kylin_学习_01_kylin安装部署
一、环境准备
根据官方文档,kylin是需要运行在hadoop环境下的,如下图:

1.hadoop环境搭建
参考:hadoop_学习_02_Hadoop环境搭建(单机)
2.hbase环境搭建
3.hive环境搭建
二、kylin下载与解压
1.下载地址
前往官方 http://kylin.apache.org/download
可发现提供了一个镜像下载地址,如下:
http://mirrors.shu.edu.cn/apache/kylin/apache-kylin-2.3.0/apache-kylin-2.3.0-hbase1x-bin.tar.gz
2.下载
使用命令进行下载
wget http://mirrors.shu.edu.cn/apache/kylin/apache-kylin-2.3./apache-kylin-2.3.-hbase1x-bin.tar.gz
或者先在本地下载,然后上传服务器
3.解压
tar -zxvf apache-kylin-2.3.0-hbase1x-bin.tar.gz
三、kylin配置
1.配置环境变量
(1)编辑 profile 文件
vim /etc/profile
(2)设置 KYLIN_HOME ,并将其添加到path中。并修改 CATALINA_HOME 为 kylin 下的 tomcat
# 1. java
export JAVA_HOME=/usr/java/jdk1..0_80
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar # 2. Tomcat
#export CATALINA_HOME=/developer/apache-tomcat-7.0.73
#export CATALINA_HOME=/developer/saiku-server/tomcat
export CATALINA_HOME=/developer/apache-kylin-2.3.0-bin/tomcat # 3. Maven
export MAVEN_HOME=/developer/apache-maven-3.0. # 4. hadoop
export HADOOP_HOME=/developer/hadoop-2.6. # 5. hbase
export HBASE_HOME=/developer/hbase-1.2. # 6. hive
export HIVE_HOME=/developer/apache-hive-1.1.-bin
export HIVE_CONF_DIR=${HIVE_HOME}/conf
export HCAT_HOME=$HIVE_HOME/hcatalog # 7. kylin
export KYLIN_HOME=/developer/apache-kylin-2.3.0-bin
export hive_dependency=$HIVE_HOME/conf:$HIVE_HOME/lib/*:$HCAT_HOME/share/hcatalog/hive-hcatalog-core-1.1.0.jar #Path
# 1. big data
export PATH=$KYLIN_HOME/bin:$PATH
export PATH=$HIVE_HOME/bin:$HBASE_HOME/bin:$HADOOP_HOME/bin:$PATH
export PATH=$MAVEN_HOME/bin:$CATALINA_HOME/bin:$JAVA_HOME/bin:$PATH
export LC_ALL=en_US.UTF-
2.配置 kylin.sh
在文件开始的地方,添加如下配置:
export KYLIN_HOME=/developer/apache-kylin-2.3.0-bin
export HBASE_CLASSPATH_PREFIX=$CATALINA_HOME/bin/bootstrap.jar:$CATALINA_HOME/bin/tomcat-juli.jar:$CATALINA_HOME/lib/*:$hive_dependency:$HBASE_CLASSPATH_PREFIX
四、启动kylin
1.确保 hadoop、hbase已经启动
(1)启动hadoop
进入hadoop 的 sbin 目录,执行
./start-all.sh
(2) 启动 hbase
进入hbase的 bin 目录,执行
./start-hbase.sh
2.启动 kylin
进入 kylin 的 bin 目录,执行
./kylin.sh start
即可启动kylin
3.访问kylin管理界面
启动kylin之后,浏览器访问:http://your_hostname:7070/kylin。输入用户名 ADMIN 、密码 KYLIN ,即可登录
例如:
192.168.1.102:7070/kylin
五、配置hive数据源
1.配置数据源
(1)依次选择 Model -> Data Source -> Load Hive Table
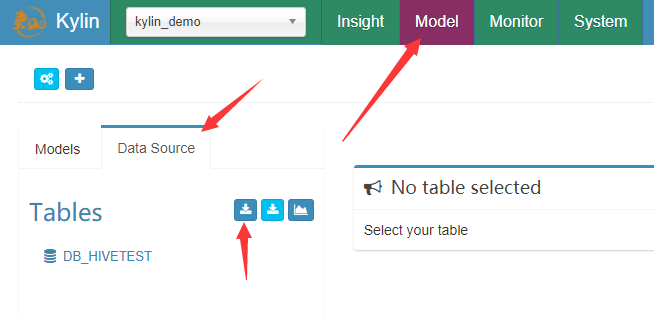
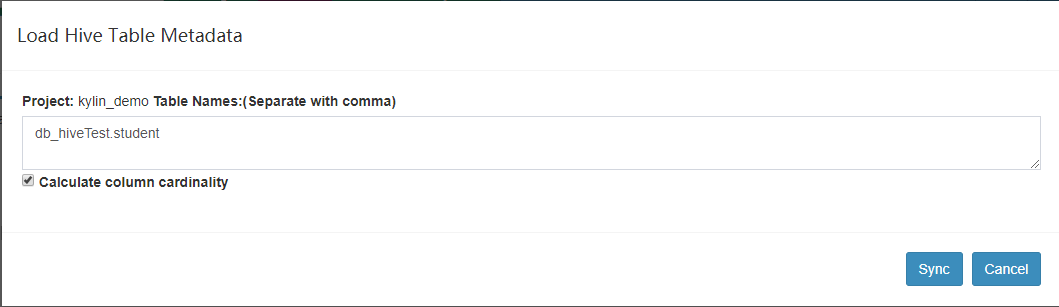
(2)输入 hive 中数据库的表名格式为: 数据库名.数据表名
如:db_hiveTest.student ,然后点击Sync即可。
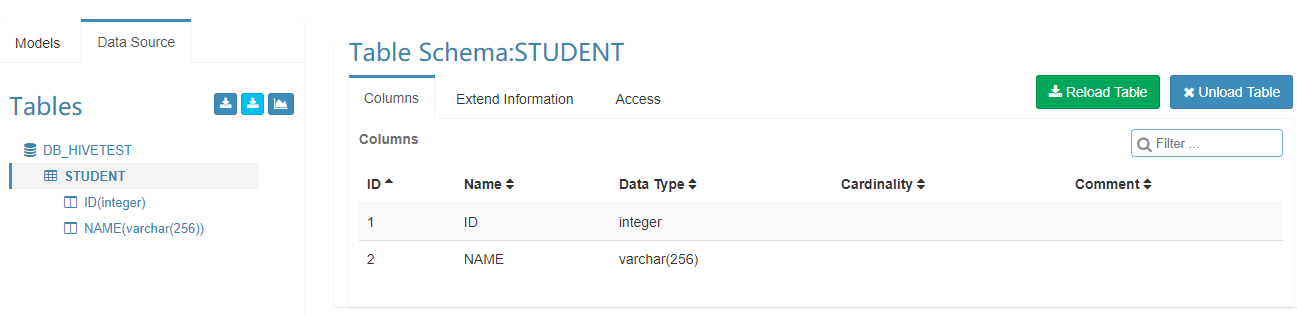
添加成功后,效果如下图:
五、参考资料
1.官方安装向导 :
Installation Guide( http://kylin.apache.org/cn/docs23/install/index.html )
2.HDP下载地址:
https://zh.hortonworks.com/downloads/
kylin_学习_01_kylin安装部署的更多相关文章
- Redis学习01_redis安装部署(centos)
原文: http://www.cnblogs.com/herblog/p/9305668.html Redis学习(一):CentOS下redis安装和部署 1.基础知识 redis是用C语言开发的 ...
- Robot Framework入门学习1 安装部署详解
安装注意: 目前Robot framework-ride不支持python3,安装时请下载python2.7版本. Robot Framework安装时出现了一点小问题,网上没有找到直接的介绍,现将安 ...
- 大数据学习——flume安装部署
1.Flume的安装非常简单,只需要解压即可,当然,前提是已有hadoop环境 上传安装包到数据源所在节点上 然后解压 tar -zxvf apache-flume-1.6.0-bin.tar.gz ...
- 大数据学习——hive安装部署
1上传压缩包 2 解压 tar -zxvf apache-hive-1.2.1-bin.tar.gz -C apps 3 重命名 mv apache-hive-1.2.1-bin hive 4 设置环 ...
- 【Spark学习】Spark 1.1.0 with CDH5.2 安装部署
[时间]2014年11月18日 [平台]Centos 6.5 [工具]scp [软件]jdk-7u67-linux-x64.rpm spark-worker-1.1.0+cdh5.2.0+56-1.c ...
- Hadoop学习------Hadoop安装方式之(二):伪分布部署
要想发挥Hadoop分布式.并行处理的优势,还须以分布式模式来部署运行Hadoop.单机模式是指Hadoop在单个节点上以单个进程的方式运行,伪分布模式是指在单个节点上运行NameNode.DataN ...
- 【Zookeeper学习】Zookeeper-3.4.6安装部署
[时间]2014年11月19日 [平台]Centos 6.5 [工具] [软件]jdk-7u67-linux-x64.rpm zookeeper-3.4.6.tar.gz [步骤] 1. 准备条件 ( ...
- Elasticsearch学习之ElasticSearch 5.0.0 安装部署常见错误或问题
ElasticSearch 5.0.0 安装部署常见错误或问题 问题一: [--06T16::,][WARN ][o.e.b.JNANatives ] unable to install syscal ...
- 大数据技术之_13_Azkaban学习_Azkaban(阿兹卡班)介绍 + Azkaban 安装部署 + Azkaban 实战
一 概述1.1 为什么需要工作流调度系统1.2 常见工作流调度系统1.3 各种调度工具特性对比1.4 Azkaban 与 Oozie 对比二 Azkaban(阿兹卡班) 介绍三 Azkaban 安装部 ...
随机推荐
- web应用的负载均衡、集群、高可用(HA)解决方案
看看别人的文章: 1.熟悉几个组件 1.1.apache —— 它是Apache软件基金会的一个开放源代码的跨平台的网页服务器,属于老牌的web服务器了,支持基于Ip或者域名的虚拟主机,支持代 ...
- 最小生成树——Prim(普利姆)算法
[0]README 0.1) 本文总结于 数据结构与算法分析, 源代码均为原创, 旨在 理解Prim算法的idea 并用 源代码加以实现: 0.2)最小生成树的基础知识,参见 http://blog. ...
- linux使用rsync+inotify-tools+ssh实现文件实时同步
假设某服务器架构中有两台web服务器(IP为192.168.1.252和192.168.1.254),一台代码更新发布服务器(IP为192.168.1.251),需要同步的目录是/data/www/, ...
- 转载 jenkins执行selenium 测试 浏览器不显示解决方法
原文地址: http://blog.csdn.net/achang21/article/details/45096003 The web browser doesn't show while run ...
- iOS开发---业务逻辑
iOS开发---业务逻辑 1. 业务逻辑 iOS的app开发的最终目的是要让用户使用, 用户使用app完成自己的事就是业务逻辑, 业务逻辑的是最显眼开发工作.但是业务逻辑对于开发任务来说, 只是露 ...
- (转)linux设备驱动之USB数据传输分析 一
三:传输过程的实现说到传输过程,我们必须要从URB开始说起,这个结构的就好比是网络子系统中的skb,好比是I/O中的bio.USB系统的信息传输就是打成URB结构,然后再过行传送的.URB的全称叫US ...
- Linux命令提示符的配置
Linux登录过程中加载配置文件顺序: /etc/profile → /etc/profile.d/*.sh → ~/.bash_profile → ~/.bashrc → [/etc/bashrc] ...
- 串 2016Vijos省选集训 day3[AC自动机]
1.串(string.c/.cpp/.pas) 限时1s,内存限制256MB,20个测试点 [题目描述] 兔子们在玩字符串的游戏.首先,它们拿出了一个字符串集合S,然后它们定义一个字符串为“好”的,当 ...
- iOS线程浅析
一.线程概述 1. iOS里面的线程按种类可分为同步线程和异步线程.同步线程指调用同步线程的地方必须等到同步线程运行完成才干够继续向下运行.而调用异步线程的地方则在运行完调用异步线程的语句后就能够继续 ...
- apche安装教程
从Apache官网下载windows安装版的Apache服务器了, 现在分享给大家. 1 进入apache服务器官网http://httpd.apache.org/,这里我们以下载稳定版的 htt ...