:http://blog.csdn.net/zhengsenlie 最初代码: 这是一个简单的时间获取server程序.它和时间获取程序client一道工作. ...
- Big Event in HDU(杭电1171)(多重背包)和(母函数)两种解法
Big Event in HDU Time Limit: 10000/5000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others ...
- An Overview of Complex Event Processing
An Overview of Complex Event Processing 复杂事件处理技术概览(一) 翻译前言:我在理解复杂事件处理(CEP)方面一直有这样的困惑--为什么这种计算模式是有效的, ...
- 安装好.net framework后运行慢
表现 系统有时运行慢,尤其是.net程序运行得相当慢 mscorsvw.exe与mscorsvw.exe *32两个进程挂在任务管理器里时不时地占着CPU 解决 运行以下两条命令,加快这两进程的运行, ...
- 蚁群算法和简要matlab来源
1 蚁群算法原理 从1991由意大利学者 M. Dorigo,V. Maniezzo 和 A. Colorni 通过模拟蚁群觅食行为提出了一种基于群体的模拟进化算法--蚁群优化.极大关注,蚁群算法的特 ...