node爬虫 -- 网页图片
相信大家都听说过爬虫,我们也听说过Python是可以很方便地爬取网络上的图片, 但是奈何本人不会Python,就只有通过 Node 来实践一下了。
 接下来看我如何 板砖 ! !!
接下来看我如何 板砖 ! !!
01 前言
何谓爬虫
其实爬虫用很官方的语言来描述就是“自动化浏览网络程序”,我们不用手动去点击、去下载一些文章或者图片。大家或许用过抢票软件,其实就是不断地通过软件访问铁路官方的接口,达到抢票的效果。但是,这类抢票软件是违法的。
那么怎么判断爬虫是不是违法呢?关于爬虫是否非法其实没有很明确的说法,一直都是中立的态度。爬虫是一种技术,技术本身没有违法的。但是你使用这种技术去爬取不正当的信息、有版权的图片等用于商用,那么你就是违法了。其实我们只要在使用爬虫技术的时候不要去爬个人隐私信息,不要爬取有版权的图片,最重要的是信息不要用于商业化的行为,爬虫不得干扰网站的正常运行等。
说了这么多其实就是要大家谨慎使用这一项技术。
02 Node 基本思路
怎么爬
一:首先我们用的模块有以下几个:
- http || https ( 记不清的请点击 node官网 https://nodejs.org/dist/latest-v15.x/docs/api/http2.html)
- cheerio ( node 模块,和前端 jq用法 基本一摸一样 )
- download ( 下载图片 模块 )
二:基本思路
1. 示例网址 :https://view.inews.qq.com/w2/20200820A0AZTM00
2.通过 F12 查看 网页结构
1) 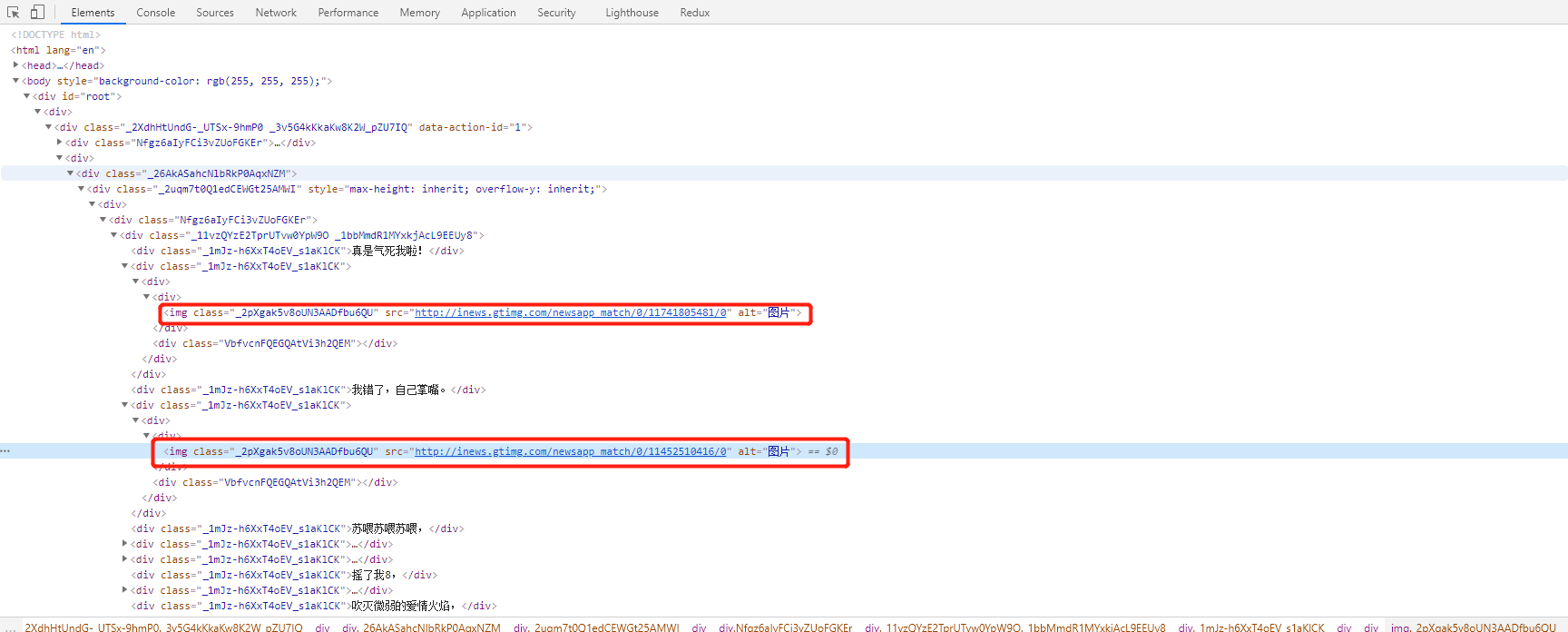
2) 查询网页规律 div > img
3.右键 查看网页源码源代码
1) 如果源代码 和 网页内容一样,基本是服务端渲染
a. 通过cheerio 模块,直接操作,获取dom
2) 如果源代码 和 网页内容不一样,基本是前端渲染
a. 需要查看 network 的XHR,返回的json数据
4. 下载图片
1)通过request 获取网页内容
2)cheerio 转换,获取页面内容
3)通过 download () 加载每一条 img src 的网络请求,保存到本地
03 Node 贴代码
let https = require('https'); // https 安全协议请求
let fs = require('fs'); // fs 文件读写模块, 未用到,可以忽略。
let cheerio = require('cheerio'); // cheerio 获取的数据转换 为 html 模块
let download = require('download'); // 下载 图片的 模块
let url = 'https://view.inews.qq.com/w2/20200820A0AZTM00'; // 测试地址
// 函数内部的 步骤
function http_request (url) {
// 1. https.request() 只是创建请求 ,没有发送请求
// 2. app.end() 调用实例对象end() 方法才会发送请求. ( 看倒数第三行)
// 3. res.on('data',()=>{}) 获取网页data ,存入一个数组 chunks
// 4. res.on('end',()=>{}) ( 看 具体 步骤)
let app = https.request(url, res => {
let chunks = [];
res.on('data', chunk => {
chunks.push(chunk)
})
res.on('end', () => {
let html = Buffer.concat(chunks).toString('utf-8'); //获取到的data ,是buffer 。 需要通过 Buffer.concat(数组).tostring('utf-8') 转换为 我们认识的html 文档
let $ = cheerio.load(html); // cheerio.load() 像使用jquery 使用方式一样
let imgArr = Array.prototype.map.call($('.random_picture a img'), (item) => $(item).data('backup')); // $('').arrr('') 像jq一样获取 img 的src,存入一个数组。
let check = imgArr.filter((item, index, arr) => { // 有些网页img src 未加载成功,所以,filter 过滤掉 值 == undefined
return item != undefined
})
Promise.all(check.map(x => download(x, 'zhinan' + i))).then((res) => { // promise.all( x =>download( x, '保存文件的name' )) promisr.all 发送多个异步请求,
// download( ) ,第一个参数:当前请求的 x ,就是数组每一项,第二个参数: 当前保存文件的 名字
console.log('success file', check.length)
}).catch((err) => {
console.log(err)
})
})
})
app.end();
}
http_request(url)
node爬虫 -- 网页图片的更多相关文章
- java简单web爬虫(网页图片)
java简单web爬虫(网页图片)效果,执行main()方法后图片就下载道C盘的res文件夹中.没有的话创建一个文件夹代码里的常量根据自己的需求修改,代码附到下面. package com.sinit ...
- Python爬虫 网页图片
一 概述 参考http://www.cnblogs.com/abelsu/p/4540711.html 弄了个Python捉取单一网页的图片,但是Python已经升到3+版本了.参考的已经失效,基本用 ...
- node爬虫之图片下载
背景:针对一些想换头像的玩家,而又不知道用什么头像的,作为一名代码爱好者,能用程序解决的,就不用程序来换头像,说干就干,然后就整理了一下. 效果图 环境配置 安装node环境 node -v node ...
- node:爬虫爬取网页图片
代码地址如下:http://www.demodashi.com/demo/13845.html 前言 周末自己在家闲着没事,刷着微信,玩着手机,发现自己的微信头像该换了,就去网上找了一下头像,看着图片 ...
- Node.js 网页爬虫再进阶,cheerio助力
任务还是读取博文标题. 读取app2.js // 内置http模块,提供了http服务器和客户端功能 var http=require("http"); // cheerio模块, ...
- Node.js 网页瘸腿稍强点爬虫再体验
这回爬虫走得好点了,每次正常读取文章数目总是一样的,但是有程序僵住了情况,不知什么原因. 代码如下: // 内置http模块,提供了http服务器和客户端功能 var http=require(&qu ...
- Node.js 网页瘸腿爬虫初体验
延续上一篇,想把自己博客的文档标题利用Node.js的request全提取出来,于是有了下面的初哥爬虫,水平有限,这只爬虫目前还有点瘸腿,请看官你指正了. // 内置http模块,提供了http服务器 ...
- Python爬虫之网页图片抓取
一.引入 这段时间一直在学习Python的东西,以前就听说Python爬虫多厉害,正好现在学到这里,跟着小甲鱼的Python视频写了一个爬虫程序,能实现简单的网页图片下载. 二.代码 __author ...
- Python3简单爬虫抓取网页图片
现在网上有很多python2写的爬虫抓取网页图片的实例,但不适用新手(新手都使用python3环境,不兼容python2), 所以我用Python3的语法写了一个简单抓取网页图片的实例,希望能够帮助到 ...
随机推荐
- Windows10自带截屏快捷键
Windows10自带截屏快捷键使用方法大全我们知道,QQ和微信以及第三方浏览器等软件都支持截图功能,但是这个都是基于软件的一个功能,如果我们不打开这些软件的话,就不能实现截图功能,但其实window ...
- Python 学习笔记 之 03 - 函数总结
函数总结 最基本的一种代码抽象的方式. 定义函数 使用def语句进行定义, return进行函数返回. 一旦执行导return,函数就执行完毕. 即使函数未指定retur ...
- Jmeter连接redis
介绍:现在有很多数据不是存储在数据库而是存储在Redis中 Redis数据库存储数据环境 不用每次都去数据库读取数据 可以有效的优化服务器性能. 下面介绍使用jmeter如何读取redis 一.首先创 ...
- HDU4388-Stone Game II-Nim变形
http://acm.hdu.edu.cn/showproblem.php?pid=4388 Nim变形,对一个\(n\)个石子的堆,每次取\(k(0<k<n)\)个(注意不能全取光),同 ...
- RocketMQ源码分析 broker启动,commitlog、consumequeue、indexfile、MappedFileQueue、MappedFile之间的关系以及位置说明
目录 1.MappedFile类属性说明 1.1.MappedFile类属性如下 1.2.MappedFile构造器说明 2.MappedFileQueue类说明 2.1.属性说明 2.2.Mappe ...
- Python之格式化unix时间戳
就瞎倒腾,格式化时间: 1 import time 2 3 unixTime = time.time() #定义unixTime以存储系统当前的unix时间戳 4 print(unixTime); # ...
- 每天学习一点ES6(二)let 和 const
let 命令 let 和 var 差不多,只是限制了有效范围. 先定义后使用 不管是什么编程语言,不管语法是否允许,都要秉承先定义,然后再使用的习惯,这样不会出幺蛾子.以前JavaScript比较随意 ...
- python列表(九)元组
元组 元组是不可变序列,元组一旦创建,用任何方法都不可以修改其元素. 元组的偶有元素是放在一对圆括号"()"中 1.元组创建与删除 使用"="讲一个元组赋值给变 ...
- PhPMyadmin拿Shell
phpmyadmin 是一个以PHP为基础,以Web-Base方式架构在网站主机上的MySQL的数据库管理工具, --百度百科 1.入口寻找 目录扫描: 根据Linux对大小写敏感判断目标服 ...
- [Python] iupdatable包:Timer 类使用介绍
iudatable包是我对常用函数进行的封装后发布的一个python包,教程汇总目录: [Python] iupdatable包使用说明 安装 iupdatable 包 pip install iup ...