[python学习手册-笔记]004.动态类型
004.动态类型
❝
本系列文章是我个人学习《python学习手册(第五版)》的学习笔记,其中大部分内容为该书的总结和个人理解,小部分内容为相关知识点的扩展。
非商业用途转载请注明作者和出处;商业用途请联系本人(gaoyang1019@hotmail.com)获取许可。
❞
基础概念的解释
首先我们来解释一些基础概念,看不懂的可以跳过,这对于初学者不是很重要。
强类型语言和弱类型语言
首先,强弱类型语言的区分不是看变量声明的时候是否显式的定义数据类型。
强类型语言,定义是任何变量在使用的时候必须要指定这个变量的类型,而且在程序的运行过程中这个变量只能存储这个类型的数据。因此,对于强类型语言,一个变量不经过强制转换,它永远是这个数据类型,不允许隐式的类型转换。比如java,python都属于强类型语言。
强类型语言在编译的时候,就可以检查出类型错误,避免一些不可预知的错误,使得程序更加安全。
与之对应的是弱类型语言,在变量使用的时候,不严格的检查数据类型,比如vbScript,数字12和字符串3进行连接,可以直接得到123。再比如C语言中int i = 0.0是可以通过编译的。
另外知乎上关于相关问题 rainoftime 大神也有相关解答,没有查到权威解释,对大神的解答存疑,但是可以参考,帮助我们理解。
动态类型语言和静态类型语言
动态类型和静态类型的区别主要在数据类型检查的阶段。
动态类型语言:运行期间才去做数据类型的检查。在动态类型语言中,不需要给变量显式的指明其数据类型,该语言会在第一次赋值的时候,将内部的数据类型记录下来。
静态类型语言,在编译阶段就进行数据类型检查。也就是说静态类型语言,在定义变量的时候,必须声明数据类型。
这里有个比较经典的图:
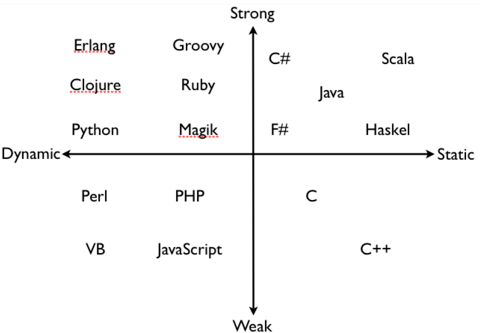
堆和栈
首先,堆儿(不好意思,这里不应该带儿化音...),堆(heap)和栈(stack)的概念在不同范畴是有不同含义的。
在数据结构中,堆指的是满足父子节点满足大小关系的一种完全二叉树。栈指的是满足后进先出(LIFO),支持pop和push两种操作的一个“桶”(本来想说序列,但是不知道准不准确,所以说了个桶...)
在操作系统中,堆儿和栈指的是内存空间。
栈,和数据结构中的栈差不多,是一个LIFO队列,由编译器自动分配和释放,主要用来存放函数的参数值,局部变量的值等内容。
堆,一般由程序员分配和释放,当然,像java和python这类语言也有自动垃圾回收的机制。这个我们在后面会讲到。
关于堆儿和栈的详细解释可以参考 Memory : Stack vs Heap
变量、对象和引用
python中的变量声明是不需要显式的指定类型的,但这并不表明python是一个弱类型语言。
比如,我们的一条简单的赋值语句a=3,那么接下来python编译器会做哪些事情呢?
创建变量和字面量: 创建一个字面量3(如果这个字面量还没有被创建过的情况下) 创建一个名称叫a的变量。一般我们理解在这个变量a第一次被赋值的时候就创建了它。(实际python解释器在运行代码之前就会检测变量名)
检查变量类型: python中类型是针对对象而言的,并不是针对变量名而言的。 对象会包含两个重要的头部信息,一个是类型标志符,一个是引用计数器。 变量名并不会限制变量的类型。也就是说这个 a它只是一个名字,具体“关联”什么类型的变量,这个是没有限制的。
变量的使用 当变量出现在表达式中的时候,它就会被当前引用的对象所代替。 还是说这个例子,如果在之后的代码中使用了a,比如 a+1那么这里的a就会被指向3这个字面量
简单总结,当我们执行a=3的时候,实际做了三件事:
创建一个对象实例,3 创建一个变量,a 将变量名a引用到对象实例3上

这里提到了一个概念,引用。 引用其实就是一种关系,是通过内存中的指针所实现的。
好嘞,这里又出现了一个新的概念,指针。 指针这个东西,简单来说可以理解为内存地址的一个指向。就是对初学者不好解释(主要是我懒得解释,就是属于那种懂的不需要讲,不懂的一时半会讲了也是不懂,但是随着学习的深入,慢慢就理解了的东西。。。)
变量的类型
首先,python是一个强类型语言,这是毫无疑问的。 但是python不需要显式的声明变量类型。 这是因为python的类型是记录在对象实例中的。
在前面我们讲到过,python中的对象会包含两个重要的头部信息:
类型标志符(type designator):用来标识这个对象的类型 引用计数器(reference counter): 表明有多少个变量引用到了这个对象上,用于跟踪改对象应该何时被回收
因为对象的这个机制,python中的变量声明的时候,就不需要再指定类型了。 也就是说变量名与变量类型是无关的。
a=1
a='spam'
a=1.123
而且如上所示,同一个变量名可以赋值给不同类型的对象实例。
共享引用
这里提出一个问题,如下代码:
In [6]: a=3
In [7]: b=a
In [8]: a='spam'
那么在经过这一系列操作之后,a和b的值分别是啥?
In [9]: a
Out[9]: 'spam'
In [10]: b
Out[10]: 3
首先我们来看,在执行a=3和b=a之后,发生了什么

a=3根据之前的介绍,比较好理解了。b=a实际上变量名b只是复制了a的引用,然后b也引用到了对象实例3上。那在之后这一句a='spam'又发生了什么?

这个图就说的很清楚了,在我们执行了a='spam'之后,a被指向了另外一个对象。
搞清楚了这个之后,我们再来看下一个例子:
a=3
b=a
a=a+3
这个前两句就不需要解释了,第三句a=a+3 其实一眼就可以看出来,此时a是6。这个就涉及到前面说的,当a出现在表达式中的时候,它就会“变成”它所引用的对象实例。a=a+3也就是会变成3+3 计算后得出新的对象实例6,然后变量a引用到6这个对象上。
「在原位置修改」
关于共享引用,这里看一个特殊的例子:
In [16]: L1=[1,2,3]
In [17]: L2=L1
In [18]: L1[0]=1111
In [19]: L1
Out[19]: [1111, 2, 3]
In [20]: L2
Out[20]: [1111, 2, 3]
按照之前的剧本,L2和L1都是指向列表[1,2,3]这个对象的,那为什么在我们修改L1[0] 这个元素之后,为什么L2也跟着发生变化了呢?
我自己画了图,从这个图可以看出来,实际上对于L1和L2的共享引用来看,并没有违反我们上面说的共享引用的原则。只是对于序列中元素的修改,L1[0]会在原位置覆盖列表对象中的某部分值。
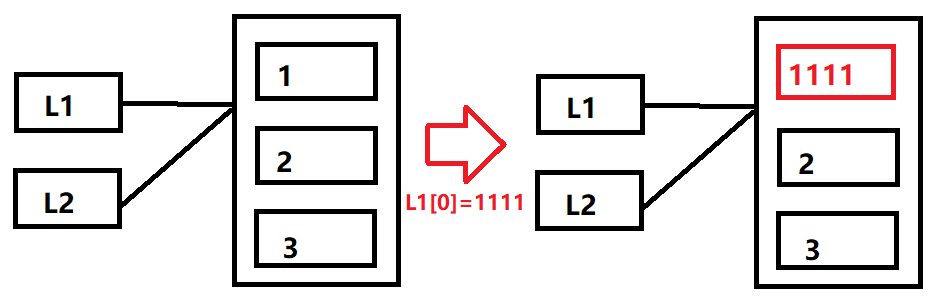
那么问题来了如果在修改L1[0]之后,并不想L2的值受到影响,那该怎么办?
简单
把列表原原本本的复制一份就好了。 复制的办法有三种:
第一种针对列表而言,可以直接创建一个完整的切片,本质上是一种浅拷贝。
In [32]: L1=[[1,2,3],4,5,6]
In [33]: L2=L1[:]
In [34]: L2
Out[34]: [[1, 2, 3], 4, 5, 6]
In [37]: L1[2]='aaa'
In [38]: L2
Out[38]: [[1111, 2, 3], 4, 5, 6]
In [39]: L1
Out[39]: [[1111, 2, 3], 4, 'aaa', 6]
第二种,浅拷贝,如下面这个例子中的D1.copy()
In [26]: D1={a:[1,2,3],b:3}
In [27]: import copy
In [28]: D2=D1.copy()
In [29]: D2
Out[29]: {6: [1, 2, 3], 3: 3}
In [30]: D1[a][0]=1111
In [31]: D2
Out[31]: {6: [1111, 2, 3], 3: 3}
第三种,深拷贝,如下D2=copy.deepcopy(D1)
In [41]: import copy
In [45]: D1={'A':[1,2,3],'B':'spam'}
In [46]: D1
Out[46]: {'A': [1, 2, 3], 'B': 'spam'}
In [47]: D2=copy.deepcopy(D1)
In [48]: D2
Out[48]: {'A': [1, 2, 3], 'B': 'spam'}
In [49]: D1['A'][0]=1111
In [50]: D1
Out[50]: {'A': [1111, 2, 3], 'B': 'spam'}
In [51]: D2
Out[51]: {'A': [1, 2, 3], 'B': 'spam'}
我相信,看到这里,对于深拷贝和浅拷贝有些读者已经明白了,但是有些读者还是迷糊的。 这里简单说一下,
浅拷贝:只拷贝父对象,不会拷贝对象内部的子对象。
深拷贝:完全拷贝父对象和子对象。


更详细的内容见: Python 直接赋值、浅拷贝和深度拷贝解析
「关于相等」
先看一个例子
In [59]: L1=[1,2,3]
In [60]: L2=L1
In [61]: L1==L2
Out[61]: True
In [62]: L1 is L2
Out[62]: True
In [66]: L1=[1,2,3]
In [67]: L2=[1,2,3]
In [68]: L1==L2
Out[68]: True
In [69]: L1 is L2
Out[69]: False
从上面这个例子就可以看出来,==比较的是值,is 实际比较的是实现引用的指针。
对象的垃圾收集和弱引用
垃圾回收机制也是一件很复杂的事情,但是python编译器可以自己去处理这玩意儿。 所以在初级阶段,我们不需要过多关注这玩意儿。 知道有这么个东西就够了。
这里简单的介绍下,python中的垃圾回收就是我们所谓的GC,靠的是对象的引用计数器。引用计数器为0的时候,这个对象实例就会被释放。对象的引用计数器可以通过sys.getrefcount(istance)来查看。
In [70]: import sys
In [72]: sys.getrefcount(1)
Out[72]: 2719
引用计数器的引入可以很好的跟踪对象的使用情况,但是在某些情况下,也可能会带来问题。 比如循环引用的问题。
如下代码:
In [73]: L =[1,2,3]
In [74]: L.append(L)
当然,正常人肯定不会写出这种智障代码,但是在一些复杂的数据结构中,子对象互相引用,就可能会造成死锁。比如:
In [1]: class Node:
...: def __init__(self):
...: self.parent=None
...: self.child=None
...: def add_child(self,child):
...: self.child=child
...: child.parent=self
...: def __del__(self):
...: print('deleted')
...:
这里我们定义了一个简单的类。这时,如果我们创建一个节点,然后删除它,可以看到,对象被回收,并且准确的打印出了deleted。
In [2]: a=Node()
In [3]: del a
deleted
那么,像下面这个例子,在删除a节点之后,貌似没有触发垃圾回收,只有手动的gc之后,这两个对象实例才被删除。
在删除a之后,没有触发垃圾回收,是因为它俩互相引用,实例的引用计数器并没有置0 。
那在手动gc之后,由于python的gc会检测这种循环引用,并删除它。
In [4]: a=Node()
In [5]: a.add_child(Node())
In [6]: del a
In [7]: import gc
In [8]: gc.collect()
deleted
deleted
Out[8]: 356

那么如果使用弱引用的话,效果就不一样了
In [9]: import weakref
...:
...: class Node:
...: def __init__(self):
...: self.parent=None
...: self.child=None
...: def add_child(self,child):
...: self.child=child
...: child.parent=weakref.ref(self)
...: def __del__(self):
...: print('deleted')
...:
In [10]: a=Node()
In [11]: a.add_child(Node())
In [12]: del a
deleted
deleted
所以这里就可以看出来,所谓弱引用,其实并没有增加对象的引用计数器,即使弱引用存在,垃圾回收器也会当做没看见。
弱引用一般可以拿来做缓存使用,对象存在时可用,对象不存在的时候返回None。这正符合缓存有则使用,无则重新获取的性质。
[python学习手册-笔记]004.动态类型的更多相关文章
- [python学习手册-笔记]003.数值类型
003.数值类型 ❝ 本系列文章是我个人学习<python学习手册(第五版)>的学习笔记,其中大部分内容为该书的总结和个人理解,小部分内容为相关知识点的扩展. 非商业用途转载请注明作者和出 ...
- [python学习手册-笔记]002.python核心数据类型
python核心数据类型 ❝ 本系列文章是我个人学习<python学习手册(第五版)>的学习笔记,其中大部分内容为该书的总结和个人理解,小部分内容为相关知识点的扩展. 非商业用途转载请注明 ...
- [python学习手册-笔记]001.python前言
001.python前言 ❝ 本系列文章是我个人学习<python学习手册(第五版)>的学习笔记,其中大部分内容为该书的总结和个人理解,小部分内容为相关知识点的扩展. 非商业用途转载请注明 ...
- 自学笔记系列:《Python学习手册 第五版》 -写在开始之前
今年双十一,在当当网上买了这本书,很厚很厚的一本书,大概有将近1700页左右,的确是一个“大工程”, 关于这本书的学习,我想采用一种博客的方式进行,既是写给自己,也想分享给每一个对Python学习感兴 ...
- 《Python学习手册》读书笔记
之前为了编写一个svm分词的程序而简单学了下Python,觉得Python很好用,想深入并系统学习一下,了解一些机制,因此开始阅读<Python学习手册(第三版)>.如果只是想快速入门,我 ...
- 《Python学习手册》读书笔记【转载】
转载:http://www.cnblogs.com/wuyuegb2312/archive/2013/02/26/2910908.html 之前为了编写一个svm分词的程序而简单学了下Python,觉 ...
- 转载-《Python学习手册》读书笔记
转载-<Python学习手册>读书笔记 http://www.cnblogs.com/wuyuegb2312/archive/2013/02/26/2910908.html
- 《Python学习手册 第五版》 -第14章 迭代和推导
承接上一章for循环的讲解,迭代和推导,是对for循环的一种深入的探索和扩展 本章重点内容 1.迭代 1)什么是迭代?都有哪些分类 2)常规的使用方法 3)多遍迭代器VS单遍迭代器 2.列表推导 1) ...
- 《Python学习手册 第五版》 -第18章 参数
在函数的定义和调用中,参数是使用最多喝最频繁的,本章内容就是围绕函数的参数进行讲解 本章重点内容如下: 1.参数的传递 1)不可变得参数传递 2)可变得参数传递 2.参数的匹配模式 1)位置次序:从左 ...
随机推荐
- Linux上Mysql数据库 用户权限控制
Linux安装mysql 点我直达 Mysql限制root用户ip地址登录 修改mysql库里边的user表: update mysql.user set host='localhost' where ...
- mysql之用户
1.通过Navicat For Mysql可以查看目前的用户情况 2.创建用户 create user 'Fqq'@'127.0.0.1' IDENTIFIED by '123'; -- 创建一个用户 ...
- Linux(Centos6.8)配置Nginx环境
1.环境配置 操作系统:centos6.8 [root@host79 ~]# uname -a Linux host79.pluto 2.6.32-642.el6.x86_64 #1 SMP Tue ...
- Unity Lod
LOD是Level Of Detais 的简称,多细节层次,根据摄像机与物体距离,unity会自动切换模型.一般离摄像机近的时候显示高模,离摄像机远的时候显示低模,借此来提升性能. 如果你在Blend ...
- 学习Validator验证框架总结
在项目开发中许多地方需要加以验证,对于使用if-else简单粗暴一个一个验证,spring的validation封装了Javax ValidationI校验参数,大大缩减了代码量. 以前的分层验证,从 ...
- 赶紧收藏!这些Java中的流程控制知识你都不知道,你凭什么涨薪?
Java的流程控制 基础阶段 目录: 用户交互Scanner 顺序结构 选择结构 循环结构 break & continue 练习题 1.Scanner对象 之前我们学的基本语法中并没有实现程 ...
- Requests 库的使用
Python 的标准库 urllib 提供了大部分 HTTP 功能,但使用起来较繁琐.通常,我们会使用另外一个优秀的第三方库:Requests,它的标语是:Requests: HTTP for Hum ...
- ECS服务器快速迁移
ECS服务器快速迁移 前提 一.停机 二.创建镜像 三.复制镜像 前提 服务器都在同一个区域,举例:华南1(深圳) 同一个账号 具体迁移步骤如下: 一.停机 先从阿里云ECS控制台,将要迁移的两台EC ...
- D. Circle Game 题解(对称博弈)
题目链接 题目大意 t组数据(t<=100) 给你一个半径d和步数k,你最开始在原点(0,0)每次可以让x坐标增加k,或者y坐标增加k 两人轮流走,求谁最后不能走了,谁就输了,都是最优博弈 输的 ...
- 安装Linux软件时遇到这个问题,如何解决?
提示 Could not get lock /var/lib/dpkg/lock 报错? 有些小伙伴在使用 apt 包管理器更新或安装软件时,可能会遇到过诸如以下的错误提示: E: Could not ...