Centos6.10搭建Hadoop三节点分布式
(一)安装JDK
1. 下载JDK,解压到相应的路径
2. 修改 /etc/profile 文件(文本末尾添加),保存
sudo vi /etc/profile
# 配置 JAVA_HOME
export JAVA_HOME=/home/komean/workspace/JDK/jdk1.8.0_181
export CLASSPATH=.:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar # 设置PATH
export PATH=${JAVA_HOME}/bin:$PATH:
3. 让修改后的配置立即生效
# 让修改的配置立即生效
source /etc/profile

(二)初步搭建Hadoop
1. 下载hadoop-2.7.7.tar.gz,解压到相应的路径下
2. 修改 hadoop-2.7.7/etc/hadoop 路径下的:slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 、mapred-env.sh、hadoop-env.sh、yarn-env.sh
(1)文件 slaves,将作为 DataNode 的主机名写入该文件,每行一个,默认为 localhost,所以在伪分布式配置时,节点即作为 NameNode 也作为 DataNode。分布式配置可以保留 localhost,也可以删掉,让 Master 节点仅作为 NameNode 使用。
localhost
slave1
slave2
(2)文件 core-site.xml 改为下面的配置:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/komean/workspace/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
(3)文件 hdfs-site.xml,dfs.replication 一般少于节点数,所以这里 dfs.replication 的值还是设为 2:
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/komean/workspace/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/komean/workspace/hadoop/tmp/dfs/data</value>
</property>
</configuration>
(4)文件 mapred-site.xml ,需要先拷贝mapred-site.xml.template:
cp mapred-site.xml.template mapred-site.xml
然后mapred-site.xml配置修改如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
(5)文件 yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
(6)mapred-env.sh、hadoop-env.sh、yarn-env.sh 文件 修改相应的JAVA_HOME
export JAVA_HOME=/home/komean/workspace/JDK/jdk1.8.0_181
3. 修改 /etc/profile 文件(文本末尾添加),保存
# set JAVA_HOME
export JAVA_HOME=/home/komean/workspace/JDK/jdk1.8.0_181
export CLASSPATH=.:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar # set HADOOP_HOME
export HADOOP_HOME=/home/komean/workspace/hadoop/hadoop-2.7.7
export PATH=${JAVA_HOME}/bin:$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
让修改后的配置立即生效
# 让修改的配置立即生效
source /etc/profile
(三)克隆两台节点虚拟机
192.168.105.25 slave1
192.168.105.35 slave2
(1)配置IP (保持在一个网段下)(参照虚拟机中CentoOs配置ip且连网 第4点)
(2)修改 /etc/hosts 文件 (注意:克隆的,第一个是localhost.localdomain,重复了,修改为localhost)
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.105.15 master
192.168.105.25 slave1
192.168.105.35 slave2
(四)配置SSH无密登录
1. 安装SSH(所有节点都需要)
# 安装
sudo yum install openssh-server
# 重启
service sshd restart
2. 对master节点生成密钥对(只是master节点)运行 ssh-keygen -t rsa 后,不要输入密码,回车
# 生产密钥
cd .ssh
ssh-keygen -t rsa
# 将公钥id_rsa.pub追加到授权的key中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# 修改authorized_keys的权限
chmod 600 ~/.ssh/authorized_keys
3. 将authorized_keys文件以及id_rsa文件用scp命令分别复制到其他2个节点(依旧是在master上操作)
scp ~/.ssh/authorized_keys komean@192.168.105.25:~/.ssh
scp ~/.ssh/authorized_keys komean@192.168.105.35:~/.ssh
4. 测试 ssh slave1 或者ssh slave2
(五)关闭防火墙(所有节点),在开启 Hadoop 集群之前,需要关闭集群中每个节点的防火墙。有防火墙会导致 ping 得通但 telnet 端口不通,从而导致 DataNode 启动了,但 Live datanodes 为 0 的情况。
关闭防火墙
sudo service iptables stop # 关闭防火墙服务
sudo chkconfig iptables off # 禁止防火墙开机自启,就不用手动关闭了
(六)Hadoop初始化,启动所有节点
1. 启动节点(初始化别总用)
# 进入"workspace/hadoop/hadoop-2.7.7" 路径下
cd workspace/hadoop/hadoop-2.7.7 # Hadoop初始化(第一次)
# bin/hdfs namenode -format # Hadoop启动
sbin/start-all.sh # 验证
jps

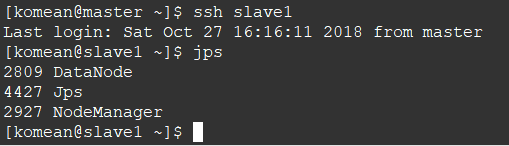
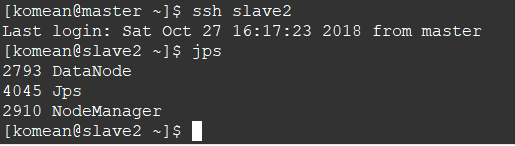
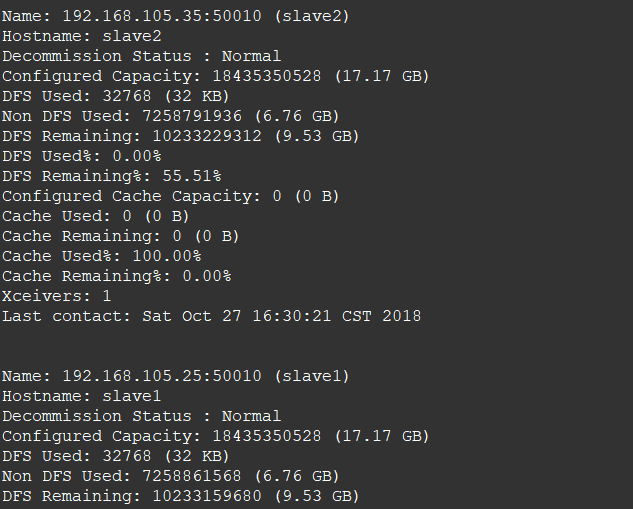
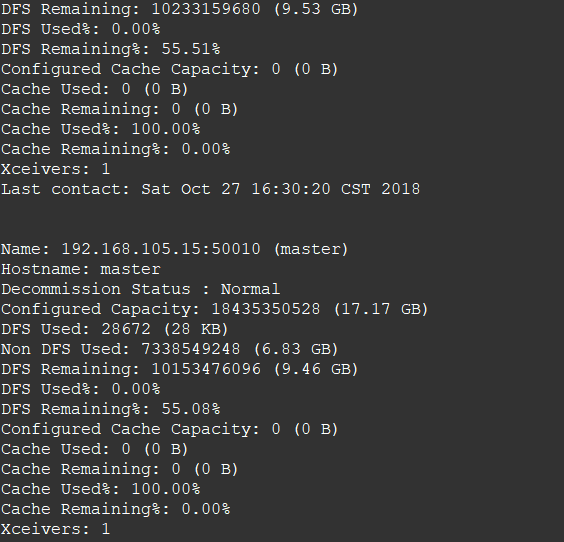
2. 查看两个从节点的情况
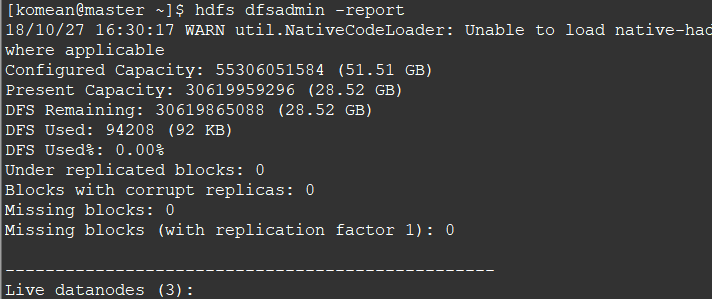
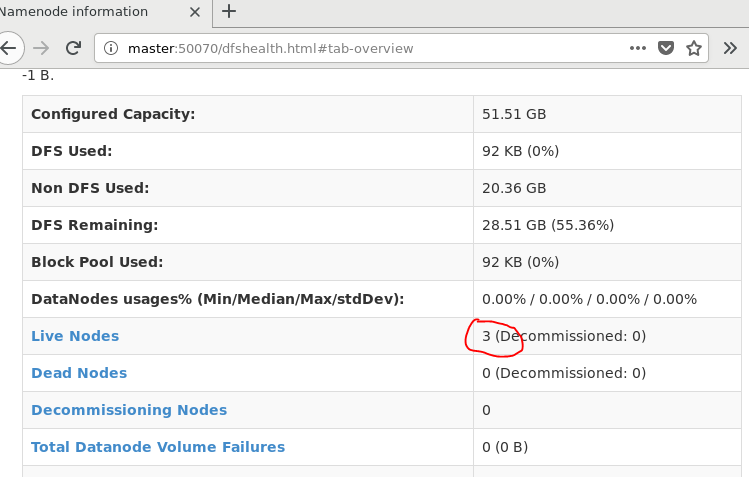
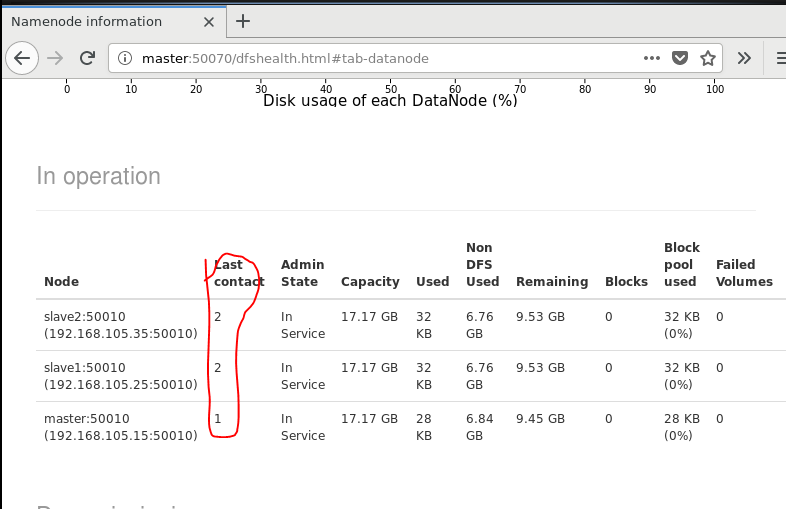
3. 查看节点信息 (或者通过Web 页面看到查看 DataNode 和 NameNode 的状态:http://master:50070/)
hdfs dfsadmin -report
通过Web 页面看到查看 DataNode 和 NameNode 的状态:http://master:50070/
Centos6.10搭建Hadoop三节点分布式的更多相关文章
- centos6.5搭建hadoop单节点
1.添加用户 groupadd hadoop useradd -d /home/hadoop -m hadoop -g hadoop passwd hadoop 修改密码 付给用户sudo权限 ...
- hadoop备战:一台x86计算机搭建hadoop的全分布式集群
主要的软硬件配置: x86台式机,window7 64位系统 vb虚拟机(x86的台式机至少是4G内存,才干开3台虚机) centos6.4操作系统 hadoop-1.1.2.tar.gz jdk- ...
- 【Hadoop环境搭建】Centos6.8搭建hadoop伪分布模式
阅读目录 ~/.ssh/authorized_keys 把公钥加到用于认证的公钥文件中,authorized_keys是用于认证的公钥文件 方式2: (未测试,应该可用) 基于空口令创建新的SSH密钥 ...
- 1.如何在虚拟机ubuntu上安装hadoop多节点分布式集群
要想深入的学习hadoop数据分析技术,首要的任务是必须要将hadoop集群环境搭建起来,可以将hadoop简化地想象成一个小软件,通过在各个物理节点上安装这个小软件,然后将其运行起来,就是一个had ...
- 快速搭建Hadoop及HBase分布式环境
本文旨在快速搭建一套Hadoop及HBase的分布式环境,自己测试玩玩的话ok,如果真的要搭一套集群建议还是参考下ambari吧,目前正在摸索该项目中.下面先来看看怎么快速搭建一套分布式环境. 准备 ...
- Windows 10 搭建Hadoop平台
一.环境配置 JDK:1.8. Hadoop下载地址(我选择的是2.7.6版本):https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/ ...
- Cassandra集群:一,搭建一个三节点的集群
环境准备 JDK1.8 http://download.oracle.com/otn/java/jdk/8u171-b11/512cd62ec5174c3487ac17c61aaa89e8/jdk-8 ...
- centos6.10搭建ELK之elasticsearch6.5.4
1.环境准备 1.1.安装java环境版本不要低于java8 # java -version java version "1.8.0_191" Java(TM) SE Runtim ...
- centos6.5搭建hadoop完整教程
https://blog.csdn.net/hanzl1/article/details/79040380 博客地址http://blog.csdn.net/pucao_cug/article/det ...
随机推荐
- 按失真类型分类整理IQA数据集:TID2013
前面已经整理了TID2008,这次整理TID2013的工作相对较简单,只需要改代码的一部分就可以了,首先我大概介绍一些TID2013. TID2013是TID2008的加强版,链接如下:http:// ...
- JMeter上传文件 点选form-data依旧失败的解决方法
转子:https://blog.csdn.net/xingyunpi/article/details/77930476 这几天一直在调用JMeter上传文件的一个接口,一直出错,在网上找到一些文章说的 ...
- 完全离线安装VSCode插件--Eslint
最近折腾了一番,总算把Eslint插件在离线的情况下安装好了.之前查了挺多,但是很多方法还是在没有完全离线的情况下进行的.之所以想完全离线安装,主要是因为我们工作的地方是禁止访问外网的,所以像直接执行 ...
- GIT版本控制系统(二)
貌似第二条有点用,还木有都验证过,贴过来再说~ 转自: http://www.cnblogs.com/lhb25/p/10-useful-advanced-git-commands.html 1. 导 ...
- codevs3027(dp)
题目链接: http://codevs.cn/problem/3027/ 题意: 中文题目诶~ 思路: dp 先给所有线段按照右端点值升序 sort 一下, 用 dp[i] 存储以第 i 条线段结尾的 ...
- cuda测试二维block的使用
#include "cuda_runtime.h" #include <stdio.h> #include <stdlib.h> #include < ...
- [linux]阿里云主机的免密码登陆安全SSH配置与思考
公司服务器使用的第三方云端服务,即阿里云,而本地需要经常去登录到服务器做相应的配置工作,鉴于此,每次登录都要使用密码是比较烦躁的,本着极速思想,我们需要配置我们的免登陆. 一 理论概述 SSH介绍 S ...
- P3356 火星探险问题
\(\color{#0066ff}{题目描述}\) 火星探险队的登陆舱将在火星表面着陆,登陆舱内有多部障碍物探测车.登陆舱着陆后,探测车将离开登陆舱向先期到达的传送器方向移动.探测车在移动中还必须采集 ...
- 最短路【bzoj1726】: [Usaco2006 Nov]Roadblocks第二短路
1726: [Usaco2006 Nov]Roadblocks第二短路 Description 贝茜把家搬到了一个小农场,但她常常回到FJ的农场去拜访她的朋友.贝茜很喜欢路边的风景,不想那么快地结束她 ...
- shell控制流程
#!/bin/bash #存储为a.sh == ] then #参数正确,返回0 else #参数错误,返回1 fi #!/bin/bash #存储为b.sh echo $? $ . ./a.sh $ ...