大数据学习——hive安装部署
1上传压缩包

2 解压
tar -zxvf apache-hive-1.2.1-bin.tar.gz -C apps
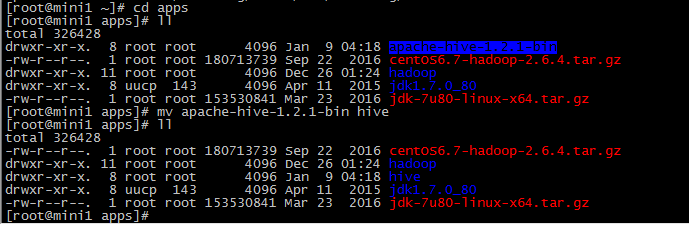
3 重命名
mv apache-hive-1.2.1-bin hive
4 设置环境变量
vi /etc/profile
expert HIVE_HOME=/root/apps/hive
export PATH=$PATH:$HIVE_HOME/bin

5 启动hive
cd apps/hive
bin/hive

出现上面的问题是因为版本不兼容
解决一下版本不兼容问题:替换 apps/hadoop/share/hadoop/yarn/lib中的老版本jline 为hive的lib中的jline-2.12.jar
命令
cd apps/hadoop/share/hadoop/yarn/lib
rm -rf jline-0.9.94.jar
cp /root/apps/hive/lib/jline-2.12.jar /root/apps/hadoop/share/hadoop/yarn/lib

启动hive

6 测试
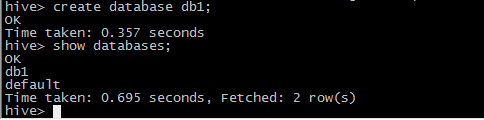
数据默认存储在derby数据库中
缺点:多个地方安装hive后,每一个hive是拥有一套自己的元数据,大家的库、表就不统一;
元数据库mysql版:
1、解压
2、修改配置文件
3、加载mysql数据驱动包
mysql安装可参考:https://www.cnblogs.com/feifeicui/p/10088529.html
7 修改配置文件,使用mysql数据库存储数据
新建一个文件
vi hive-site.xml
添加内容
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property> <property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property> <property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property> <property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
</configuration>
修改文件名字
mv hive-env.sh.template hive-env.sh
设置hadoop环境变量
vi hive-env.sh

启动hive
报错
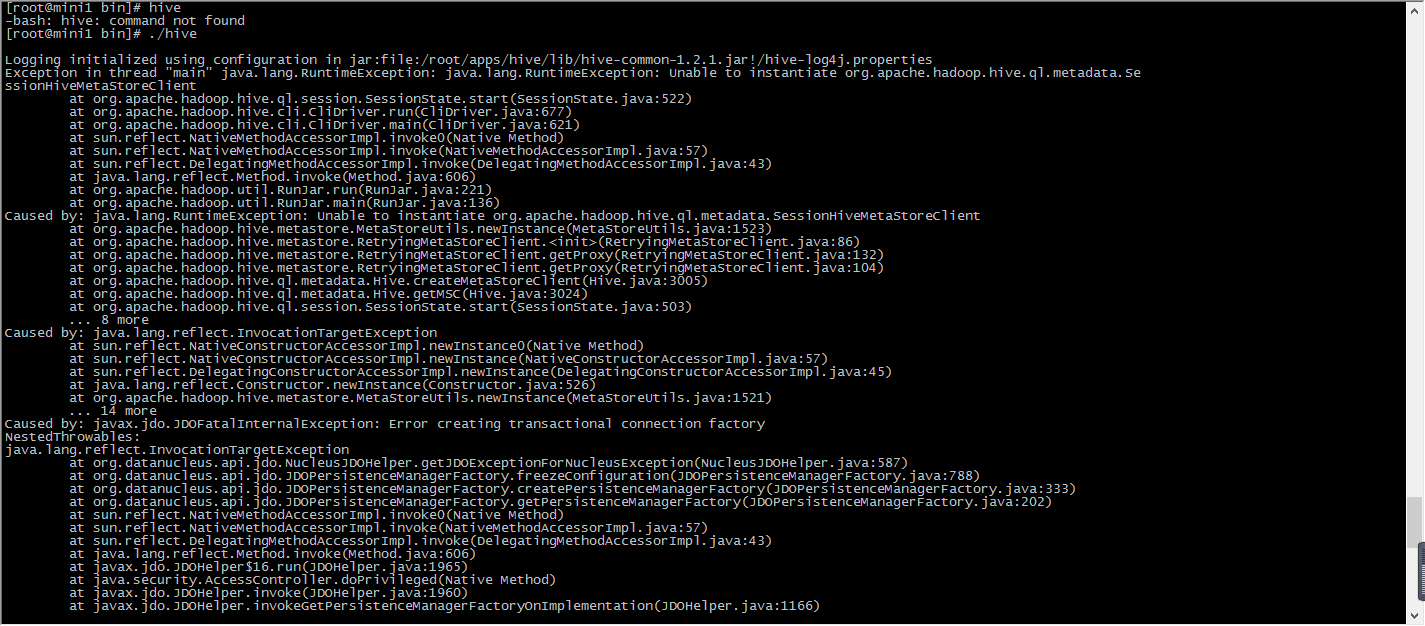
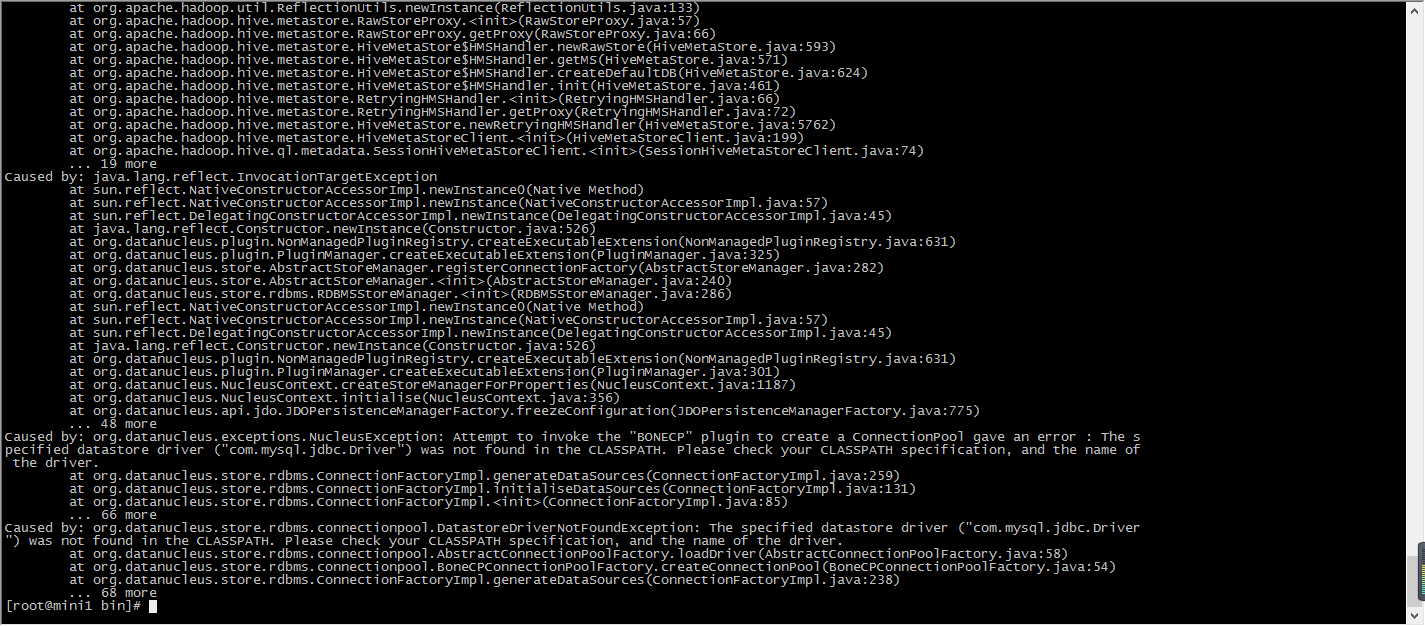
原因是少了数据库驱动
上传驱动jar
启动hive

测试

大数据学习——hive安装部署的更多相关文章
- 大数据学习——flume安装部署
1.Flume的安装非常简单,只需要解压即可,当然,前提是已有hadoop环境 上传安装包到数据源所在节点上 然后解压 tar -zxvf apache-flume-1.6.0-bin.tar.gz ...
- 大数据学习——hive基本操作
1 建表 create table student(id int,name string ,age int) row format delimitedfields terminated by ','; ...
- 大数据学习——hive数据类型
1. hive的数据类型Hive的内置数据类型可以分为两大类:(1).基础数据类型:(2).复杂数据类型2. hive基本数据类型基础数据类型包括:TINYINT,SMALLINT,INT,BIGIN ...
- 大数据学习——hive函数
1 内置函数 测试各种内置函数的快捷方法: 1.创建一个dual表 create table dual(id string); 2.load一个文件(一行,一个空格)到dual表 3.select s ...
- 大数据学习——hive的sql练习
1新建一个数据库 create database db3; 2创建一个外部表 --外部表建表语句示例: create external table student_ext(Sno int,Sname ...
- 大数据学习——hive显示命令
show databases; desc t_partition001; desc extended t_partition002; desc formatted t_partition002; !c ...
- 大数据学习——hive的sql练习题
ABC三个hive表 每个表中都只有一列int类型且列名相同,求三个表中互不重复的数 create table a(age int) row format delimited fields termi ...
- 大数据学习——hive数仓DML和DDL操作
1 创建一个分区表 create table t_partition001(ip string,duration int) partitioned by(country string) row for ...
- 大数据学习——hive使用
Hive交互shell bin/hive Hive JDBC服务 hive也可以启动为一个服务器,来对外提供 启动方式,(假如是在itcast01上): 启动为前台:bin/hiveserver2 启 ...
随机推荐
- 题解报告:hdu 1520 Anniversary party(树形dp入门)
Problem Description There is going to be a party to celebrate the 80-th Anniversary of the Ural Stat ...
- Suricata的性能
不多说,直接上干货! 见官网 https://suricata.readthedocs.io/en/latest/performance/index.html Docs » 7. Performanc ...
- AJPFX总结Java 程序初始化过程
觉得Core Java在Java 初始化过程的总体顺序没有讲,只是说了构造器时的顺序,作者似乎认为路径很多,列出来比较混乱.我觉得还是要搞清楚它的过程比较好.所以现在结合我的学习经验写出具体过程: 过 ...
- 如何优化APK的大小
项目使用AS打出的包明显比Eclipse打出的包要大一些,还是蛮费解.于是百度了一翻, 原来Eclipse使用的proguard能够遍历所有的java代码,把无用的代码去掉才生成dex文件,同 时对r ...
- 6 Specialzed layers 特殊层 第二部分 读书笔记
CAGradientLayer CAGradientLayer is used to generate a smooth gradient between two or more colors. ...
- sqlserver2012 offset
/* * Hibernate, Relational Persistence for Idiomatic Java * * License: GNU Lesser General Public Lic ...
- Java遍历HashMap并修改(remove)
遍历HashMap的方法有多种,比如通过获取map的keySet, entrySet, iterator之后,都可以实现遍历,然而如果在遍历过程中对map进行读取之外的操作则需要注意使用的遍历方式和操 ...
- sql server 全部错误号详释
0 操作成功完成. 1 功能错误. 2 系统找不到指定的文件. 3 系统找不到指定的路径. 4 系统无法打开文件. 5 拒绝访问. 6 句柄无效. 7 存储控制块被损坏. 8 存储空间不足,无法处理此 ...
- Python 风格规范
分号 不要在行尾加分号, 也不要用分号将两条命令放在同一行. 行长度 每行不超过80 个字符 例外: 如果使用Python 2.4 或更早的版本, 导入模块的行可能多于80 个字符. Pyth ...
- Java之流水号生成器实现
参考:https://www.jianshu.com/p/331b872e9c8f 1.建立一张存放的表 CREATE TABLE `sys_serial_number` ( `id` bigint( ...