hive 存储格式及压缩
-- 设置参数
set hivevar:target_db_name=db_dw;
use ${hivevar:target_db_name}; -- 创建textfile表
create table file_format_textfile
row format delimited fields terminated by '\001'
stored as textfile
as
select * from smple_table; -- 测试各种压缩的orc表
create table file_format_orc_zlib
row format delimited fields terminated by '\001'
stored as orc tblproperties ("orc.compress"="ZLIB")
as
select * from file_format_textfile
; create table file_format_orc_snappy
row format delimited fields terminated by '\001'
stored as orc tblproperties ("orc.compress"="SNAPPY")
as
select * from file_format_orc_zlib
; create table file_format_orc_none
row format delimited fields terminated by '\001'
stored as orc tblproperties ("orc.compress"="NONE")
as
select * from file_format_orc_zlib
; create table file_format_orc_default
row format delimited fields terminated by '\001'
stored as orc
as
select * from file_format_orc_zlib
; -- 测试各种压缩的parquet表
create table file_format_parquet_zlib
row format delimited fields terminated by '\001'
stored as parquet tblproperties ("parquet.compress"="ZLIB")
as
select * from file_format_orc_zlib
; create table file_format_parquet_snappy
row format delimited fields terminated by '\001'
stored as parquet tblproperties ("parquet.compress"="SNAPPY")
as
select * from file_format_orc_zlib
; create table file_format_parquet_none
row format delimited fields terminated by '\001'
stored as parquet tblproperties ("parquet.compress"="NONE")
as
select * from file_format_orc_zlib
; create table file_format_parquet_default
row format delimited fields terminated by '\001'
stored as parquet
as
select * from file_format_orc_zlib
; -- 测试各种压缩的rcfile表(可能参数没生效,各种压缩后大小一致)
create table file_format_rcfile_zlib
row format delimited fields terminated by '\001'
stored as rcfile tblproperties ("rcfile.compress"="ZLIB")
as
select * from file_format_orc_zlib
; create table file_format_rcfile_snappy
row format delimited fields terminated by '\001'
stored as rcfile tblproperties ("rcfile.compress"="SNAPPY")
as
select * from file_format_orc_zlib
; create table file_format_rcfile_none
row format delimited fields terminated by '\001'
stored as rcfile tblproperties ("rcfile.compress"="NONE")
as
select * from file_format_orc_zlib
; create table file_format_rcfile_default
row format delimited fields terminated by '\001'
stored as rcfile
as
select * from file_format_orc_zlib
;
-- 查看各种压缩下的格式大小
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_textfile; dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_orc_zlib;
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_orc_snappy;
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_orc_none;
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_orc_default; dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_parquet_zlib;
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_parquet_snappy;
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_parquet_none;
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_parquet_default; dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_rcfile_zlib;
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_rcfile_snappy;
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_rcfile_none;
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_rcfile_default;
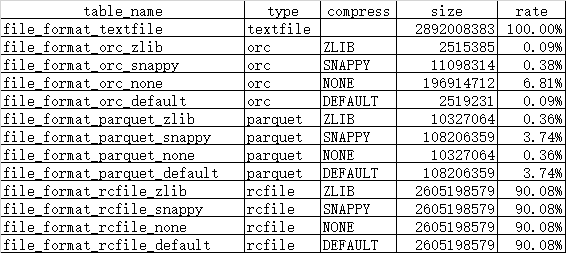
-- 统计数据,原文件见文件中的附件
hive 存储格式及压缩的更多相关文章
- Hive存储格式之RCFile详解,RCFile的过去现在和未来
我在整理Hive的存储格式和压缩格式,本来打算一篇发出来,结果其中一小节就有很多内容,于是打算写成Hive存储格式和压缩格式系列. 本节主要讲一下Hive存储格式最早的典型的列式存储格式RCFile. ...
- Hive存储格式之ORC File详解,什么是ORC File
目录 概述 文件存储结构 Stripe Index Data Row Data Stripe Footer 两个补充名词 Row Group Stream File Footer 条纹信息 列统计 元 ...
- Hadoop、Hive【LZO压缩配置和使用】
目录 一.编译 二.相关配置 三.为LZO文件创建索引 四.Hive为LZO文件建立索引 1.hive创建的lzo压缩的分区表 2.给.lzo压缩文件建立索引index 3.读取Lzo文件的注意事项( ...
- Hive性能调优(一)----文件存储格式及压缩方式选择
合理使用文件存储格式 建表时,尽量使用 orc.parquet 这些列式存储格式,因为列式存储的表,每一列的数据在物理上是存储在一起的,Hive查询时会只遍历需要列数据,大大减少处理的数据量. 采用合 ...
- hive 存储格式对比
Apache Hive支持Apache Hadoop中使用的几种熟悉的文件格式,如TextFile,RCFile,SequenceFile,AVRO,ORC和Parquet格式. Cloudera I ...
- Hive(十一)【压缩、存储】
目录 一.Hadoop的压缩配置 1.MR支持的压缩编码 2.压缩参数配置 3.开启Mapper输出阶段压缩 4.开启Reduceer输出阶段 二.文件存储 1.列式存储和行式存储 2.TextFil ...
- hive 存储格式
hive有textFile,SequenceFile,RCFile三种文件格式. textfile为默认格式,建表时不指定默认为这个格式,导入数据时会直接把数据文件拷贝到hdfs上不进行处理. Seq ...
- hive表的存储格式; ORC格式的使用
hive表的源文件存储格式有几类: 1.TEXTFILE 默认格式,建表时不指定默认为这个格式,导入数据时会直接把数据文件拷贝到hdfs上不进行处理.源文件可以直接通过hadoop fs -cat 查 ...
- Hive文件存储格式和hive数据压缩
一.存储格式行存储和列存储 二.Hive文件存储格式 三.创建语句和压缩 一.存储格式行存储和列存储 行存储可以理解为一条记录存储一行,通过条件能够查询一整行数据. 列存储,以字段聚集存储,可以理解为 ...
随机推荐
- [poj2976]Dropping tests(01分数规划,转化为二分解决或Dinkelbach算法)
题意:有n场考试,给出每场答对的题数a和这场一共有几道题b,求去掉k场考试后,公式.的最大值 解题关键:01分数规划,double类型二分的写法(poj崩溃,未提交) 或者r-l<=1e-3(右 ...
- NLTK词性标注解释
1. CC Coordinating conjunction 连接词2. CD Cardinal number 基数词3. DT Determin ...
- 大话设计模式--Python
作者:五岳 出处:http://www.cnblogs.com/wuyuegb2312 上一周把<大话设计模式>看完了,对面向对象技术有了新的理解,对于一个在C下写代码比较多.偶尔会用到一 ...
- 获取当前设备的CPU个数
public class Test { public static void main(String[] args) { //获取当前设备的CPU个数 int availableProcessors ...
- ruby 数组与散列
def say_goodnight(name) result ="Good night ." +name return result end def say_goodmorning ...
- Ubuntu 添加用户到sudoers
ubuntu上的用户有时候需要用到管理员权限,可以通过修改 /etc/sudoers 文件内容添加用户权限. 操作方式 1. 首先以root进入系统打开文件 sudo vim /etc/sudoers ...
- clone方法详解
http://blog.csdn.net/zhangjg_blog/article/details/18369201/
- kaggle Data Leakage
What is Data Leakage¶ Data leakage is one of the most important issues for a data scientist to under ...
- 开启wifi后不能ping通本机 Cann't ping the local PC while start a wlan
问题如题:今天发现一个问题,测试本机ip时候有时候总是获取失败,后来才发现是wifi共享软件导致的缘故. 本来呢?我买的是小米wifi,但是小米wifi对应的客户端不是很好用,动不动就启动失败,不要问 ...
- 二维码的生成细节和原理 -- 转http://news.cnblogs.com/n/191671/
二维码又称 QR Code,QR 全称 Quick Response,是一个近几年来移动设备上超流行的一种编码方式,它比传统的 Bar Code 条形码能存更多的信息,也能表示更多的数据类型:比如:字 ...