hive 存储格式及压缩
-- 设置参数
set hivevar:target_db_name=db_dw;
use ${hivevar:target_db_name}; -- 创建textfile表
create table file_format_textfile
row format delimited fields terminated by '\001'
stored as textfile
as
select * from smple_table; -- 测试各种压缩的orc表
create table file_format_orc_zlib
row format delimited fields terminated by '\001'
stored as orc tblproperties ("orc.compress"="ZLIB")
as
select * from file_format_textfile
; create table file_format_orc_snappy
row format delimited fields terminated by '\001'
stored as orc tblproperties ("orc.compress"="SNAPPY")
as
select * from file_format_orc_zlib
; create table file_format_orc_none
row format delimited fields terminated by '\001'
stored as orc tblproperties ("orc.compress"="NONE")
as
select * from file_format_orc_zlib
; create table file_format_orc_default
row format delimited fields terminated by '\001'
stored as orc
as
select * from file_format_orc_zlib
; -- 测试各种压缩的parquet表
create table file_format_parquet_zlib
row format delimited fields terminated by '\001'
stored as parquet tblproperties ("parquet.compress"="ZLIB")
as
select * from file_format_orc_zlib
; create table file_format_parquet_snappy
row format delimited fields terminated by '\001'
stored as parquet tblproperties ("parquet.compress"="SNAPPY")
as
select * from file_format_orc_zlib
; create table file_format_parquet_none
row format delimited fields terminated by '\001'
stored as parquet tblproperties ("parquet.compress"="NONE")
as
select * from file_format_orc_zlib
; create table file_format_parquet_default
row format delimited fields terminated by '\001'
stored as parquet
as
select * from file_format_orc_zlib
; -- 测试各种压缩的rcfile表(可能参数没生效,各种压缩后大小一致)
create table file_format_rcfile_zlib
row format delimited fields terminated by '\001'
stored as rcfile tblproperties ("rcfile.compress"="ZLIB")
as
select * from file_format_orc_zlib
; create table file_format_rcfile_snappy
row format delimited fields terminated by '\001'
stored as rcfile tblproperties ("rcfile.compress"="SNAPPY")
as
select * from file_format_orc_zlib
; create table file_format_rcfile_none
row format delimited fields terminated by '\001'
stored as rcfile tblproperties ("rcfile.compress"="NONE")
as
select * from file_format_orc_zlib
; create table file_format_rcfile_default
row format delimited fields terminated by '\001'
stored as rcfile
as
select * from file_format_orc_zlib
;
-- 查看各种压缩下的格式大小
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_textfile; dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_orc_zlib;
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_orc_snappy;
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_orc_none;
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_orc_default; dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_parquet_zlib;
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_parquet_snappy;
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_parquet_none;
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_parquet_default; dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_rcfile_zlib;
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_rcfile_snappy;
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_rcfile_none;
dfs -du -s /user/hive/warehouse/${hivevar:target_db_name}.db/file_format_rcfile_default;
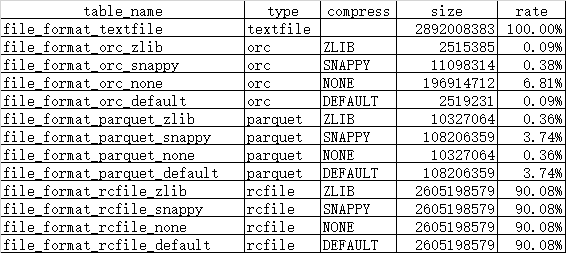
-- 统计数据,原文件见文件中的附件
hive 存储格式及压缩的更多相关文章
- Hive存储格式之RCFile详解,RCFile的过去现在和未来
我在整理Hive的存储格式和压缩格式,本来打算一篇发出来,结果其中一小节就有很多内容,于是打算写成Hive存储格式和压缩格式系列. 本节主要讲一下Hive存储格式最早的典型的列式存储格式RCFile. ...
- Hive存储格式之ORC File详解,什么是ORC File
目录 概述 文件存储结构 Stripe Index Data Row Data Stripe Footer 两个补充名词 Row Group Stream File Footer 条纹信息 列统计 元 ...
- Hadoop、Hive【LZO压缩配置和使用】
目录 一.编译 二.相关配置 三.为LZO文件创建索引 四.Hive为LZO文件建立索引 1.hive创建的lzo压缩的分区表 2.给.lzo压缩文件建立索引index 3.读取Lzo文件的注意事项( ...
- Hive性能调优(一)----文件存储格式及压缩方式选择
合理使用文件存储格式 建表时,尽量使用 orc.parquet 这些列式存储格式,因为列式存储的表,每一列的数据在物理上是存储在一起的,Hive查询时会只遍历需要列数据,大大减少处理的数据量. 采用合 ...
- hive 存储格式对比
Apache Hive支持Apache Hadoop中使用的几种熟悉的文件格式,如TextFile,RCFile,SequenceFile,AVRO,ORC和Parquet格式. Cloudera I ...
- Hive(十一)【压缩、存储】
目录 一.Hadoop的压缩配置 1.MR支持的压缩编码 2.压缩参数配置 3.开启Mapper输出阶段压缩 4.开启Reduceer输出阶段 二.文件存储 1.列式存储和行式存储 2.TextFil ...
- hive 存储格式
hive有textFile,SequenceFile,RCFile三种文件格式. textfile为默认格式,建表时不指定默认为这个格式,导入数据时会直接把数据文件拷贝到hdfs上不进行处理. Seq ...
- hive表的存储格式; ORC格式的使用
hive表的源文件存储格式有几类: 1.TEXTFILE 默认格式,建表时不指定默认为这个格式,导入数据时会直接把数据文件拷贝到hdfs上不进行处理.源文件可以直接通过hadoop fs -cat 查 ...
- Hive文件存储格式和hive数据压缩
一.存储格式行存储和列存储 二.Hive文件存储格式 三.创建语句和压缩 一.存储格式行存储和列存储 行存储可以理解为一条记录存储一行,通过条件能够查询一整行数据. 列存储,以字段聚集存储,可以理解为 ...
随机推荐
- css知多少(10)——display(转)
css知多少(10)——display 1. 引言 网页的所有元素,除了“块”就是“流”,而且“流”都是包含在“块”里面的(最外层的body就是一个“块”).在本系列一开始讲<浏览器默认样式 ...
- v8垃圾回收和js垃圾回收机制
垃圾回收器是一把十足的双刃剑.好处是简化程序的内存管理,内存管理无需程序员来操作,由此也减少了长时间运转的程序的内存泄漏.然而无法预期的停顿,影响了交互体验.本文从 V8 (node.js runti ...
- vue 之 计算属性和侦听器
计算属性 模板内的表达式非常便利,但是设计它们的初衷是用于简单运算的.在模板中放入太多的逻辑会让模板过重且难以维护.例如: <div> {{ message.split('').rever ...
- struts1和struts2之间的区别
从action类上分析:1.Struts1要求Action类继承一个抽象基类.Struts1的一个普遍问题是使用抽象类编程而不是接口. 2. Struts 2 Action类可以实现一个Action接 ...
- Xshell连接不上Linux的解决方法
xshell连接linux主机时,会出现错误:Could not connect to '127.0.0.1' (port 22): Connection failed. 但是这时能ping通. 通 ...
- iOS应用推荐
RSS阅读器 Inoreader ***客户端 SuperWingy OpenWingy(已下架) 书签 Pocket 语音备忘录 Voice-Memos 编程语言学习 SoloLearn 社交 Tw ...
- adb 无法调试的问题,ADB server didn't ACK,* failed to start daemon *
The connection to adb is down, and a severe error has occured. You must restart adb and Eclipse. Ple ...
- blkid找不到需要的uuid
记录: blkid找不到需要的uuid,需要格式化后才有
- Docker-教程(一)CentOS Docker 安装
Docker支持以下的CentOS版本: CentOS 7 (64-bit) CentOS 6.5 (64-bit) 或更高的版本 前提条件 目前,CentOS 仅发行版本中的内核支持 Docker. ...
- java 学习第三篇if判断
JAVA 判断 单词: if 如果 else 否则 单分支: If(条件) { 代码块 } If是一个判断语句.代码格式如上. If括号的内是表达式.如果表达式值是成立的便执行代码块.之后在执行IF语 ...