Flink的sink实战之二:kafka
欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
本篇概览
本文是《Flink的sink实战》系列的第二篇,前文《Flink的sink实战之一:初探》对sink有了基本的了解,本章来体验将数据sink到kafka的操作;
全系列链接
版本和环境准备
本次实战的环境和版本如下:
- JDK:1.8.0_211
- Flink:1.9.2
- Maven:3.6.0
- 操作系统:macOS Catalina 10.15.3 (MacBook Pro 13-inch, 2018)
- IDEA:2018.3.5 (Ultimate Edition)
- Kafka:2.4.0
- Zookeeper:3.5.5
请确保上述环境和服务已经就绪;
源码下载
如果您不想写代码,整个系列的源码可在GitHub下载到,地址和链接信息如下表所示(https://github.com/zq2599/blog_demos):
| 名称 | 链接 | 备注 |
|---|---|---|
| 项目主页 | https://github.com/zq2599/blog_demos | 该项目在GitHub上的主页 |
| git仓库地址(https) | https://github.com/zq2599/blog_demos.git | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | git@github.com:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
这个git项目中有多个文件夹,本章的应用在flinksinkdemo文件夹下,如下图红框所示:
准备完毕,开始开发;
准备工作
正式编码前,先去官网查看相关资料了解基本情况:
- 地址:https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/connectors/kafka.html
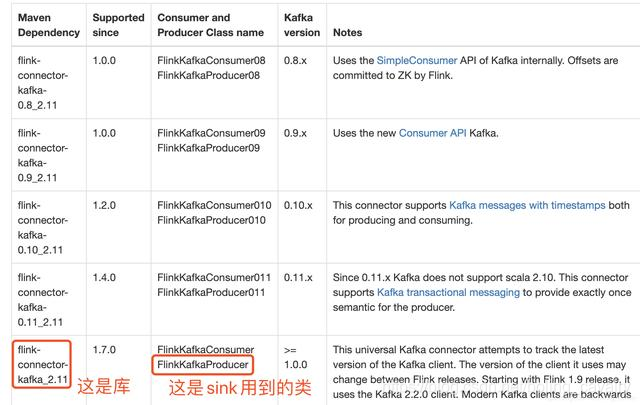
- 我这里用的kafka是2.4.0版本,在官方文档查找对应的库和类,如下图红框所示:
kafka准备
- 创建名为test006的topic,有四个分区,参考命令:
./kafka-topics.sh \
--create \
--bootstrap-server 127.0.0.1:9092 \
--replication-factor 1 \
--partitions 4 \
--topic test006
- 在控制台消费test006的消息,参考命令:
./kafka-console-consumer.sh \
--bootstrap-server 127.0.0.1:9092 \
--topic test006
- 此时如果该topic有消息进来,就会在控制台输出;
- 接下来开始编码;
创建工程
- 用maven命令创建flink工程:
mvn \
archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.9.2
- 根据提示,groupid输入com.bolingcavalry,artifactid输入flinksinkdemo,即可创建一个maven工程;
- 在pom.xml中增加kafka依赖库:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.9.0</version>
</dependency>
- 工程创建完成,开始编写flink任务的代码;
发送字符串消息的sink
先尝试发送字符串类型的消息:
- 创建KafkaSerializationSchema接口的实现类,后面这个类要作为创建sink对象的参数使用:
package com.bolingcavalry.addsink;
import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.nio.charset.StandardCharsets;
public class ProducerStringSerializationSchema implements KafkaSerializationSchema<String> {
private String topic;
public ProducerStringSerializationSchema(String topic) {
super();
this.topic = topic;
}
@Override
public ProducerRecord<byte[], byte[]> serialize(String element, Long timestamp) {
return new ProducerRecord<byte[], byte[]>(topic, element.getBytes(StandardCharsets.UTF_8));
}
}
- 创建任务类KafkaStrSink,请注意FlinkKafkaProducer对象的参数,FlinkKafkaProducer.Semantic.EXACTLY_ONCE表示严格一次:
package com.bolingcavalry.addsink;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
public class KafkaStrSink {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//并行度为1
env.setParallelism(1);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "192.168.50.43:9092");
String topic = "test006";
FlinkKafkaProducer<String> producer = new FlinkKafkaProducer<>(topic,
new ProducerStringSerializationSchema(topic),
properties,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE);
//创建一个List,里面有两个Tuple2元素
List<String> list = new ArrayList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
list.add("ddd");
list.add("eee");
list.add("fff");
list.add("aaa");
//统计每个单词的数量
env.fromCollection(list)
.addSink(producer)
.setParallelism(4);
env.execute("sink demo : kafka str");
}
}
- 使用mvn命令编译构建,在target目录得到文件flinksinkdemo-1.0-SNAPSHOT.jar;
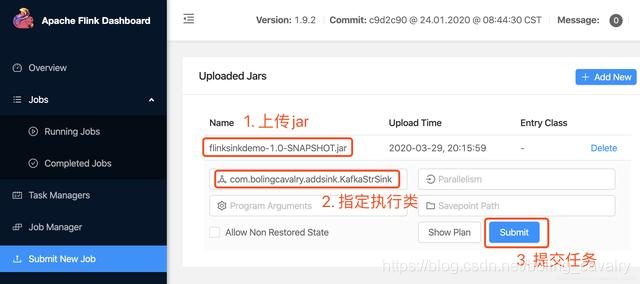
- 在flink的web页面提交flinksinkdemo-1.0-SNAPSHOT.jar,并制定执行类,如下图:
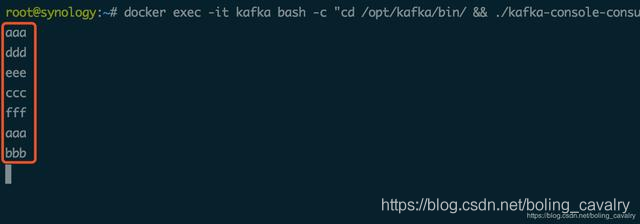
- 提交成功后,如果flink有四个可用slot,任务会立即执行,会在消费kafak消息的终端收到消息,如下图:
- 任务执行情况如下图:
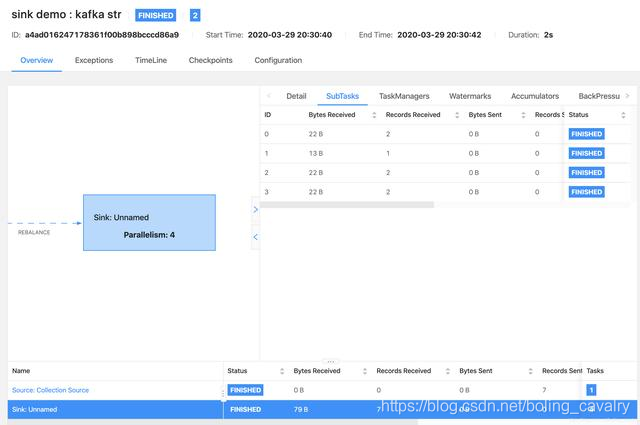
发送对象消息的sink
再来尝试如何发送对象类型的消息,这里的对象选择常用的Tuple2对象:
- 创建KafkaSerializationSchema接口的实现类,该类后面要用作sink对象的入参,请注意代码中捕获异常的那段注释:生产环境慎用printStackTrace()!!!
package com.bolingcavalry.addsink;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.core.JsonProcessingException;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;
import org.apache.kafka.clients.producer.ProducerRecord;
import javax.annotation.Nullable;
public class ObjSerializationSchema implements KafkaSerializationSchema<Tuple2<String, Integer>> {
private String topic;
private ObjectMapper mapper;
public ObjSerializationSchema(String topic) {
super();
this.topic = topic;
}
@Override
public ProducerRecord<byte[], byte[]> serialize(Tuple2<String, Integer> stringIntegerTuple2, @Nullable Long timestamp) {
byte[] b = null;
if (mapper == null) {
mapper = new ObjectMapper();
}
try {
b= mapper.writeValueAsBytes(stringIntegerTuple2);
} catch (JsonProcessingException e) {
// 注意,在生产环境这是个非常危险的操作,
// 过多的错误打印会严重影响系统性能,请根据生产环境情况做调整
e.printStackTrace();
}
return new ProducerRecord<byte[], byte[]>(topic, b);
}
}
- 创建flink任务类:
package com.bolingcavalry.addsink;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
public class KafkaObjSink {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//并行度为1
env.setParallelism(1);
Properties properties = new Properties();
//kafka的broker地址
properties.setProperty("bootstrap.servers", "192.168.50.43:9092");
String topic = "test006";
FlinkKafkaProducer<Tuple2<String, Integer>> producer = new FlinkKafkaProducer<>(topic,
new ObjSerializationSchema(topic),
properties,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE);
//创建一个List,里面有两个Tuple2元素
List<Tuple2<String, Integer>> list = new ArrayList<>();
list.add(new Tuple2("aaa", 1));
list.add(new Tuple2("bbb", 1));
list.add(new Tuple2("ccc", 1));
list.add(new Tuple2("ddd", 1));
list.add(new Tuple2("eee", 1));
list.add(new Tuple2("fff", 1));
list.add(new Tuple2("aaa", 1));
//统计每个单词的数量
env.fromCollection(list)
.keyBy(0)
.sum(1)
.addSink(producer)
.setParallelism(4);
env.execute("sink demo : kafka obj");
}
}
- 像前一个任务那样编译构建,把jar提交到flink,并指定执行类是com.bolingcavalry.addsink.KafkaObjSink;
- 消费kafka消息的控制台输出如下:
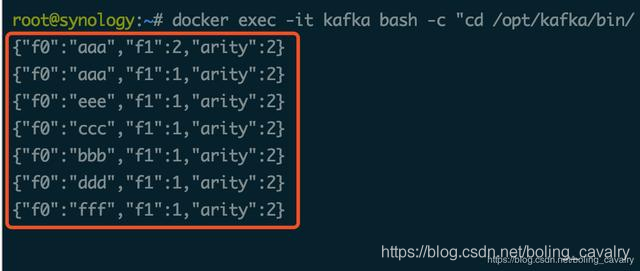
- 在web页面可见执行情况如下:

至此,flink将计算结果作为kafka消息发送出去的实战就完成了,希望能给您提供参考,接下来的章节,我们会继续体验官方提供的sink能力;
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界...
https://github.com/zq2599/blog_demos
Flink的sink实战之二:kafka的更多相关文章
- Flink的sink实战之一:初探
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink的sink实战之三:cassandra3
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink的sink实战之四:自定义
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink处理函数实战之二:ProcessFunction类
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink处理函数实战之三:KeyedProcessFunction类
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink处理函数实战之四:窗口处理
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink 从0到1学习—— 分享四本 Flink 国外的书和二十多篇 Paper 论文
前言 之前也分享了不少自己的文章,但是对于 Flink 来说,还是有不少新入门的朋友,这里给大家分享点 Flink 相关的资料(国外数据 pdf 和流处理相关的 Paper),期望可以帮你更好的理解 ...
- Flink的DataSource三部曲之二:内置connector
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink处理函数实战之五:CoProcessFunction(双流处理)
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
随机推荐
- 在 Visual Studio 中创建一个简单的 C# 控制台应用程序
转载:https://blog.csdn.net/qq_43994242/article/details/87260824 快速入门:使用 Visual Studio 创建第一个 C# 控制台应用 h ...
- Jmeter之『Xpath提取器』
1.使用Xpath提取时,有时候需要过滤标题,使用以下语句 //td[@class="r-count" and not(text()="回应")]
- windows上启动docker容器报错:standard_init_linux.go:211: exec user process caused “no such file or directory” - Docker
解决方案: standard_init_linux.go:190: exec user process caused "no such file or directory" - D ...
- 学习WebDav
目录 前言 初识WebDav 有哪些支持webdav的网盘? WebDAV的特性和优势 服务端的搭建 调用WebDav接口 PROPFIND方法 PROPPATCH方法 MKCOL方法 PUT方法 G ...
- 《流畅的Python》第二部分 数据结构 【序列构成的数组】【字典和集合】【文本和字节序列】
第二部分 数据结构 第2章 序列构成的数组 内置序列类型 序列类型 序列 特点 容器序列 list.tuple.collections.deque - 能存放不同类型的数据:- 存放的是任意类型的对象 ...
- CDH5部署三部曲之一:准备工作
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- DBA提交脚步规范
工作中需要走脚步流程,申请修改数据库,总结一些常用的语句:)提交时注明为DDL/DML_需求号_日期(各公司标准不一样)//修改字段长度使用;alter table t_task modify tas ...
- 为什么在M3架构中 PC总是返回加4
由于CPU是3级流水线的方式运行.在执行第一条指令时候,已经对第二条指令译码,对第三条指令取值. PC总是指向正在取值的指令.由于在M3架构中,采用Thumb-2指令,每个指令占据2个字节,所以PC总 ...
- java 的 callback
Java 本身没有回调这一说,但是面向对象可以模拟出来. 1. 回调接口对象 ICommand package com.git.Cmder; public interface ICommand { v ...
- 多测师讲解接口测试 _windows中搭建环境cms_高级讲师肖sir
eclipse集成开发环境 搭建开发环境需要安装的工具如下 jdk-8u60-windows-x64.exe jdk eclipse.rar 集成开发框架 mysql-inst ...